《小马智行2023校招》专题
-
 喜马拉雅java后端一面
喜马拉雅java后端一面1.自我介绍 2.拷打实习 3.满sql优化 4.对反射的理解,什么场景适用,什么场景不适用 5.mysql各种隔离级别,还有优缺点,还有什么级别下有什么问题 6.写删除链表倒数第k个节点 关注边枝末节,什么头节点bb了半天 7.写两道sql employ(id,name,depatmentid,salary) depatment(id,name) 7.1输出所有员工数量不小于2的部门下的所有员工
-
 喜马拉雅一面 Java开发
喜马拉雅一面 Java开发#数据人的面试交流地# 接到了喜子面试 24届 Java开发实习岗 感觉凉透了 但是有二面 自我介绍 简历写了mysql优化 然后问了我相关的业务是这么优化的 when case 然后 事务插入 批量插入 这里我没说索引和只查必须列 然后小表驱动大表哪一些 我没说我优化之前的sql已经是这个样子了 就会想起来还是要说的 不然面试官以为不会这个 然后就问了mysql的索引 种类和区别 hash 全文
-
涂抹图像形成马赛克
在图像上用手指滑动涂抹,所经过的区域形成马赛克效果。可以自定义马赛克效果粗细程度(即马赛克方块的大小),以及涂抹形成马赛克的范围。 [Code4App.com]
-
 盒马java开发一面凉经
盒马java开发一面凉经发面经攒人品 电话面试,40min左右 1.讲一下MySQL事物的四个特性? ACID 没展开讲 2.介绍一下Java的ArrayList和LinkedList 有什么区别? 顺序表和双向链表 3.常用的java其他数据结构 hashmap concurrenthashmap 4.有什么区别? 讲了一下底层数据结构 5项目拷打 5.1为什么用图数据库? 详细讲了一下项目的架构和需求 5.2在你的项
-
 数字马力Java后端开发
数字马力Java后端开发状态:一面过,已约二面 一面 2024-04-22 25min ----------------- 1. 介绍时说go,简单说下go 2. 创建线程的方式 3. 守护线程 4. ArrayList和LinkedList的区别 5. 线程安全的hashMap 6. 堆区组成?年轻代进入老年代年龄?年轻代和老年代用什么回收算法? 7. 和jdk同包同名的hashMap,对系统的编译和运行有什么影响?
-
 jd young一面 抓马的面试
jd young一面 抓马的面试提前挂着会议,忘记关视频了,还有10min左右开始时面试官进了会议室,以前面试官不是卡点来吗,估计观察了我好一会了。到点之后发现听不到面试官声音,调了5min才调好,面试官已经有点不耐烦。开始提问。 1.用过ai吗,说说平常怎么使用的。 2.ai对我们的开发有哪些帮助,举具体的例子 3.自己的职业规划,反问我为什么要做JAVA开发,不去做算法。 4.讲自己的实习经历,开始吟唱 5.redis分布式
-
 阿里盒马Java实习面经
阿里盒马Java实习面经rt,昨天晚上7点半打电话给我说明天早上11点面试,早上11点接到座机杭州的电话,开始自我介绍,说明情况,深挖项目,面试总体时间30分钟,最后问基础问题,问题很简单,但是我回答不上,都忘记的差不多了(目前在实习,都没看八股文了),面试官很友善,面试完还给我的简历提意见,让我修改给阿里面试体验感10分吧最后问了我挂了,还能再投嘛,面试官说还在考虑过不过 #如何判断面试是否凉了#
-
在运行时设置JVM堆大小
