《HPC高性能计算工程师》专题
-
如何提高MySQL Limit查询性能的方法详解
本文向大家介绍如何提高MySQL Limit查询性能的方法详解,包括了如何提高MySQL Limit查询性能的方法详解的使用技巧和注意事项,需要的朋友参考一下 在MySQL数据库操作中,我们在做一些查询的时候总希望能避免数据库引擎做全表扫描,因为全表扫描时间长,而且其中大部分扫描对客户端而言是没有意义的。其实我们可以使用Limit关键字来避免全表扫描的情况,从而提高效率。 有个几千万条记录的表 o
-
提高从数据库加载100000条记录的性能
我们创建了一个程序,以便在其他程序中更容易地使用数据库。因此,我显示的代码将在多个其他程序中使用。 其中一个程序从我们的一个客户那里获得大约10000条记录,并且必须检查这些记录是否已经存在于我们的数据库中。如果没有,我们将它们插入数据库(它们也可以更改,然后必须更新)。 为了方便起见,我们从整个表中加载所有条目(目前为120,000个),为我们得到的每个条目创建一个类,并将它们全部放入Hashm
-
与equals相比,使用==操作符如何提高性能?
在Joshua Bloch的有效JAVA中,当我阅读静态工厂方法时,有一个声明如下 静态工厂方法从重复调用中返回相同对象的能力允许类在任何时候对存在的实例保持严格控制。这样做的类称为实例控制类。编写实例控制类有几个原因。实例控件允许类保证它是单实例(第3项)或不可实例化(第4项)。此外,它允许一个不可变类(项目15)保证不存在两个相等的实例:a.equals(b)当且仅当a==b。如果一个类做出此
-
如何重用ScriptContext(或以其他方式提高性能)?
我有一个自制的ETL解决方案。转换层在JavaScript脚本的配置文件中定义,由Java的Nashorn引擎解释。 我遇到了性能问题。也许没有什么可以做的,但我希望有人能找到我使用Nashorn的方式有帮助的问题。该过程是多线程的。 我创建了一个静态脚本引擎,它只用于创建CompiledScript对象。 我将在每条记录上重新执行的Scriptlet编译成CompiledScript对象。 有两
-
 处理BLOB字段时如何提高Eclipse Link的性能?
处理BLOB字段时如何提高Eclipse Link的性能?由于每个实体都有BLOB字段,我的Java应用程序变得非常慢。该字段通常用于存储PDF文件,每当我必须列出所有对象时,都需要相当长的时间,直到持久性提供程序可以完成其工作。我寻找有关如何处理此类数据的答案,但其中一些人谈到将BLOB存储在单独的表中,然后使用FetchType.LAZY.是否有任何方法仅在需要时获取此字段而无需创建另一个表?如果没有,创建另一个表是最合适的解决方案吗? 实体代码 导
-
提高简单Spring批处理作业性能的提示
我第一次使用spring batch应用程序,由于框架太灵活了,我有几个关于性能和实现作业的最佳实践的问题,在spring文档中找不到明确的答案。 > 读取由第三方以先前指定的布局发送的具有固定列长值的ASCII文件(第1步读取器) 在oracle数据库上写入有效行(第1步写入器) 执行前一步后,使用第1步的finish时间戳更新数据库中的表(第2步tasklet) 当作业停止时,发送一封电子邮件
-
优化数据流池大小以提高点火性能
我正在使用ignite2.6,其中有数据流节点,从kafka消耗数据并放入Ignite缓存。服务器平均负载较高,吞吐量降低。 我已经尝试为缓存中定义的索引内联设置索引大小,这样可以提供良好的性能,但也增加了服务器内存利用率和较高的平均负载。请说明在这种情况下增加datastreamer线程池大小会产生什么影响。
-
javascript - 有没有什么高性能图表库或方案?
能支持20ms渲染完上万个点的 echarts测试: echarts codesandbox测试
-
如何使用JPA和Hibernate映射计算的属性
问题内容: 我的Java Bean具有childCount属性。此属性 未映射到数据库列 。取而代之的是,它应该 由数据库通过对Java bean及其子级的联接进行操作 的 函数 来 计算 。如果可以按需/“延迟”计算此属性,那就更好了,但这不是强制性的。 在最坏的情况下,我可以使用HQL或Criteria API设置此bean的属性,但我不希望这样做。 Hibernate 批注可能会有所帮助,但
-
如何计算数据帧中每列的唯一性?
下面有一段代码,它创建了数据框中每列中缺失值的汇总表。我希望我可以构建一个类似的表来计算唯一的值,但是DataFrame没有唯一的()方法,只有每一列是独立的。 (资料来源:https://stackoverflow.com/a/39734251/7044473) 如何为唯一值实现相同的功能?
-
计算属性和聚合数据(Computed Properties and Aggregate Data)
computed属性访问数组中的所有项以确定其值。 它可以轻松添加项目并从阵列中删除项目。 从属密钥包含一个特殊密钥@each ,它更新当前计算属性的绑定和观察者。 例子 (Example) 以下示例通过使用Ember的@each键显示计算属性和聚合数据的使用 - import Ember from 'ember'; export default function() { var Perso
-
javascript - vue3 数组内如何用computed计算属性值?
例如
-
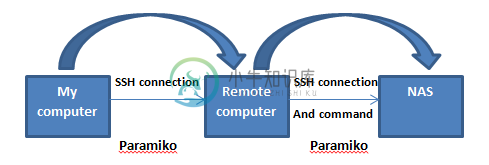 Paramiko、Python、Windows:如何使用SSH连接到远程计算机并从远程计算机连接到NAS
Paramiko、Python、Windows:如何使用SSH连接到远程计算机并从远程计算机连接到NAS我见过几个与这个话题有关的问题和答案,但我一直无法掌握如何做。 > 我所能做的:使用Python脚本(使用Paramiko)连接到远程计算机,并返回信息,例如,ping交换机: ssh=pk.sshclient() ssh.connect(“{}”.format(IP),port=xxx,username='xxx',password='xxx') stdin,stdout,stderr=\“ s
-
1.1.4.9 Mesos 高可用性
Mesos 高可用性 Mesos 利用多台 Mesos master 来实现高可用性(high-availability),包括一个活跃的 master (叫做 leader 或者 leading master)和若干备份 master 来避免宕机。 通过 Apache ZooKeeper 选举出活跃的 leader,然后通知集群中的其他节点,包括其他 Master,slave节点和调度器
-
4.1.1.1.3-PostgreSQL_XL高可用性
(1)GTM不可用导致整个Postgresql集群不可用。 (2)对于Coordinator,不一定需要需要实现高可用。 (3)对于DataNode,实现高可用的方式,外部使用统一IP访问,所以需要实现VIP。 (4)数据分库后,对于使用Postgresql单机进行存储的数据库,需要实现Postgresql服务高可用。 (5)防止出现脑裂,实现高可用的服务,在同一时刻仅有一台物理节点提供服务。对于