《农业银行》专题
-
Spark作业长时间运行,数据太少
我在Master上运行了一个如下所示的spark代码: 我的集群配置:独立/客户机模式下的3个节点(1个主+2个从) 我尝试添加一个新的集群,因为上面搜索的关于资源不足的错误,但是这个错误在伸缩时仍然存在。 是因为节点中的内存较少吗??这里有什么建议吗??
-
Docker桌面没有运行Windows 11企业版
一旦启动 Docker 桌面 4.4.4 版本 ,Docker 服务停止并出现以下错误
-
 快手春招行业电商运营三面
快手春招行业电商运营三面二面当天就约了三面啦! 三轮面试体验感最好的一轮!面试官很nice,一直在笑,虽然我回答的一般,但是真的很有亲和力就是了 1.自我介绍 2.深挖经历(基本上都在这段了) 有很多问题其实我没太理解,就直接跟面试官说我不是很理解问题的意思,然后就会很细的再给讲一遍!谁懂,勇敢说自己听不懂的感觉真的很舒服! 3.职业规划(我从我对电商的理解角度出发的,谈了自己可能会转品牌的想法) 4.愿意做行业中台侧还
-
 京东 行业运营 秋招三面面经
京东 行业运营 秋招三面面经流程:一面 - 二面 - 三面 - 谈薪 - 正式offer 三面(30min) 业务部门: base上海 自我介绍 自我介绍提到了我的优势,所以接着问有什么缺点 如果没有xx条件你能不能达成目标 既然没有xx条件也可以达成目标你为什么要去协调xx来超额达成目标 协调中有什么问题 追问紧张感的来源是什么 现在怎么克服的 如果给别人传授经验怎么讲 实习经历深挖 为什么领导选择你的方案 别人的方案和你
-
 京东物流行业解决方案面经
京东物流行业解决方案面经事务部是市场与公共事务部 售前主要参与了什么工作内容 售前获取信息的资料渠道、收集资料会收集哪方面的资料、客户的资料是怎么整理或呈现。 仿真的目标客户是在物流自动化设备这块嘛 为客户还是为供应商做的物流呢 仓库、作业等详细信息是获取不到的怎么办? 有没有参与过客户从售前到落单的全流程 第二份实习主要做的项目和工作内容是什么 第二份实习的三方面工作主要做什么呢 季度报告是全行业发布? 数据模型方面、
-
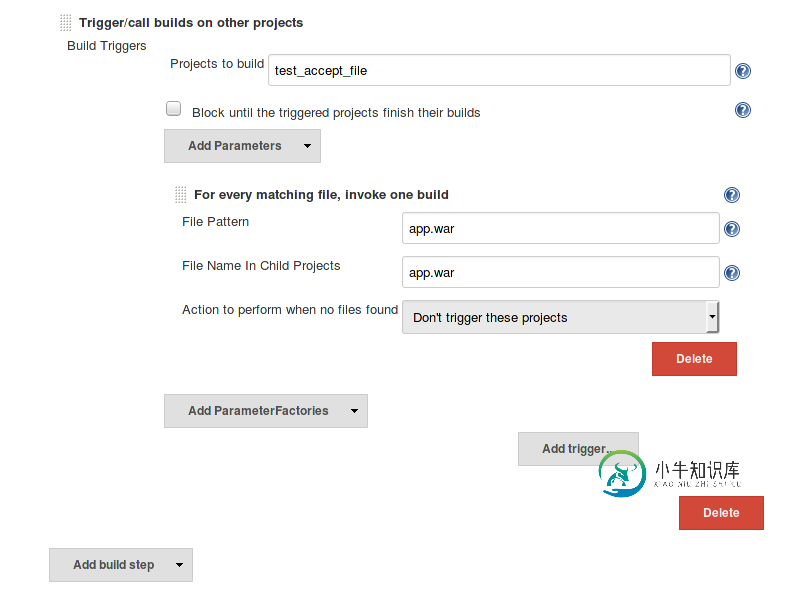 如何将文件传递到阻止上游作业的下游作业?
如何将文件传递到阻止上游作业的下游作业?问题内容: 我要完成的工作是从分支中签出代码,将其合并到分支,构建,运行测试,如果测试成功则推送到分支。 测试应在需要的单独工作中运行。 我当前的设置如下: Job 从中检出,将其合并并构建 作业会在“ 后期制作”步骤中 触发作业(需要预先创建) 如果成功,则在 发布构建操作中推送到分支 __ 我尝试使用 Copy Artifact Plugin, 但是问题在于,在 Post构建步骤中 触发时,我
-
是否可以将Jenkins自由式作业转换为多配置作业?
