《架构师》专题
-
 高并发下如何设计数据库架构?
高并发下如何设计数据库架构?主要内容:一、用一个创业公司的发展作为背景引入,二、多台服务器分库支撑高并发读写,三、大量分表来保证海量数据下的查询性能,四、读写分离来支撑按需扩容以及性能提升,五、高并发下的数据库架构设计总结这篇文章,我们来聊一下对于一个支撑日活百万用户的高并系统,他的数据库架构应该如何设计? 看到这个题目,很多人第一反应就是: 分库分表啊! 但是实际上,数据库层面的分库分表到底是用来干什么的,他的不同的作用如何应对不同的场景,我觉得很多同学可能都没搞清楚。 一、用一个创业公司的发展作为背景引入 假如我们现在
-
 聊聊缓存架构是如何被“击垮”的?
聊聊缓存架构是如何被“击垮”的?主要内容:一、为什么要用缓存集群,二、20万用户同时访问一个热点缓存的问题,三、基于流式计算技术的缓存热点自动发现,四、动加载为JVM本地缓存,五、限流熔断保护,六、本文总结一、为什么要用缓存集群 这篇文章,咱们来聊聊热点缓存的架构优化问题。 其实使用缓存集群的时候,最怕的就是热key、大value这两种情况,那啥叫热key大value呢? 简单来说,热key,就是你的缓存集群中的某个key瞬间被数万甚至十万的并发请求打爆。 大value,就是你的某个key对应的value可能有GB级的大小,导
-
react.js - nextjs适合前后端分离的架构吗?
nextjs适合前后端分离的架构吗? 刚学nextjs 有个疑问 nextjs适合前后端分离的架构吗,我看官网和一些教程都提倡直接在服务端组件里操作数据库。如果已经有了写好的api服务,可以直接在服务端组件里去用axios请求api服务吗
-
 26日常实习 百度搜索架构二面
26日常实习 百度搜索架构二面二面主管面:聊了很多,又给人聊乐了 1h redis的优缺点 redis穿透三件套 (想起来还有个题目) 怎么对比两个超级大的文本,每一行都是string,对比拿到一样的内容 答:每个拆10片,老式转盘拨号电话那种方式,转一圈,比10次就能得到结果了 追问:你用过分布式相关的内容吗 答:大二做的大数据竞赛拿了省一等奖,用了hadoop分布式存储,但是当时是mapreduce拿词频,这个好像不合适。
-
 快手客户端平台架构日常实习
快手客户端平台架构日常实习一面1h:5.14 上来先问,看你是打acm的,你队名是什么,好像遇到ap面试官了 网络: 浏览器输入url会发生什么(常规八股) TCP如何保证可靠,流量控制(超时重传,滑动窗口机制) 集合: 说一下ArrayList扩容,说一下泛型 你刚才说java是伪泛型,cpp泛型怎么实现的(泛型模板,编译时生成对应代码) 多线程: 一写多读有什么问题(可见性问题) java中如何解决一写多读问题(答了h
-
 字节视频架构c++日常实习一面
字节视频架构c++日常实习一面怀着挂了的心情写的面经,写到一半居然约二面时间了 时长:40min 八股: lambda表达式 还有那些可调用的对象? 生产者消费者,信号量的使用 商品队列空时,消费者和生产者会发生什么 互斥同步的方法 进程间通信方式,自己用的最多的是什么 项目: Socket编程,聊天室,不细说了 场景设计问题,UDP设计安全可靠的文件传输 代码考核: 二分查找 自己写测试用例确保代码正确性 #字节实习生#
-
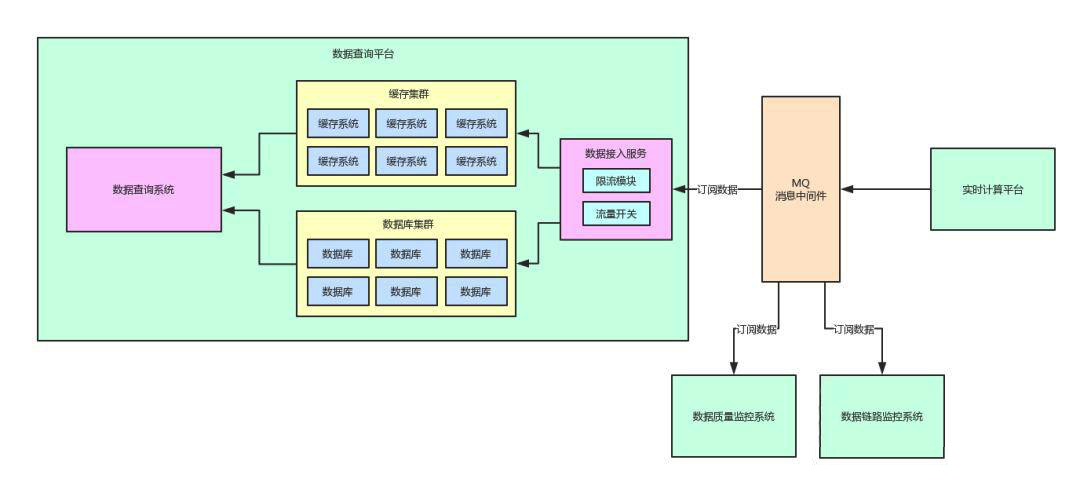 梳理出来:架构师的工作内容竟有这么多
梳理出来:架构师的工作内容竟有这么多主要内容:一、多系统订阅数据回顾,二、核心数据的监控系统,三、电商库存数据如何监控,四、数据计算链路追踪,五、百亿流量下的数据链路追踪,六、自动化数据链路分析,七、下篇预告一、多系统订阅数据回顾 我们先来看一张图,是之前讲系统架构解耦的时候用的一张图。 好!通过上面这张图,我们来回顾一下之前做了系统解耦之后的一个架构图。 其实,实时计算平台会把数据计算的结果投递到一个消息中间件里。 然后,数据查询平台、数据质量监控系统、数据链路追踪系统,各个系统都需要那个数据计算结果,都会去订阅里面的数据。 这
-
Spark-将具有不同架构(列名称和序列)的DataFrame合并/合并到具有Master通用架构的DataFrame
