《计算机视觉岗》专题
-
 机器学习算法 Python 实现
机器学习算法 Python 实现本教程将全面介绍深度学习从模型构造到模型训练的方方面面,以及它们在计算机视觉和自然语言处理中的应用。
-
 淘天 1688 机器学习算法
淘天 1688 机器学习算法二面挂 总时长1.5h,面试45min,剩下时间手撕 面试大概问题: 1.讲数据挖掘比赛的过程 2.连续字段怎么转换为离散字段 3.讲一个困难的经历是如何解决并分工的 4.讲一个自己熟悉的网络框架 5.L1正则和L2正则 6.多模态数据怎么利用,模型怎么设计 其他的记不清了 反问环节: 1.部门做什么的 2.用的主要方法是什么 手撕代码,两问: 1.给定函数f(x) = 1.2 x^2 - 0.8
-
 字节ai lab 机器人算法
字节ai lab 机器人算法一面偏向讲论文和比赛,两道coding例行公事 二面聊天,分析论文不足,面向业务场景提问,考察知识面广度,coding二分查找 三面继续聊天,开放性场景,考察思维的深度和广度,coding很难 随缘等通知 #字节#
-
 美团无人机算法二面
美团无人机算法二面2024.4.30 15:00,25分钟结束了... 直接自我介绍,聊了一下项目,对项目的潜在优化方向聊了一下,然后多拓展了一些接近业务场景的用途。 问规划,入职时间与周期,地点,然后没了0.o? 早上刚整完蚂蚁也没敢问不要手撕一个吗....迷迷糊糊地退出了跑来这里发 ----------5.8------------ 已oc+offer
-
Java:计算返回错误答案?
问题内容: 例如,这样简单的事情: 打印110.00000000000001而不是110。使用其他数字代替100 * 1.1还会给出很多数字,并且末尾有一些随机数字,这是不正确的。 有任何想法吗? 问题答案: 浮点符号的准确性有限。这是一个指南:http : //floating-point- gui.de/
-
计算大文件中的行数
问题内容: 我通常使用大约20 Gb大小的文本文件,并且发现自己经常对给定文件中的行数进行计数。 我现在做的只是,而且需要很长时间。有什么解决方案会更快吗? 我在安装了Hadoop的高性能集群中工作。我想知道地图缩小方法是否可以提供帮助。 我希望解决方案像解决方案一样简单,只需一条生产线,但不确定其可行性。 有任何想法吗? 问题答案: 尝试: 猫也是不必要的:用您现在的方式就足够了。
-
Java:计算三角形的面积
问题内容: http://upload.wikimedia.org/math/f/e/5/fe56529cdaaaa9bb2f71c1ad8a1a454f.png <-区域公式 我试图从2D笛卡尔坐标系中的3个点(x,y)计算三角形的面积。我假设我的上述公式正确产生了三角形的面积(如果不是,请更正我),但是我的编译器说“运算符- 无法应用于java.awt.Point,java.awt.Point
-
计算字节数组的SHA-1
问题内容: 我正在寻找一种以Java字节数组作为消息获取SHA-1校验和的方法。 我应该使用第三方工具还是JVM内置的某些工具可以帮助您? 问题答案: 关于什么:
-
计算3点(x,y)的曲率
问题内容: 我有一个二维欧几里德空间。给出了三点。 例如(p2是中间点): 现在,我想计算这三个点的曲率。 这该怎么做?是否存在现有方法(没有Java外部库)? 曲率:https : //en.wikipedia.org/wiki/曲率 Menger曲率:https: //en.wikipedia.org/wiki/Menger_curvature 问题答案: 对于Menger Curvature
-
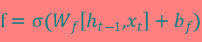 LSTM每个门的计算公式
LSTM每个门的计算公式本文向大家介绍LSTM每个门的计算公式相关面试题,主要包含被问及LSTM每个门的计算公式时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 遗忘门: 输入门: 输出门:
-
xgboost的特征重要性计算
本文向大家介绍xgboost的特征重要性计算相关面试题,主要包含被问及xgboost的特征重要性计算时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Xgboost根据结构分数的增益情况计算出来选择哪个特征作为分割点,而某个特征的重要性就是它在所有树中出现的次数之和。
-
MySQL:每天计算不同的行
问题内容: 我有一个有趣的查询需要做。我有一张表,其中有一列包含ip地址编号(使用)和一列。我希望能够计算每天有唯一IP地址列的数量。也就是说,每天有多少个不同的ip行。因此,例如,如果一个IP地址在同一天两次,则在最终计数中将计为1;但是,如果同一IP地址在另一天,则将被计算为第二个计数。 示例数据: 问题答案: SQLFiddle演示
-
MySQL查询以计算上个月
问题内容: 我想计算上个月的总订单金额。 我得到了从当前日期获取当前月份数据的查询。 现在,我如何仅获取前一个月的数据,不包括本月。 例如,本月(7月)我赚了15,000美元,上个月(6月)我赚了14,000美元。 通过运行上述查询,我得到了$ 15,000。 但是我不知道如何计算上个月。 问题答案: 在这里,您可以使用它在MySQL中获取上个月的第一个月到上个月的最后一天之间的日期:
-
Postgresql查询效率计算初探
本文向大家介绍Postgresql查询效率计算初探,包括了Postgresql查询效率计算初探的使用技巧和注意事项,需要的朋友参考一下 摘要 关系数据库很重要的一个方面是查询速度。查询速度的好坏,直接影响一个系统的好坏。 查询速度一般需要通过查询规划来窥视执行的过程。 查询路径会选择查询代价最低的路径执行。而这个代价是怎么算出来的呢。 主要关注的参数和表 参数:来自postgresql.conf文
-
计算子句中的列-性能
问题内容: 由于您不能在MySQL的where子句中使用计算列,如下所示: 你必须使用 计算(在该示例中,“(a * b + c)”是每行执行一次还是两次执行?有没有一种方法可以使速度更快?我觉得很奇怪,可以对列进行ORDER但没有WHERE- 条款。 问题答案: 您可以使用HAVING来过滤计算列: 请注意,您需要将其包括在SELECT子句中才能起作用。