问题内容: 我在詹金斯(Jenkins)有很多自由式工作,我想转换为多配置工作,这样我就可以在一项工作下跨多个平台进行构建。这些作业指定了很多构建参数,我不想通过创建新的多配置作业来再次手动设置它们。当前,每个作业都将其构建限制为我们一直在构建的平台,而我看到的唯一其他选择是克隆现有作业,并将限制更改为新平台。这不是理想的选择,因为我需要维护2个工作,其中唯一的区别是目标平台。 我没有看到通过UI
-
Jenkins executor忙-加载条作业,但没有链接或id-幽灵作业
Jenkins重启后,我们发现很少有节点执行器繁忙。占据executor的作业有条带的蓝白加载条,并且没有链接到任何特定的构建(事实上,该作业没有正在进行的构建)。所以我们没有id或ui方式来中止它,您可以在这里看到: 詹金斯节点上的工作是什么样子的 现在,我想找到一种方法,在不真正调查问题原因的情况下杀死它,也许它与Jenkins管道作业相关,不会在UI中完成——但在我们的情况下,我们没有基本的
-
Spring Batch Admin现有作业在新作业注册后不再可启动
目前,由于一个我无法解决的问题,我一直在将Spring Batch Admin(SBA)集成到我们的项目中。希望有人能给我一个建议。 我们使用了示例SBA应用程序(Github的当前版本),只添加了一个Tasklet。我通过/job配置上传Spring批处理描述(XMLs)。SBA的json API使用。这工作正常。在SBA的HTML页面中,我看到该作业已注册并可启动。它可以通过API(/jobs
-
Azure Web作业未启动并始终给出“未找到作业功能”
我正在尝试使用触发器运行Azure网络作业,但我的时间作业方法没有触发。我收到了下面的消息。 未找到工作职能。尝试将您的作业类和方法公开化。如果您正在使用绑定扩展(例如ServiceBus、定时器等。)确保您已经在启动代码中调用了扩展的注册方法(例如config。UseServiceBus()、config。使用定时器()等。). 我正在使用配置。UseTimers() 但仍显示消息。不确定以下代
-
在Jenkins中将作业A的工作空间url传递给作业B
我有两个管道作业作业作业A和作业B。我需要通过作业A的工作空间url(比如 /var/lib/jenkins/workspace/JobA)被作业B使用。主要的想法是我试图复制由于maven构建而生成的目标文件夹的内容,但我不想使用复制工件插件或存档工件插件来实现同样的目的。 我尝试过使用“此作业已参数化”选项,其中作业A是作业B的上游,但我无法使用该选项。 有人能帮助实现同样的目标吗?
-
如何从数据流作业内部获取数据流作业 ID - JAVA
在我当前的架构中,多个数据流作业在不同阶段被触发,作为ABC框架的一部分,我需要捕获这些作业的作业id作为数据流管道中的审计指标,并在BigQuery中更新它。 如何使用JAVA从管道中获取数据流作业的运行id?有没有我可以使用的现有方法,或者我是否需要在管道中使用google cloud的客户端库?
-
部署 Seafile 专业版服务器 - 从社区版迁移至专业版
限制条件" class="reference-link">限制条件 您可能已经部署过 Seafile 社区版服务器,并想要切换到专业版,或者反过来从专业版迁移到社区版。但是有一些限制条件需要您注意: 您只能在相同大版本的社区版服务器和专业版服务器之间进行切换。 这意味着,如果您正在使用 2.0 版本的社区版服务器, 并且想要切换到 2.1 版本的专业版服务器,您必须先将您的社区版服务器升级到 2.
-
GCP数据流批处理作业-防止工人在批处理作业中一次运行多个元素
我正在尝试在GCP数据流中运行批处理作业。工作本身有时会占用大量内存。目前,工作一直在崩溃,因为我相信每个工作人员都在试图同时运行pcollection的多个元素。有没有办法防止每个工人一次运行多个元素?
-
 5月21日 中国银行湖北分行前端实习面试
5月21日 中国银行湖北分行前端实习面试先是群面,面试官有3位,我们这组共有6人(包含我) 问题:你有组织过学校活动吗?大概说一说(限时1min) 然后是单面。 单面的顺序是按照你群面时回答的顺序来的。一共5min,面试官会根据你的自我介绍问问题,自我介绍只有1min,过时间了没说完也会被打断。 感受: 面试没有问什么技术上的问题。 主持人会提前半小时把我们拉进群,然后大概等半小时的样子,进入会议室群面。 等待时间感觉好长,总共6min