《HPC高性能计算工程师》专题
-
我们能计算Spring bean初始化时间吗
我想开发一个Spring AOP特性,在这个特性中,我们可以在Spring bean初始化期间将一个点切入/放入其中,以便根据业务需要计算一些统计信息。我想知道是否可以使用SpringAOP模块?
-
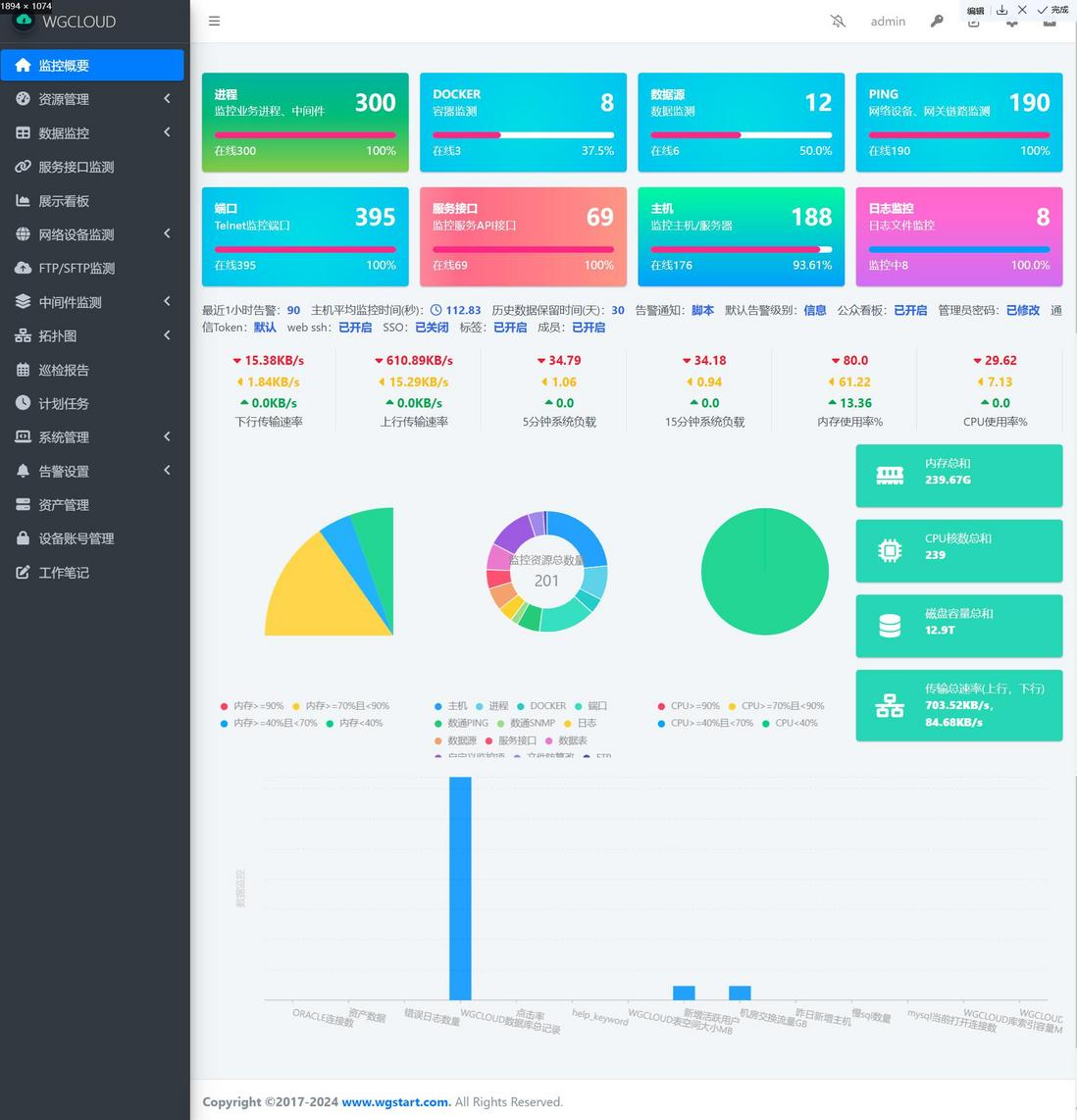 人工智能 - 如何理解wgcloud的【停止计算资源】功能在主机管理中的应用?
