《innodb》专题
-
如何锁定尚不存在的InnoDB行?
如何保证我可以搜索我的数据库中是否存在用户名,然后将该用户名作为新行插入数据库,而不会在和语句之间进行任何拦截? 几乎就像我锁定了一个不存在的行。我想用用户名“Foo”锁定不存在的行,这样我现在可以检查它是否存在于数据库中,如果它还不存在,就可以将它插入数据库中,而不会出现任何中断。 我知道使用< code>LOCK IN SHARE MODE和< code>FOR UPDATE是存在的,但是据我
-
可重复读取和可序列化的MySQL InnoDB实现之间的实际区别是什么
根据 SQL 标准,可重复读取应防止模糊读取和脏读,而可序列化还应防止幻像读取。 根据MySQL文档: 默认情况下,InnoDB以可重复读取事务隔离级别运行。在这种情况下,InnoDB使用下一键锁进行搜索和索引扫描,这可以防止幻像行(参见14.2.2.5的“使用下一键锁避免幻像问题”一节)。 那么,如果可重复读取也可以防止幻像读取,那么序列化可以提供什么回报呢? Serializable是否可以防
-
Amazon EC2,mysql中止启动,因为InnoDB: mmap (x bytes)失败;错误12
我在EC2上有一个基于此的微实例服务器 mysql服务器经常出现故障,这已经是第三次了。日志只显示 什么是真正的<代码>失败;errno 12?我怎样才能给更多的空间/内存或任何需要的东西来解决这个问题。 我每次都通过重启整个系统,删除所有日志,重启mysql服务器来解决这个问题。但是我知道我的配置有问题。 我的my.cnf如下:
-
批量修改Mysql表引擎为InnoDB的方法
一般批量修改MYSQL中某表的数据库引擎可以利用官方工具mysql_convert_table_format来实现, 这里指的是不使用其他工具仅用shell的方法来实现。(以下例子效果是将数据库shop中所有引擎不为InnoDB的表修改为使用InnoDB引擎)[ 查看表引擎的语句:show create table tableName; ],其实核心关键点是这条语句: alert table ta
-
15.2. InnoDB存储引擎
15.2.1. InnoDB概述 15.2.2. InnoDB联系信息 15.2.3. InnoDB配置 15.2.4. InnoDB启动选项 15.2.5. 创建InnoDB表空间 15.2.6. 创建InnoDB表 15.2.7. 添加和删除InnoDB数据和日志文件 15.2.8. InnoDB数据库的备份和恢复atabase 15.2.9. 把InnoDB数据库移到另一台机器上 15.2.
-
 innodb-buffer pool
