《分布式锁》专题
-
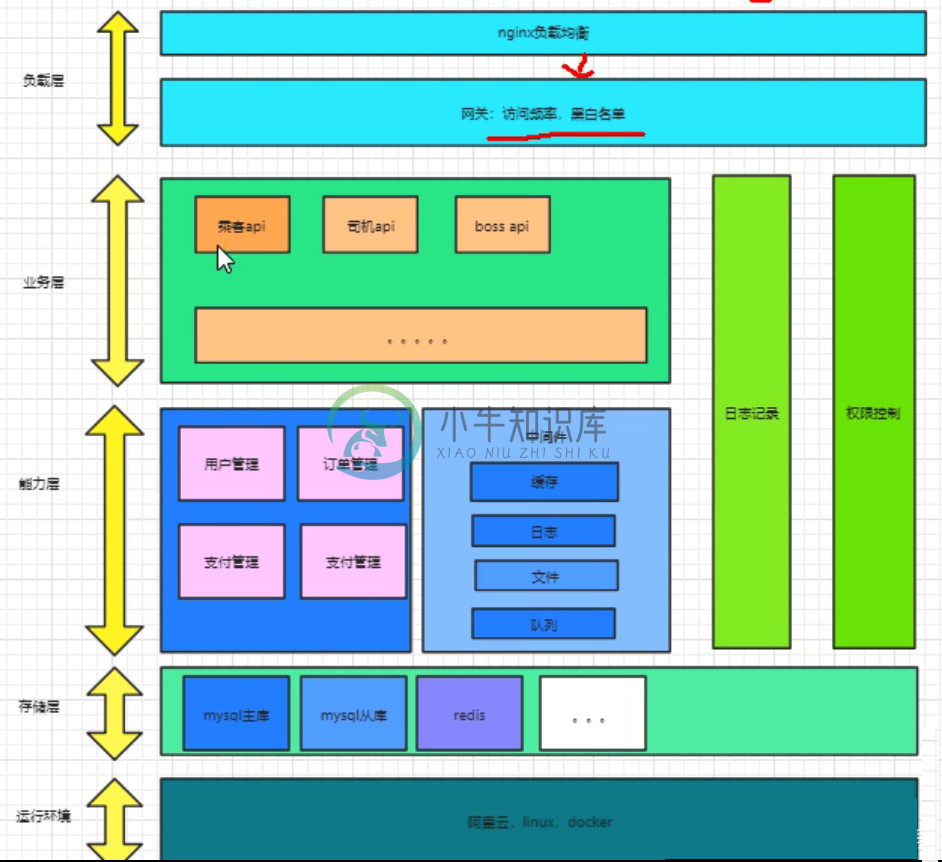 分布式专题面试(2)-5个问题
分布式专题面试(2)-5个问题主要内容:1.分布式微服务项目是如何设计的,2.cookie和session的区别如何用session进行身份验证,3.tokenjwt如何通过token进行身份验证,4.为什么token可以预防CSRFcookie无法防止,5.分布式下session共享方案1.分布式微服务项目是如何设计的 1.负载层 2.业务层 3.能力层(中台) 4.存储层 5.运行环境 2.cookie和session的区别,如何用session进行身份验证 cookie和session都是会话技术,都是存储信息数据用的
-
 分布式专题面试(1)-14个问题
分布式专题面试(1)-14个问题主要内容:1.分布式Id的策略,2.雪花算法生成的Id由哪些部分组成,3.分布式锁在项目的应用场景,4.分布式锁有哪些解决方案,5.Redis做分布式锁的话死锁有哪些情况如何解决,6.Redis如何做分布式锁,7.基于zk分布式锁的原理,8.zk和redis分布式锁的区别,9.mysql如何做分布式锁,10.计数器算法是什么,11.滑动时间窗口算法是什么,12.漏桶限流算法是什么,13.令牌桶限流算法是什么,1.分布式Id的策略 这里的uuid生成策略 1.基于时间生成:Mac地址+时间戳+随机
-
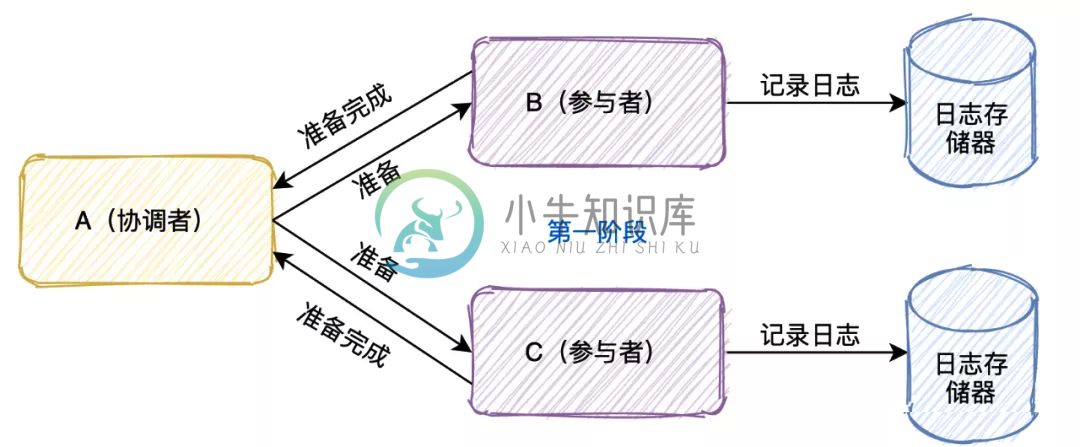 Spring Tx (分布式事务及解决方案)
Spring Tx (分布式事务及解决方案)主要内容:1.2PC,2.三阶段提交(3PC),3.补偿事务(TCC),4.本地消息表,5.消息事务,6.最大努力通知,7.Sagas 事务模型1.2PC 两阶段提交 mysql是通过日志系统完成事务的。就是两阶段提交:undolog和binlog的两阶段提交。 两阶段协议可以用于单机集中式系统,由事务管理器协调多个资源管理器;也可以用于分布式系统,由一个全局的事务管理器协调各个子系统的局部事务管理器完成两阶段提交。 第一阶段:投票阶段 1.协调者写命令进写入日志 2.协调者发一个prepare
-
 smartX分布式系统管理平台一面
smartX分布式系统管理平台一面差不多70MIN 面试官人很帅,而且上来就介绍面试流程,整个面试下来感觉很舒服,写算法题的时候也在和面试官沟通确定一些特殊情况 1.自我介绍 2.集中管理平台是什么#面经# 3.发布是怎样实现的 4.Exporter是怎么采集到数据的 (没答好 确实没了解过) 5.交付相关 6.Prometheus规则是怎样的 具体存储在哪里 7.仪表盘数据是哪里来的 Prometheus支持多少台机器 8.怎么
