《计算机视觉岗》专题
-
流量中的流数据计算
-
计算代码度量时出错
当我试图在Visual Studio 2013 for C#项目中运行代码度量(分析->计算解决方案的代码度量)时,我得到了以下错误: null
-
Java原语范围计算[重复]
在Java中,当我们声明 它会给编译时间错误,但是 编译得很好。为什么会这样?
-
Java计算后的饱和问题
我正在创建一个反向波兰计算器,并且有饱和度的问题。我已经实现了一个堆栈,并且发现我可以在没有问题的情况下得到的最大数字是2147483647。所以如果我把这个数字推到堆栈上,然后加1,我得到的结果是-2147483648(负)。我需要做的是不要返回这个负数,而是返回原来的数字2147483647。基本上有这个作为限制。这同样适用于事物的负面,那里的限制是-2147483648的。让我知道我是否错过
-
在JTable中计算运行总数
我需要在我的JTable中填充一列,该列计算一个运行总计,如下所示。 我有4个类——每个员工一个实体类,一个表模型类,一个扩展JFrame以显示输出的主类,以及一个用于格式化最后两列中的数字。代码如下所示。我遇到的问题是运行总数没有正确计算。由于当前编写的代码,第一个总数太高了80,000,这让我认为它在移动到第二个员工之前添加了第一个员工三次。每个后续总数都被正确添加,但当然最终总数相差80,0
-
科学计算用GPU的精度
一位电气工程师最近告诫我不要将GPU用于科学计算(例如,在精度非常重要的情况下),因为它没有像CPU那样的硬件保障。这是真的吗?如果是的话,这个问题在典型的硬件中有多普遍/多严重?
-
出色的年-周组合计算
我目前正在制作一个excel模型,其中日期是其中的一个重要方面。然而,由于信息来自不同的来源,有时它的结构是不现实的。我在计算年和周的组合时遇到了问题,比如添加或减去周。开始数据如下所示: 现在,如果我想加上例如3周,我可以通过加上3来做到这一点,结果是201528。然而,当涉及到201552(有时是yyyy53)时,这就更难了,因为我需要计算到2016年。 回溯到2014年或更早的时候,情况也是
-
带舍入的Excel日期计算
我目前正在做一个报告,我想找出两个日期之间的月份。我目前有这个 =(DATEDIF(U224, V224,"m")1) 然而,我希望它添加另一个元素,如果初始日期是在本月15日或之前,如果是16日,则会四舍五入,之后会四舍六入。 例如,第一个日期是2月13日,第二个日期是6月31日。它将带回5个月。然而,如果第一次约会是2月20日,则会提前4个月。 提前谢谢
-
计算当前月份的行数
我有一列填写了ISO格式的日期(带有标题行),例如: 我想数一下与当月匹配的行数。 是否可以使用Google电子表格中的功能来实现此结果? 没有ISO日期的相同问题可以在以下位置找到: 计算当前月份的行数
-
Optaplanner得分计算类型问题
解决Optaplanner使用中的疑点。OptaPlanner使用以下分数计算类型:Drools分数计算或约束流分数计算。两种方法都支持分数的增量计算。分数增量计算的一个疑点: 演示: > 假设requiredCpuPowerTotal条件成立,则执行then逻辑,并添加硬分数,假设为-100。 null
-
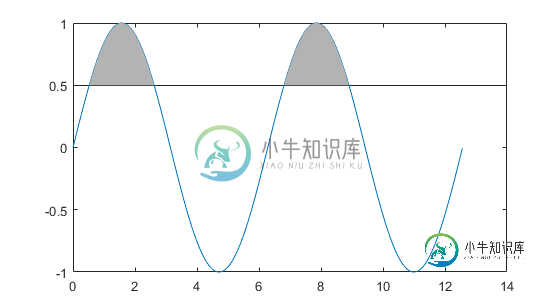 遮荫并计算特定面积
遮荫并计算特定面积我试图以某种方式更改代码,以便只有第一个区域是阴影灰色的。如何设置水平线,使其只出现在我要遮蔽的区域下面? 此外,我想计算一个区域的面积。我如何做到这一点?我知道它是,但我不确定如何设置边界。谢了!
-
多线程与单线程计算
为什么单线程和多线程脚本具有相同的处理时间?多线程实现不是应该少1/#线程数吗?(我知道当您达到最大cpu线程时,回报会递减) 我搞砸了我的实现吗?
-
如何并行化Spark scala计算?
当我使用spark API运行类似的代码时,它在许多不同的(分布式)作业中运行,并且成功运行。当我运行它时,我的代码(应该做与Spark代码相同的事情),我得到一个堆栈溢出错误。知道为什么吗? 代码如下: 我相信我正在使用与spark相同的所有并行化工作,但它对我不起作用。任何关于使我的代码分发/帮助了解为什么在我的代码中发生内存溢出的建议都将是非常有帮助的
-
支持负数的 ANTLR 计算器
我正试图创建一个也支持负数的计算器,并最终创建一个lisp风格的树。 我这样定义lexer规则: 我对每个操作都有一个规则,例如: 但是当我尝试输入表达式:时,出来的lisp树是。 为什么它忽略 ?
-
 网易-算法-8.20笔试统计
网易-算法-8.20笔试统计#做完网易2023秋招笔试题,我裂开了# 1. 100%,直接把数字比坐标大的数一直减,直到和位置相等;对应的去找需要+1的数字,需要用hash维护每个数字所在的位置。 2. 46.3%,前缀和+暴力枚举长度。 3. 100%,从高位到低位计算二进制位为1的个数并记录这些数字,≥k就更新vector,不然沿用上一次的vector。 4. 60%,先计算出第n项ab对应的幂(需要用矩阵快速幂计算法)