问题内容: 有没有办法从正在运行的Java程序中设置堆大小? 问题答案: 没有。 对于具有非常多的堆需求的应用程序,您可以做的是设置最大的堆大小-Xmx并进行调整,以使堆缩小时该应用程序不会挂在大量内存上(使用默认设置即可) )。 但是请注意,当应用程序实际使用的内存变化剧烈且快速时,这可能会导致性能问题-在这种情况下,最好将其挂在所有内存上,而不是仅将其退还给操作系统以声明使用它再过一秒钟。您可
-
从小表中删除重复的行
问题内容: 我在PostgreSQL 8.3.8数据库中有一个表,该表上没有键/约束,并且有多个行,它们的值完全相同。 我想删除所有重复项,并且每行仅保留1个副本。 特别是有一列(称为“密钥”)可用于标识重复项,即,每个不同的“密钥”应该只存在一个条目。 我怎样才能做到这一点?(理想情况下,使用单个SQL命令。) 在这种情况下,速度不是问题(只有几行)。 问题答案:
-
PowerShell小技巧之执行SOAP请求
本文向大家介绍PowerShell小技巧之执行SOAP请求,包括了PowerShell小技巧之执行SOAP请求的使用技巧和注意事项,需要的朋友参考一下 SOAP的请求在Web Service是无处不在的,像WCF服务和传统ASMX asp.net的web Service。如果要测试SOAP服务是否好用通过web编程来实现就显得太过于复杂了,下面的脚本片段(snippet)将会轻而易举的完成通过po
-
Firebase在一小时后停止运行
Firebase在大约一个小时后停止连接到数据库并停止工作。如果我退出并重新登录,它的工作原理很好。这是使用谷歌和Facebook登录(目前为Facebook)。 我已经登录了,大约一个小时后,出现了这个: W/PersistentConnection:pc_0-提供的身份验证凭据无效。这通常表示FirebaseApp实例未正确初始化。确保你的谷歌服务。json文件具有正确的firebase_ur
-
旅行商最小生成树变体
我正在尝试解决下面的图形练习: 在一个无向加权图中,有V个顶点和E条边。从标记为0的顶点开始,求访问T(T<=v)个顶点所需的最小权值。另外,如果两个被访问的顶点之间存在边,则其权重设置为0。 编辑:我给你举个例子。假设我们有一个图,有4个顶点,标记为0,1,2和3。我们有以下边(from,to,weight):(0,1,1)(0,2,2)(1,3,4)(2,3,1)最小生成树将包含边:(0,1,
-
筛选值小于0的dataframe的行
我有一个像这样的熊猫数据框 我希望能够删除列列表中所有带负值的行,并使用NaN保存行。 在我的示例中,只有2列,但我的数据集中有更多的列,所以我无法逐个完成。
-
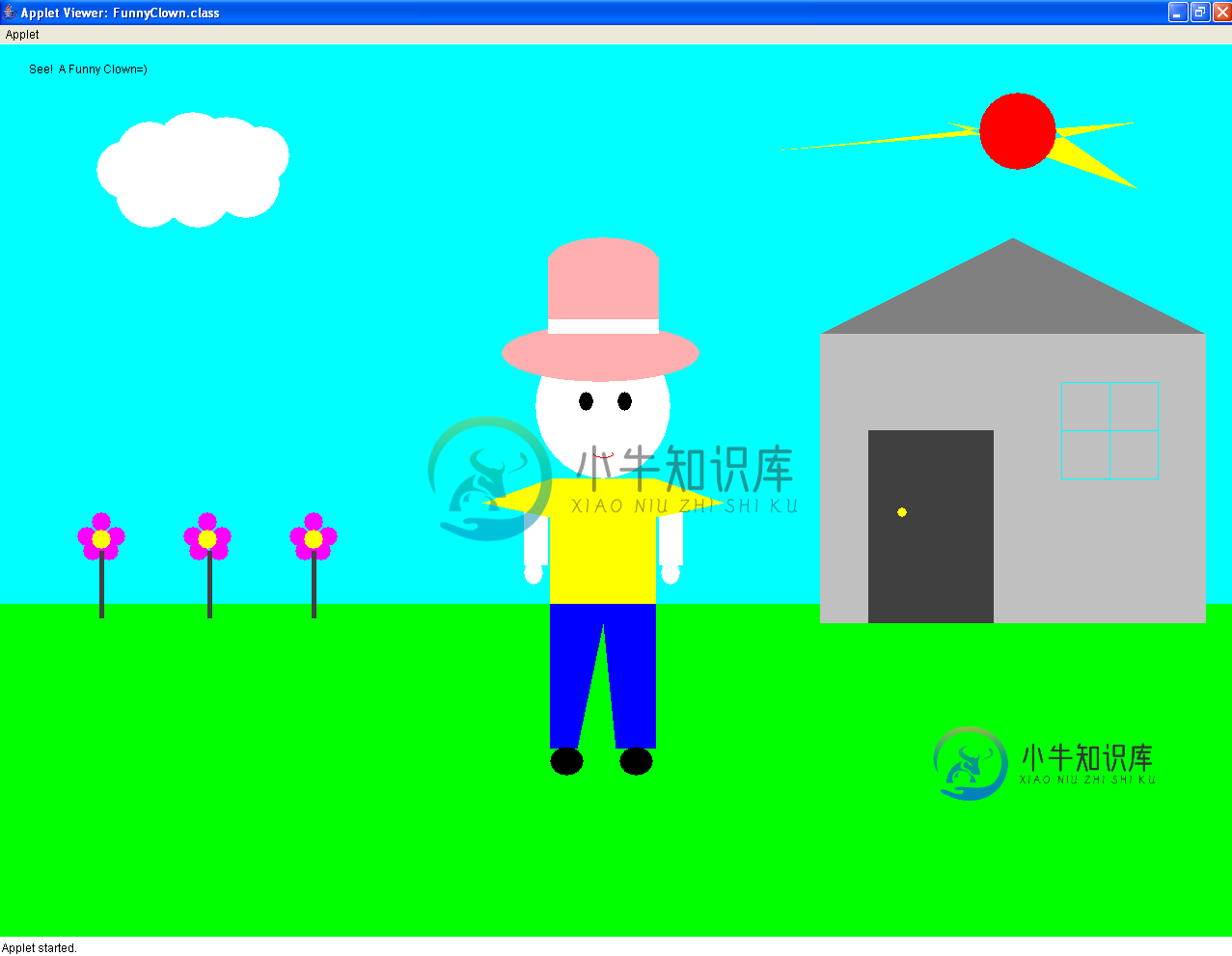 如何运行java小程序代码
如何运行java小程序代码我从未运行过Java代码,我想运行我将在下面发布的代码。有人能告诉我如何在Ubuntu上运行代码,包括我应该安装什么东西吗? 我还想修改它,把一个心脏图像放在这个家伙的胸前,写下我爱你。有人能帮我吗?
-
执行pyspark.sql.dataframe.take超过一个小时(4)
我在3个VM上运行Spark1.6(即1x主服务器;2x从服务器),它们都有4个内核和16GB RAM。 正如你所看到的,这需要很长的时间。我的表实际上相当大(存储了大约2.2亿行,每行11个字段),但是这样的查询可以立即使用“普通”sql(例如pyodbc)执行。 我想我没有理解/没有使用Spark,你会有这样的想法或建议来让它更好地工作吗?