-
到达分布
在我的模型上,为代理设置自定义分布,以达到双峰分布,从而模拟白天的峰值。要明确的是,代理有一个名为“arrivals”的参数,我们有一个连接到代理的自定义分发,其中“arrivals”的分发设置为自定义分发。最后,源将到达率设置为上述自定义分布。然而,在运行模型时,到达的速度似乎比我在建模时预期的要快得多。分配设置为“每小时”。 以下是源设置和自定义分发source\u settings分发的屏幕
-
地域分布
地域分为两部分: 信息筛选 和 地域分布 (详情) 1.时间筛选 便捷按钮有今日、昨日、前日、上周 X、近七天,可自定义选择地域名、省份、时间段、设备等来得出想要的结果报表 2.地域分布 (详情) 1)地域分布:国家/省份、城市、接入商、国家/省份+城市、国家/省份+接入商、城市+接入商 2)如有需要,亦可点击下载当前报表及更多数据下载,将报表下载到个人电脑,以供存档及分析
-
地域分布
功能介绍 获取地域分布报告数据,包括表格详情数据与趋势数据,所获取数据与 https://mtj.baidu.com 中报告数据一致 接口 https://openapi.baidu.com/rest/2.0/mtj/svc/app/getDataByKey 此处仅列本接口特有参数,公共参数请参考报告级API说明 获取表格数据 参数名 参数类型 是否必须 描述 method string 是 r
-
分区布局
分区布局将会产生邻接的图形:一个节点链的树图的空间填充转化体。节点将被绘制为实心区域图(无论是弧还是矩形),而不是在层次结构中绘制父子间链接,节点将被绘制成固定区域(弧度或者方形),并且相对于其它节点的位置显示它们的层次结构中的位置。节点的尺寸将编码为一个量化的维度,这将难以在一个节点链图中展示。 就像D3的其他类,布局将遵循方法链模式,setter方法返回布局本身,并通过一个简洁的语句来调用多个
-
发布分支
从开发者的角度讲,一个自由软件项目处于连续发布的状态。开发者通常一直在任何时候都运行最新的可用代码,因为他们需要定位bug,而且因为他们近距离的接触项目,可以避开当前特性的不稳定区域。他们通常会每天更新他们软件的备份,有时一天几次,当他们检入变更时,他们有道理认为其他开发者会在24小时内得到。 然而,何时项目应该做出正式的发布?是否仅仅取得某个时刻的快照,打包并交给世界,然后说“3.5.0”?常识
-
分布式 - 如何充分利用多个计算机资源?