innodb-buffer pool主要内容:1.如何管理与淘汰缓冲池,使得性能最大化呢,2.InnoDB 是以什么算法,来管理这些缓冲页呢?,3.总结应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存 (cache) 里,避免每次都去访问数据库。操作系统,会有缓冲池 (buffer pool) 机制,避免每次访问磁盘,以加速数据的访问。MySQL 作为一个存储系统,同样具有缓冲池 (buffer pool) 机制,以避免每次查询数据都进行磁盘 IO。 Buffer pool中存放的是缓存表数据与索引数据,把磁盘上的
-
 innodb是如何存数据的
innodb是如何存数据的主要内容:1.磁盘or内存,2.数据页,3.用户记录,4.最大和最小记录,5.页目录,6.文件头部和尾部,7.页头部,8.总结innodb底层是如何存储数据的 1.磁盘or内存 1.1 磁盘 数据对系统来说是非常重要的东西,比如:用户的身份证、手机号、银行号、会员过期时间、积分等等。一旦丢失,会对用户造成很大的影响。 把数据存在磁盘上。 但是IO请求是比较耗时的操作,如果频繁的进行IO请求势必会影响数据库的性能。 1.2 内存 内存可以存储一些用户数据,但无法存储所有的用户数据,因为如果数据量太
-
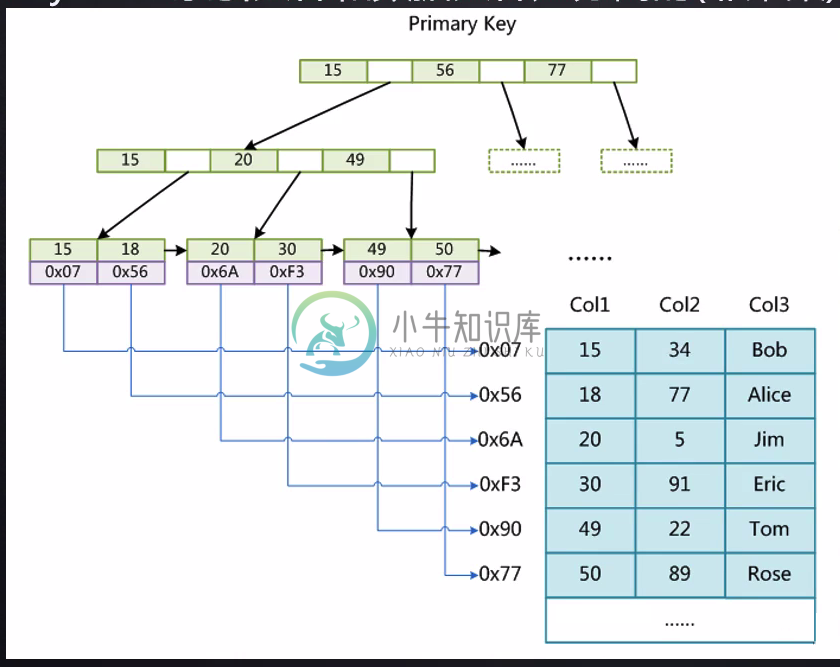 Myisam和Innodb索引实现的不同
Myisam和Innodb索引实现的不同myisam和innodb索引实现的不同 MyIsam:主键索引和普通键索引的树的叶子节点和非叶子节点存放的数据是一样的,非叶子节点存放的都是主键,叶子节点存放的都是主键和相应的地址值,地址值根据另外一个表.MYD查找数据 主键索引:叶子节点为全部数据的K和对应的V的地址,非叶子节点存放的是带有索引的K 辅助索引:和主键索引一样 Innodb:主键索引的叶子节点存放的是所有数据的key和全部数据,
-
MySQL的InnoDB和MyISAM存储引擎的区别
详细介绍了MySQL 的InnoDB和MyISAM存储引擎的区别。 存储引擎主要负责数据的存储和提取。其架构模式是插件式的,包括InnoDB、MyISAM、Memory 等多个可选的存储引擎,InnoDB 在5.5.5后成为默认存储引擎。存储引擎通过API与上层进行通信,这些API屏蔽了不同存储引擎之间的差异,使得这些差异对上层查询过程透明。MySQL的存储引擎架构将查询处理以及其他任务系统和数据
-
 InnoDB的磁盘结构之表空间格式
InnoDB的磁盘结构之表空间格式主要内容:一、表空间的文件类型,二、表空间文件格式,三、应用流程,四、总结一、表空间的文件类型 表空间的文件类型其实就文件的具体类型,在前面谈到过表空间的上层逻辑分层,最下面一层是通过Page来实现的,也就是说,文件的底层就是通过链表来控制这个页数据。而这些页数据的具体保存到硬盘中,主要为为两类,即: FSP_HDR/XDES Page和fseg inodes Page。 page的默认大小为16K,在InnoDB中extent是分配页的基本单位,每个extent包含6
-
 InnoDB的磁盘结构之日志文件格式分析