问题内容: 我尝试通过df.schema()将模式作为通用模式并将所有CSV文件加载到该模式,但是对于分配的模式失败,其他CSV文件的标题不匹配 任何建议,将不胜感激。如函数或Spark脚本中一样 问题答案: 据我了解。您想要合并/合并具有不同架构的文件(尽管是一个主架构的子集)..我编写了此函数UnionPro,我认为它很适合您的要求- 编辑 -添加了Pyspark版本 这是它的样本测试- 输出
-
使用gradle构建框架使用log4j包构建应用程序时出错
我使用gradle创建了一个简单的java项目,从“gradle init——类型java应用程序”开始。 主java文件的内容-“App.java”: 文件“build.gradle”的内容: gradle似乎已成功下载log4j jar文件: 在~/中有一组log4j jar/pom文件。gradle目录。当我尝试生成时,出现以下生成错误: 我对gradle/java是新手。任何帮助都将不胜感
-
使用默认架构注册表客户端而不是Avro架构注册表客户端解决Spring Cloud Stream问题
我们正在使用Kafka和Spring Cloud Stream,我们需要连接到Spring Boot组件中的Confluent Schema Registry,请参阅https://github.com/donalthurley/KafkaConsumeScsAndConfluent. 我们添加了以下配置来创建所需的 ConfluentSchemaRegistryClient bean see h
-
使用AbstractRoutingDataSource动态更改数据库架构/目录
问题内容: 根据本文,您可以使用Spring Framework中的AbstractRoutingDataSource来动态更改应用程序使用的数据源。 但是,使用的数据源是通过配置定义的,而不是通过编程定义的。有没有一种方法可以配置要在运行时使用的数据源? 该解决方案的可扩展性如何,即数据源数量上的限制是什么? 谢谢! 问题答案: 我已经为30个数据源实现了这种方法,并且它们当前正在生产环境中运行
-
PACT 在微服务架构中的用途是什么?
本文向大家介绍PACT 在微服务架构中的用途是什么?相关面试题,主要包含被问及PACT 在微服务架构中的用途是什么?时的应答技巧和注意事项,需要的朋友参考一下 PACT 是一个开源工具,允许测试服务提供者和消费者之间的交互,与契约隔离,从而提高微服务集成的可靠性。 在微服务中的用法: 用于在微服务中实现消费者驱动的契约。 测试微服务的消费者和生产者之间的消费者驱动的契约。
-
在Spring Boot中创建多个数据源和架构
问题内容: 我正在使用Spring Boot。我终于设法设置了两个数据源,但是现在我面临另一个问题。 有两个数据源的地方似乎无法在我的Spring Boot应用程序中工作,请立即执行此操作 我无法为每个数据源选择自动创建策略。我宁愿为数据源一创建模式,而仅在第二个DB中使用数据源为二的模式。 任何机构都知道如何解决这些问题?注意如果可能的话,我不想完全放弃自动配置。我什至还不知道,hibernat
-
触发以捕获服务器中的架构更改
问题内容: 是否可以实现类似以下触发器的内容 但是在整个服务器上。我的想法是捕获服务器中所有数据库之间的所有架构更改。 就即时消息而言,这在SQL Server 2005中是不可能的,但是我想知道是否有人能像这样工作。我想避免必须在每个数据库中实现触发器。 问题答案: 是的,SQL Server 2005引入了“ DDL触发器”,请在SQL Team 上阅读一篇出色的文章。 本文很好地显示了它们是
-
通过架构以部署用户身份激活virtualenv
问题内容: 我想在本地运行我的结构脚本,这将依次登录到我的服务器,切换用户以进行部署,激活项目.virtualenv,这将把dir更改为项目并发出git pull。 我通常使用来自virtualenvwrapper的workon命令,该命令提供激活文件,后激活文件会将我放置在项目文件夹中。在这种情况下,似乎因为结构是在shell中运行的,所以控制权移交给了结构,所以我不能将内置的bash源使用到’