《HPC高性能计算工程师》专题
-
Spring无功高负荷性能差
我有一个spring boot webflux应用程序,默认情况下使用Netty。其中一个业务需求,我们有要求,要求应超时在2秒内。 当很少的请求被发送到应用程序时,一切都很好,但是当请求负载增加时(比如Jmeter每秒并发超过40或50次),由于每个请求的时间超过2秒阈值,有时所有请求都会超时。 如果有人能告诉我该做什么,那将是一个巨大的帮助。在这一点上,我没有更多的改进,并认为我可能已经看错了
-
如何提高cassandra的写性能?
我有一个名为Emails的列族,我正在将邮件保存到这个CF中,编写5000封邮件需要100秒。 我使用的是i3处理器,8gb内存。我的数据中心有6个节点,复制因子=2。 我们存储在卡桑德拉中的数据大小会影响性能吗?影响写入性能的所有因素是什么,如何提高性能? 预先感谢..
-
JPA/Hibernate提高批插入性能
我有一个数据模型,在一个实体和11个其他实体之间有一对多的关系。这12个实体一起代表一个数据包。我遇到的问题是,在这些关系的“多”端发生的插入数量。其中一些可以有多达100个单独的值,因此要在数据库中保存一个完整的数据包,最多需要500次插入。 我在InnoDB表中使用MySQL 5.5。现在,通过对数据库的测试,我发现在处理批插入时,它可以轻松地每秒执行15000次插入(对于加载数据,插入次数甚
-
 php-ext-xlswriter 高性能 Excel 扩展
php-ext-xlswriter 高性能 Excel 扩展xlswriter 是一个高性能 PHP C 扩展,可用于读取、写入 Excel 2007+ xlsx 文件,适用于 Linux,FreeBSD,OpenBSD,OS X,Windows。
-
高性能JavaScript阅读简记(三)
Aligorithms and Flow Control 算法和流程控制 Loops 循环 a、避免使用for/in循环 在JavaScript标准中,有四种类型循环。for、for/in、while、do/while,其中唯一一个性能比其他明显慢的是for/in。对于for/in循环的使用场景,更多的是针对不确定内部结构的对象的循环。for/in会枚举对象的命名属性,只有完全遍历对象的所有属性之
-
高性能JavaScript阅读简记(二)
DOM Scripting DOM编程 我们都知道对DOM操作的代价昂贵,这往往成为网页应用中的性能瓶颈。在解决这个问题之前,我们需要先知道什么是DOM,为什么他会很慢。 DOM in the Browser World 浏览器中的DOM DOM是一个独立于语言的,使用XML和HTML文档操作的应用程序接口(API)。浏览器中多与HTML文档打交道,DOM APIs也多用于访问文档中的数据。而在浏
-
高性能JavaScript阅读简记(一)
Loading and Execution 加载和运行 早前阅读高性能JavaScript一书所做笔记。 从加载和运行角度优化,源于JavaScript运行会阻塞UI更新,JavaScript脚本的下载、解析、运行过程中,页面的下载和解析过程都会停下来等待,因为脚本可能在运行过程中修改页面内容。 Script Positioning 脚本位置 将<script>标签放在尽可能接近<body>标签底
-
 字节AML高性能一面凉
字节AML高性能一面凉面试了大概一个小时,先是自我介绍。 然后开始扯实习项目,感觉到这里聊得都还蛮好的,大概聊了四十多分钟,有计算库实习项目,和Transformer调研、部署量化和bert量化性能提升这些点。 最后十分钟出了个简单的二叉树题,因为自己没刷题,歪曲题意随便瞎做了,面试到点结束。 第二天出结果,挂
-
使用C11的“自动”能提高性能吗?
我明白为什么C 11中的类型提高了正确性和可运维性。我读到它也可以提高性能(赫伯·萨特的《几乎总是自动》),但我错过了一个很好的解释。 如何提高性能
-
8.3 为多线程性能设计数据结构
8.1节中,我们看到了各种划分方法;并且在8.2节,了解了对性能影响的各种因素。如何在设计数据结构的时候,使用这些信息提高多线程代码的性能?这里的问题与第6、7章中的问题不同,之前是关于如何设计能够安全、并发访问的数据结构。在8.2节中,单线程中使用的数据布局就会对性能产生巨大冲击(即使数据并未与其他线程进行共享)。 关键的是,当为多线程性能而设计数据结构的时候,需要考虑竞争(contention
-
欧氏距离的高效精确计算
问题内容: 继一些在线调查(1,2,numpy的,SciPy的,scikit,数学),我已经找到了计算的几种方法 在Python欧氏距离 : 我想知道是否有人可以就 效率* 和 精度 方面认为上述哪一项( 或我未找到的其他任何 理由)提供最佳见解。如果有人知道任何的 资源(S) ,其中讨论的主题,这也将是巨大的。 *** __ 的 背景下 ,我在有趣的是,在计算对数元组之间的欧氏距离,例如之间的距
-
无法正确计算itext pdfptable/pdfpcell高度
-
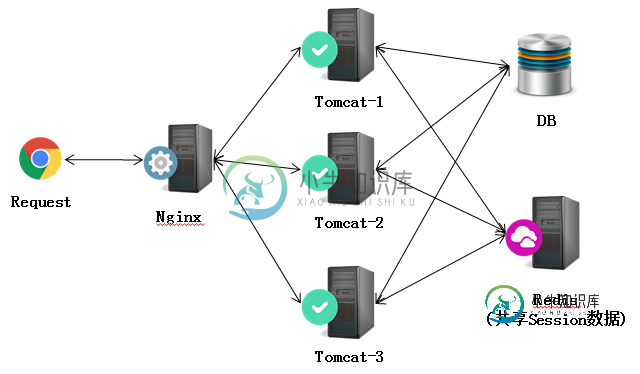 Nginx+Tomcat高性能负载均衡集群搭建教程
Nginx+Tomcat高性能负载均衡集群搭建教程本文向大家介绍Nginx+Tomcat高性能负载均衡集群搭建教程,包括了Nginx+Tomcat高性能负载均衡集群搭建教程的使用技巧和注意事项,需要的朋友参考一下 Nginx是一个高性能的HTTP服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其占有内存少,并发能力强,在同类型的网页服务器中表现较好。Nginx可以在大多数Unix Linux OS上编译运行,并有Windows移
-
如何提高单核cpu反应式编程的性能
我有一个连接到第三方服务并将结果返回给客户端的应用程序。在内部,应用程序向第三方服务发出GET请求并获取结果。我已经使用Reactor和reactive代码在重负载下扩展应用程序。这是一个SpringBoot项目,它运行嵌入式Tomcat并依赖于Web客户端(被动netty向第三方发出请求)。不知何故,CPU利用率和响应时间都比阻塞模式差。硬件设置在Kubernetes中运行单核。 该项目建立在库
-
IBM工作灯:UI性能
我使用jQuery Mobile 1.3进行Worklight 5.0.6开发。我发现一些功能,如过渡,面板和弹出菜单是不顺利的真实设备(三星银河S3 下面是测试应用程序的代码:Worklight,PhoneGap