《分布式》专题
-
Java正态分布
问题内容: 我正在尝试模拟球迷到达体育场的情况。我相信系统本身不会有问题,但是风扇的到来遵循正态分布。 我的问题是: 我有一定的到达时间(例如100分钟和1000个风扇),我需要在分配之后的某个时间生成风扇的到达时间,例如->风扇x到达25分钟,风扇y到达54分钟,依此类推。 如何按照正态分布生成这些随机数? 我正在Java中执行此操作,并在Random类中找到了该方法,但是我不确定如何在我的情况
-
hazelcast数据分布
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
九、经验分布
大部分数据科学都涉及来自大型随机样本的数据。 在本节中,我们将研究这些样本的一些属性。 我们将从一个简单的实验开始:多次掷骰子并跟踪出现的点数。 die表包含骰子面上的点数。 所有的数字只出现一次,因为我们假设骰子是平等的。 die = Table().with_column('Face', np.arange(1, 7, 1)) die Face 1 2 3 4 5 6 概率分布 下面的直方图
-
概率分布 - torch.distributions
译者:hijkzzz distributions 包含可参数化的概率分布和采样函数. 这允许构造用于优化的随机计算图和随机梯度估计器. 这个包一般遵循 TensorFlow Distributions 包的设计. 通常, 不可能直接通过随机样本反向传播. 但是, 有两种主要方法可创建可以反向传播的代理函数. 即得分函数估计器/似然比估计器/REINFORCE和pathwise derivative
-
第八章 HBASE - 1.HBASE的伪分布安装与分布式安装
一 伪分布式安装 1.下载解压给权限 可以从官方下载地址下载 HBase 最新版本,推荐 stable目录下的二进制版本。我下载的是 hbase-1.1.3-bin.tar.gz 。确保你下载的版本与你现存的 Hadoop 版本兼容(兼容列表)以及支持的JDK版本(从HBase 1.0.x 已经不支持 JDK 6 了)。 兼容列表: tar -zxvf hbase-1.1.3-bin.tar.gz
-
分布式部署 - Gateway Worker分离部署
什么是Gateway Worker分离部署 GatewayWorker有三种进程,Gateway进程负责网络IO,BusinessWorker进程负责业务处理,Register进程负责协调Gateway与BusinessWorker之间建立TCP长连接通讯。我们可以把Gateway BusinessWorker Register分开部署在不同的服务器上,当业务进程BusinessWorker出现瓶
-
第 Ⅱ 部分:安装 - 分布式安装
Open-Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件,其安装部署的架构如下图所示, 在单台机器上快速安装 请直接参考quick_install Docker化的Open-Falcon安装 参考: https://github.com/open-falcon/falcon-plus/blob/master/docker/
-
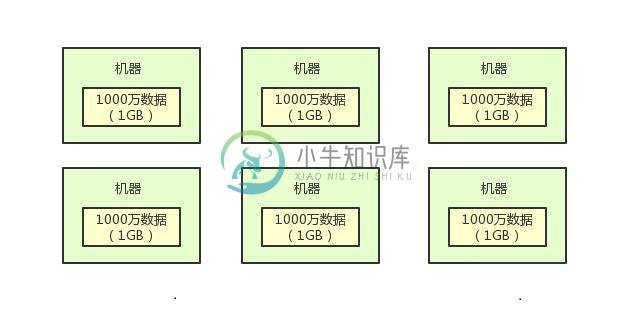 什么是分布式计算系统?如何设计分布式系统?
什么是分布式计算系统?如何设计分布式系统?主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
分布式计算框架 —— MapReduce
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
6.6 分布式配置管理
在分布式系统中,常困扰我们的还有上线问题。虽然目前有一些优雅重启方案,但实际应用中可能受限于我们系统内部的运行情况而没有办法做到真正的“优雅”。比如我们为了对去下游的流量进行限制,在内存中堆积一些数据,并对堆积设定时间或总量的阈值。在任意阈值达到之后将数据统一发送给下游,以避免频繁的请求超出下游的承载能力而将下游打垮。这种情况下重启要做到优雅就比较难了。 所以我们的目标还是尽量避免采用或者绕过上线
-
6.4 分布式搜索引擎
在Web一章中,我们提到MySQL很脆弱。数据库系统本身要保证实时和强一致性,所以其功能设计上都是为了满足这种一致性需求。比如write ahead log的设计,基于B+树实现的索引和数据组织,以及基于MVCC实现的事务等等。 关系型数据库一般被用于实现OLTP系统,所谓OLTP,援引wikipedia: 在线交易处理(OLTP, Online transaction processing)是指
-
6.1 分布式 id 生成器
有时我们需要能够生成类似MySQL自增ID这样不断增大,同时又不会重复的id。以支持业务中的高并发场景。比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒10w+。明星出轨时,会有大量热情的粉丝发微博以表心意,同样会在短时间内产生大量的消息。 在插入数据库之前,我们需要给这些消息、订单先打上一个ID,然后再插入到我们的数据库。对这个id的要求是希望其中能带有一些时间信息,这样即使我
-
第6章 分布式系统
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
其他 - 分布式manager节点
为了保证manager节点的容错性,我们最好将manager节点个数设定为奇数个。在网络被划分成2个部分情况下,奇数个manager节点能够较高程度的保证有投票结果的可能性。如果网络被划分成2个部分以上,投票有结果的可能性将不能被保证。 Swarm节点数 法定票数 允许manager不可用个数 1 1 0 2 2 0 3 2 1 4 3 1 5 3 2 6 4 2 7 4 3 8 5 3 9 5
-
分布式锁和同步器
Lock Redisson 分布式可重入锁,实现了 java.util.concurrent.locks.Lock 接口并支持 TTL。 RLock lock = redisson.getLock("anyLock"); // Most familiar locking method lock.lock(); // Lock time-to-live support // releases loc