有多台笔记本电脑,手机,如何统合这些计算资源? 比如我在一台电脑上安装QQ这个软件 另一台电脑上不需要再安装这个软件 也可以使用QQ这个程序也就是说同样的资源是需要在一台电脑上即可 (我尝试过网络存储,但是效果不太好,首先太慢了,其次需要把每台电脑灯配置成服务器) 另外一个要求 对于一个计算任务把它分配给不同电脑上的CPU进行计算 顺便问一下企业是如何实现多个CPU资源充分利用
-
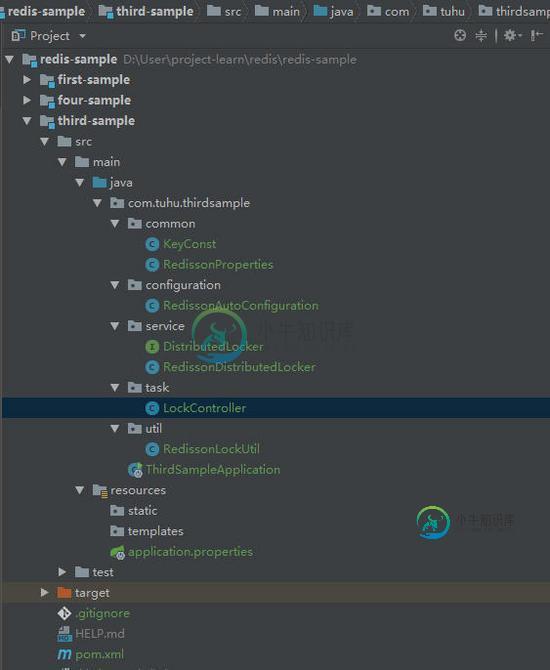 SpringBoot集成Redisson实现分布式锁的方法示例
SpringBoot集成Redisson实现分布式锁的方法示例本文向大家介绍SpringBoot集成Redisson实现分布式锁的方法示例,包括了SpringBoot集成Redisson实现分布式锁的方法示例的使用技巧和注意事项,需要的朋友参考一下 上篇 《SpringBoot 集成 redis 分布式锁优化》对死锁的问题进行了优化,今天介绍的是 redis 官方推荐使用的 Redisson ,Redisson 架设在 redis 基础上的 Java 驻内存
-
瘦客户端的ignite ClientCache是否支持分布式锁
现在我使用的是瘦客户机的ignite ClientCache,我没有找到ClientCache的分布式锁,如果要使用分布式锁,必须使用ignition.start()
-
分布式运行模式下Kafka Producer的唯一事务ID
我有一个基于过程消费的大数据应用程序- 假设我的应用程序在一台机器上运行,我实例化了2个消费者,他们有自己的生产者,例如生产者1有事务ID - 如果我的应用程序在一台机器上工作,这完全可以正常工作,但是,事实并非如此,因为应用程序需要在多台机器上运行,因此当相同的代码在机器2上运行时,由机器2上的消费者实例化的生产者将具有与机器1上相同的事务ID。我希望事务ID的生成方式不会相互冲突,并且它们是可
-
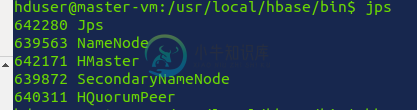 HBase完全分布式模式[执行HBase shell时Zookeeper错误]
HBase完全分布式模式[执行HBase shell时Zookeeper错误]根据这两个教程:即教程1和教程2,我能够在完全分布式模式下设置HBase集群。最初,集群似乎工作正常。 hmaster/Name节点中的“jps”输出 datanodes/RegionServers中的jps输出 null (我已经试着在/etc/hosts/中评论与HBase相关的主机,但仍然没有成功) 在hbase-site.xml中
-
深度剖析一站式分布式事务方案Seata-Server
再前不久,我写了一篇关于分布式事务中间件Fescar的解析,没过几天Fescar团队对其进行了品牌升级,取名为Seata(Simpe Extensible Autonomous Transcaction Architecture),而以前的Fescar的英文全称为Fast & EaSy Commit And Rollback。可以看见Fescar从名字上来看更加局限于Commit和Rollback