InnoDB的磁盘结构之日志文件格式分析主要内容:一、日志种类,二、文件格式类型,三、redo log文件格式,四、相关代码,五、总结一、日志种类 在前面分析过了MySql数据库的日志,主要是两大类,即MySql的日志和数据库引擎的日志。在前面分析过的TC_LOG就是MySql中的2PC日志,同时Binlog也继承了此日志。在InnoDB引擎中,有Redo Log和Undo Log,在前面分析上层 控制的基础上,本次重点分析redo log日志的文件结构和相关控制流程。 二、文件格式类型 在Redo Log日志中,它是记载的逻辑
-
InnoDB的磁盘结构源码分析
主要内容:一、基本介绍,二、表空间,三、数据字典,四、双写缓冲区,五、日志,六、总结一、基本介绍 在前面的一篇中初步对InnoDB磁盘结构的表空间,数据字典,双写缓冲区、日志进行分析说明,对InnoDB的磁盘结构有了一个整体上的概念上的认识。这样,在下面的源码分析中,就可以比较清楚的把功能和源码的内容就对起来,做到心中有数,看代码才不会一头雾水。 二、表空间 表空间是InnoDB在文件IO上的一层逻辑存储空间管理的结构,它基本可以分为space、segment inode、ext
-
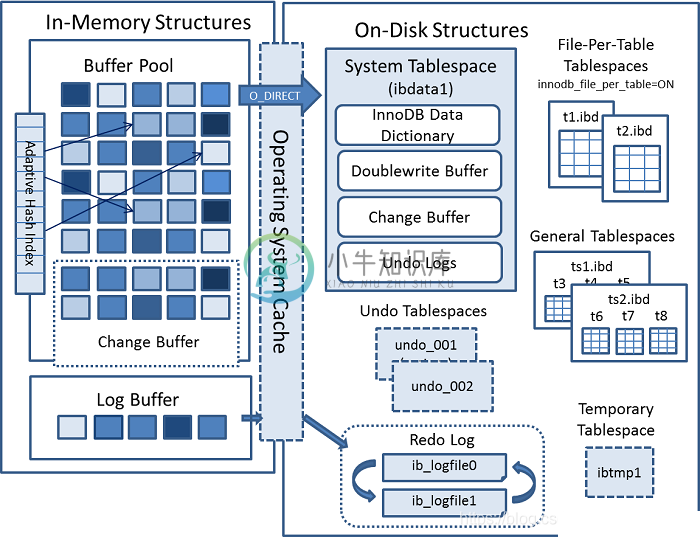 InnoDB的磁盘结构
InnoDB的磁盘结构主要内容:一、磁盘结构的内容,二、表空间,三、数据字典,四、双写缓冲区,五、日志,六、总结一、磁盘结构的内容 InnoDB磁盘结构主要包含表空间,数据字典,双写缓冲区、日志(重做日志和撤销日志)。说起内存结构和磁盘结构,很多人可能有点晕,确实,刚刚接触的或者没有搞清楚是什么问题的,一定会有些晕。其实这个如果搞过内存数据写物理文件的,就容易理解了。在内存中,会有一套数据结构,然后会把这些数据最终整理成一套易于和硬盘交互的结构,这样,就更容易程序的编写和维护。 如果单纯是为了实现功能,写代
-
InnoDB的内存应用整体架构源码
主要内容:一、基本介绍,二、Buffer Pool的整体应用框架,三、总结一、基本介绍 在前面基本把几个缓冲的创建应用的源码搞定了。但是在宏观层次上的使用是怎么设计的呢?这篇就分析一下Buffer Pool的整体应用框架,其它的如果有时间再慢慢一一补齐,重点还是要把MySql的架构先理清大的脉络,最后在抓住细节各个击破。 二、Buffer Pool的整体应用框架 在MySql中,一个数据库的实例生成,一定会生成一个数据的引擎实例。所以,在前面的数据库启动流程里,会通过插
-
InnoDB的内存应用源码
主要内容:一、基本介绍,二、Buffer Pool,三、Change Buffer,四、ADaptive Hash Index,五、Log Buffer,六、总结一、基本介绍 在前面基本把InnoDB引擎的相关内存数据结构分析说明完成了。那么,一个重要的问题来了,这些内存的数据结构有什么作用,用在哪儿?其实就是一个从设计到应用的问题。在学习源码的过程中,往往会有这么一种现象,就是单纯的学习一些源码的应用,或者说一些使用的技巧。稍微用心的可能看一个这些模块间是如何设计的,有什么可借鉴之处。 其实,