人工智能 - 如何理解wgcloud的【停止计算资源】功能在主机管理中的应用?wgcloud的主机列表的【停止计算资源】是做什么用的
-
第五章: 程序性能 - 复习
复习 本书的前四章基于这样的前提:异步编码模式给了你编写更高效代码的能力,这通常是一个非常重要的改进。但是异步行为也就能帮你这么多,因为它在基础上仍然使用一个单独的事件轮询线程。 所以在这一章我们涵盖了几种程序级别的机制来进一步提升性能。 Web Worker让你在一个分离的线程上运行一个JS文件(也就是程序),使用异步事件在线程之间传递消息。对于将长时间运行或资源密集型任务挂载到一个不同线程,从
-
第五章: 程序性能 - Web Workers
Web Workers 如果你有一些处理密集型的任务,但你不想让它们在主线程上运行(那样会使浏览器/UI变慢),你可能会希望JavaScript可以以多线程的方式操作。 在第一章中,我们详细地谈到了关于JavaScript如何是单线程的。那仍然是成立的。但是单线程不是组织你程序运行的唯一方法。 想象将你的程序分割成两块儿,在UI主线程上运行其中的一块儿,而在一个完全分离的线程上运行另一块儿。 这样
-
ansible 使用Ansible设置远程计算机
本文向大家介绍ansible 使用Ansible设置远程计算机,包括了ansible 使用Ansible设置远程计算机的使用技巧和注意事项,需要的朋友参考一下 示例 我们可以使用Ansible设置远程系统。您应该有一个SSH密钥对,并且应该将SSH公钥带到计算机〜/ .ssh / authorized_keys文件中。您可以在未经任何授权的情况下登录。 先决条件: Ansible 您需要一个清单文
-
Matplotlib:在远程计算机上显示图
问题内容: 我有一个python代码在名为A的远程计算机上进行一些计算。我通过名为B的计算机通过A连接到A。是否可以在B的计算机上显示图形? 问题答案: 如果在远程计算机(B)上的Mac OS X上使用matplotlib,则必须首先确保使用基于X11的显示后端之一,因为本机Mac OS X后端无法将其图导出到另一个显示。选择后端可以通过 可以通过提供不正确的后端名称来获得受支持的后端列表:mat
-
计算Android中进程的CPU使用率
问题内容: 我正在尝试按以下方式计算Android中进程的CPU使用率,但是由于产生的输出,我不确定它是否正确。 要将吉菲转换为秒:吉菲/赫兹 第一步: 使用文件的第一个参数获取正常运行时间。 第二步: 从中获取每秒的时钟滴答数。 第三步: 从中获取过程参数花费的总时间 第四步: 从 Linux 2.6之后的时钟滴答声中除以sysconf(_SC_CLK_TCK)表示的值,获取进程的startti
-
计算机操作系统 - 进程管理
进程与线程 1. 进程 2. 线程 3. 区别 进程状态的切换 进程调度算法 1. 批处理系统 2. 交互式系统 3. 实时系统 进程同步 1. 临界区 2. 同步与互斥 3. 信号量 4. 管程 经典同步问题 1. 哲学家进餐问题 2. 读者-写者问题 进程通信 1. 管道 2. FIFO 3. 消息队列 4. 信号量 5. 共享存储 6. 套接字 进程与线程 1. 进程 进程是资源分配的基本单
-
Python科学计算之NumPy入门教程
本文向大家介绍Python科学计算之NumPy入门教程,包括了Python科学计算之NumPy入门教程的使用技巧和注意事项,需要的朋友参考一下 前言 NumPy是Python用于处理大型矩阵的一个速度极快的数学库。它允许你在Python中做向量和矩阵的运算,而且很多底层的函数都是用C写的,你将获得在普通Python中无法达到的运行速度。这是由于矩阵中每个元素的数据类型都是一样的,这也就减少了运算过
-
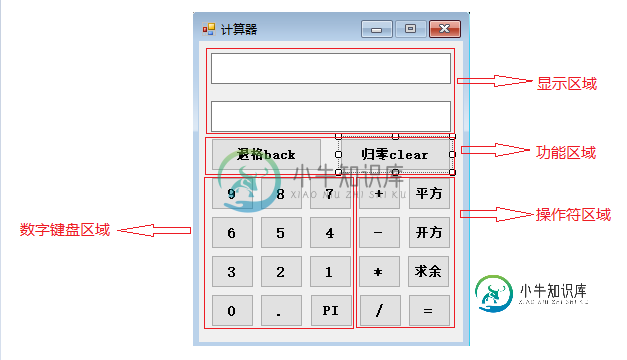 C#开发简易winform计算器程序
C#开发简易winform计算器程序本文向大家介绍C#开发简易winform计算器程序,包括了C#开发简易winform计算器程序的使用技巧和注意事项,需要的朋友参考一下 临近年关,今日在学习的过程中感觉甚是无聊,便想用C#来开发一个简易的计算器程序,这里记录下今日下午的实现过程,同时也记录下自己的第一遍博客。 一、需求 首先我们先来决定我们的计算器要实现什么功能 功能需求:1、能够实现加、减、乘、除、求余等两个操作数的运算,以及开
-
Java小程序计算圆周率代码
本文向大家介绍Java小程序计算圆周率代码,包括了Java小程序计算圆周率代码的使用技巧和注意事项,需要的朋友参考一下 下面我们来介绍两种Java编程中实现计算圆周率的方法。 方法一:割圆法 计算公式为: π≈3*2^n*y_n 其中,n代表割圆次数,y_n代表圆中内嵌正6*n边形的边长 输出结果: 方法二:无穷级数法 求圆周率π的级数公式为: Π=2*(1/1+1/3+1/3*2/5+1/3+2
-
如何计算程序的运行时间?
问题内容: 我写了一个程序,现在我想计算程序从头到尾的总运行时间。 我怎样才能做到这一点? 问题答案: 使用System.nanoTime获取当前时间。 上面的代码以纳秒为单位打印程序的运行时间。
-
计算存储过程返回的行数
问题内容: 如何计算存储过程将以最快的方式返回的行数。存储过程返回大约100K到1M记录的行。 问题答案: 选择: 执行存储过程后。
-
SCCM中计算机远程自动控制
我怎样才能自动打开一组远程控制会话并登录到每一个给定的计算机列表?
-
与编程相关的计算机硬件
不管是台式机还是笔记本,它们内部都有一块电路板,上面密密麻麻地布满了大小不一的电子器件,包括CPU、内存条、网卡、各种插槽和接口等,这就是“主板”,如下图所示。 这张图片主要让读者了解主板的构造,你不必理解图片中各个晦涩的名词。 图1:计算机主板CPU CPU (Central Processing Unit) 就是“中央处理器”,是计算机的大脑,负责计算、思考、处理数据、控制其他设备等,没有CP