《多线程》专题
-
Java:在多个线程之间共享一个变量
背景:我正在并行运行自动化测试。使用pom.xml中的分叉,多个浏览器在相同数量的线程中启动,即1个浏览器是1个线程。 中的下面插件创建了与线程(fork)计数相等数量的。 所有这些类都同时并行执行。因此,似乎每当我创建或时,每个线程都会创建自己的这些,因此跨多个线程共享变量的概念是不起作用的。 我只想让一个线程访问“准备测试数据”函数,并将<code>标志 我正在按照教程https://www.
-
我们如何以循环方式使用多线程?
我想以多线程方式阅读10个邮件帐户的未读邮件。 但是如果线程池大小为5,那么将使用线程池中的5个线程。每个线程将读取一个邮件帐户。因此,一旦Thread_1读取了第一个邮箱,它应该会读取mailbox_6。那么线程2将读取mailbox_7。 当所有邮件帐户都被读取一次后,循环将从第一个邮件帐户开始。 我们如何在java中做到这一点?
-
使用Spring批处理的多线程数据处理
我使用的是Spring Batch 2.1.8。释放我有一个文件,它由一些头信息和一些需要处理的记录组成。 我有一个使用面向块处理的步骤。该步骤包含ItemReader和ItemWriter的实现。ItemReader实现是线程安全的,而ItemWriter不是。 我想在处理(或写入)任何记录之前使用标题信息。在继续使用面向块的处理时,如何确保这一点? 建议的解决方案:一种解决方案可以是编写一个预
-
如何在多线程应用中高效使用RestTemplate?
我正在使用作为我的一个库中的。我不确定我是否在多线程环境中正确地使用它,因为我的库在多线程环境中会在非常大的负载下使用,所以它必须非常快。 下面是我的DataClient类: 这就是我要打电话获取数据的方式: 现在我的问题是--我不确定我是否正确地将与一起使用。这里是否需要以及? 我的主要目标是在多线程环境中高效地使用。因为我的库将在非常大的负荷下使用,所以它必须非常快。在重载下,我看到了大量的T
-
每个条件唤醒多个线程工作一次
-
多线程 Java 应用程序中的数据缓冲
我有一个多线程应用程序,它有一个生产者线程和几个消费者线程。数据存储在一个共享的线程安全集合中,当缓冲区中有足够的数据时,就刷新到数据库中。 来自爪哇文档 - 一个队列,它还支持在检索元素时等待队列变为非空,并在存储元素时等待队列中的空间变为可用。 检索并删除此队列的头部,如有必要,请等待元素可用。 我的问题是- < li >是否有另一个集合具有E[] take(int n)方法?即阻塞队列等待,
-
simpMessagingTemplate convertAndSendToUser许多等待线程阻塞其他功能
我们在应用程序中使用了Stomp、SpringBoot和WebSockets。服务器应用程序执行以下操作:1)生成要推送给用户的消息;2)接受WebSocket连接;3)将消息推送给ActiveMQ stomp Broker。线程转储显示了大量与simpMessagingTemplate convertAndSendToUser API调用相关联的等待线程。 应用程序的两个实例在云中运行。该应用程
-
如何在kafka 0.9.0中使用多线程消费者?
Kafka的doc给出了一种方法,大约用以下描述: 每个线程一个消费者:一个简单的选择是为每个线程提供自己的消费者 我的代码: 但它不起作用,引发了一个异常: JAVAutil。ConcurrentModificationException:KafkaConsumer对于多线程访问不安全 此外,我还阅读了Flink(一个用于分布式流和批处理数据的开源平台)的源代码。Flink使用多线程消费程序与我
-
将Spring Transaction与多个线程一起使用[重复]
这个问题我已经被问过很多次了,而且一直困扰着我。 我们有一个服务类,有3个DAO方法更新3个不同的表。这种设计使得对所有三个表的更新都应该是原子的。我有3个线程分别调用我的服务类,对于每个DAO方法更新,如何使用Spring事务或任何事务管理器将所有线程(操作)保持在单个事务下??有任何关于文档的想法或指针吗??谢谢
-
以2KB的块读取python中的多线程文件。
我必须以2KB的块读取文件,并在这些块上执行一些操作。现在我实际上陷入困境的地方是,当数据需要线程安全时。根据我在在线教程和 StackOverflow 答案中看到的内容,我们定义了一个工作线程,并重写了它的运行方法。run 方法使用队列中的数据,我们将其作为参数传递,并且包含实际数据。但是要用数据加载该队列,我必须按顺序遍历文件,这消除了并行性。我希望多个线程以并行方式读取文件。因此,我必须仅在
-
多线程如何在Cadence/Temporal工作流中工作?
在Cadence/Temoral工作流编程中: < li >不允许使用本机线程库。例如,在Java中,线程必须通过< code>Async.procedure或< code>Async.function创建,而在Golang中,线程必须通过< code>workflow创建。去吧。那为什么呢? < li >有没有类似使用本机线程的竞争条件?例如,为了线程安全,应该使用< code>Hashtabl
-
第5章 多线程 - JDK8对并发的新支持
摘要: 本系列基于炼数成金课程,为了更好的学习,做了系列的记录。 本文主要介绍: 1. LongAdder 2. CompletableFuture 3. StampedLock 1. LongAdder 和AtomicLong类似的使用方式,但是性能比AtomicLong更好。 LongAdder与AtomicLong都是使用了原子操作来提高性能。但是LongAdder在AtomicLong的基
-
第10章 多线程程序的测试和调试
本章主要内容 并发相关的错误 定位错误和代码审查 设计多线程测试用例 多线程代码的性能 目前为止,我们了解如何写并发代码——可以使用哪些工具,这些工具应该如何使用。不过,在软件开发中重要的一部分我们还没有提及:测试与调试。如果你希望阅读完本章后就能很轻松的去调试并发代码,本章无法满足你的预期。 测试和调试并发代码比较麻烦。除了对一些重要问题的思考,我也会展示一些技巧让测试和调试变得简单一些。 测试
-
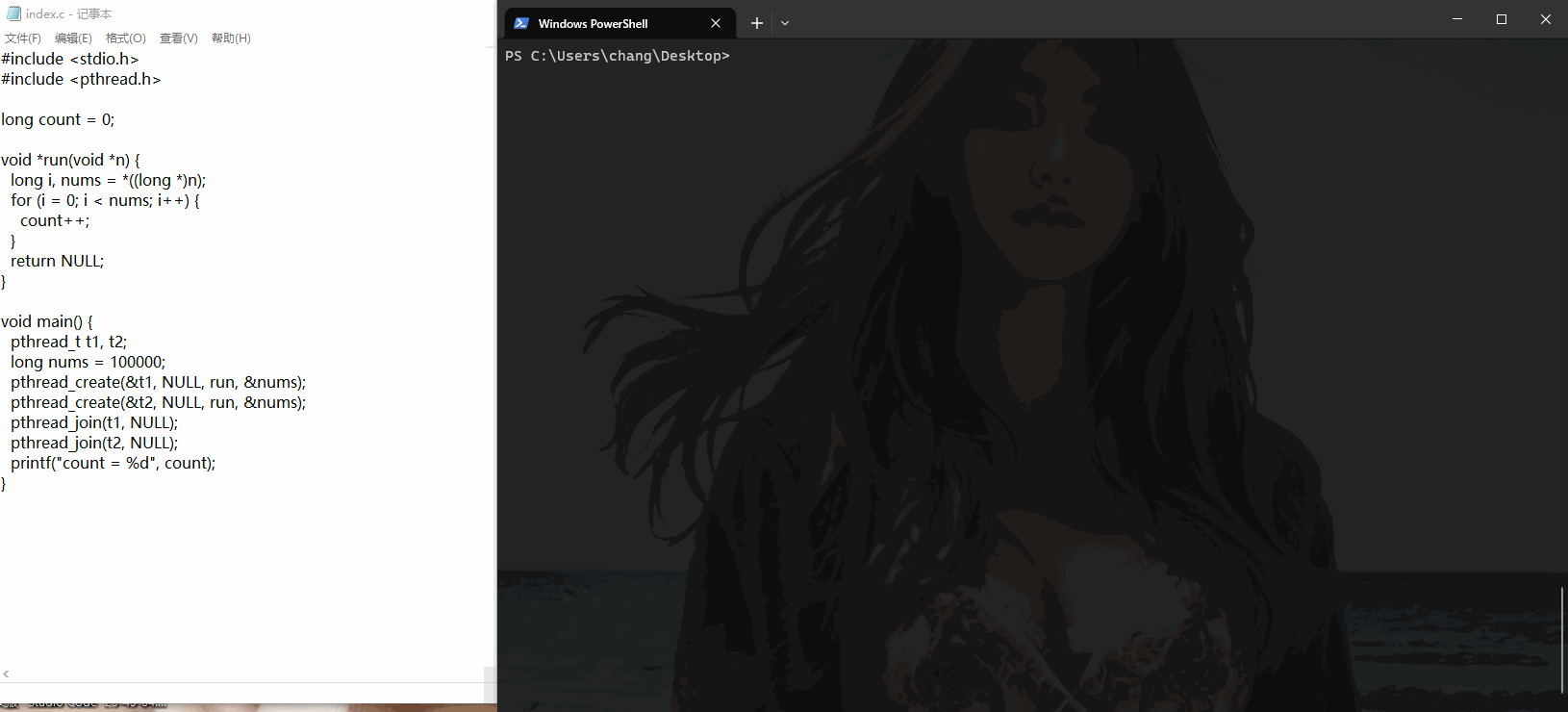 c - 这段多线程代码应该怎么理解?
c - 这段多线程代码应该怎么理解?如果我把 nums 设置为 10000,那么每次都准确输出 20000。或者设置的值比 10000 要少时也能准确输出。如果我把 nums 设置为 100000,那么每次输出的值都好像是随机的,范围在 100000 到 200000 之间。 如果是因为线程之间执行顺序的问题导致输出不确定,那为什么当值为 10000 时输出的值是比较确定的?
-
线程与线程
问题内容: Python中的和模块之间有什么区别? 问题答案: 在Python 3中,已重命名为。它是用于实现的基础结构代码,普通的Python代码不应该靠近它。 公开了底层操作系统级别流程的原始视图。这几乎绝不是您想要的,因此在Py3k中重命名以表明它实际上只是实现细节。 添加了一些额外的自动记帐功能,以及一些便捷实用程序,所有这些使它成为标准Python代码的首选。