《协议》专题
-
谷歌地图是否将地图与百度地图中的同一位置进行协调?
我正在使用latitude在百度地图(中国的主要地图服务)中实现一个地图视图 进行线性调整后,百度位置大致出现在正确的位置(几米): 虽然这可以满足我的特殊需要,但我不喜欢这些神奇的数字。有人知道这种抵消是从哪里产生的吗?
-
存储库模式——如何理解它,以及它如何与“复杂”实体协同工作?
我很难理解存储库模式。 关于这个主题有很多意见,比如在存储库模式中做得对,但也有其他东西,比如存储库是新的单例,或者像在不要使用DAO使用存储库或只是使用Spring JPA Data Hibernate MySQL MAVEN中,存储库似乎与DAO对象相同。 我已经厌倦了读这些东西,因为我知道这不会是一件很难的事情,因为它在很多文章中都有展示。 我是这样看的:看来我想要的是这样的: 获取对象并将
-
与spring-boot一起Rest:内容协商失败!类型的返回值找不到转换器
我试图使用spring-boot 2.1.9和spring Rest在浏览器上以JSON格式获取java POJO的内容。非常基本的例子!但我得到了这个帖子标题上显示的异常。当我用@XmlRootelement注释POJO类时,我会在浏览器上获得XML内容。但是,当我试图在浏览器上获取POJO列表时,我得到了与JSON相同的错误。为什么内容协商部分地适用于XML而根本不适用于JSON?谢谢你的每一
-
Paramiko/PysFTP连接失败,出现“协商失败/无效DH值”,但GUI和sftp连接失败
SSHException:协商失败。 是不是我错过了什么地方? 我最初假设问题是围绕hostkeys发生的,但是我得到了相同的结果,或者传递一个hostkeys文件,或者将hostkeys设置为None(使用pysftp) 这似乎发生在连接的早期,就好像我使用随机的用户名或密码,我得到的结果完全一样 调试信息如下: 如果我(成功)通过连接并启用了日志记录,我将获得以下日志:
-
python - 有什么办法可以和外部人员基于不同的 git 仓库协作吗?
有什么办法可以和外部人员基于不同的 git 仓库协作吗? 假设有一个仓库 crawler 在我们自己公司的 gitlab 上,我们有一些外包需要给我们的 crawler 添加更多的爬虫脚本和修复爬虫脚本,但是 gitlab 的权限不能给他们,所以就去 github 建了一个 crawler 仓库 但是问题来了 github 和 gitlab 之间怎么同步代码呢?因为两边的不是完全的镜像仓库,因为我
-
Tomcat应用程序Web.xml自定义过滤器,给出资源已移动的错误;过滤器将https重定向到超文本传输协议
仅供参考:我运行的是Windows Server 2008 R2版,使用的是IIS 7.5和Apache Tomcat 5.5。IIS通过AJP连接器1.3版与Tomcat对话。Tomcat启用了SSL因此,该网站同时支持HTTP和HTTPS流量。我在web.xml文件中还有一个安全约束,通过url-pattern重定向以强制特定文件的HTTPS流量。 说了这么多,我已经创建了一个servlet过
-
Python计算库numpy进行方差/标准方差/样本标准方差/协方差的计算
本文向大家介绍Python计算库numpy进行方差/标准方差/样本标准方差/协方差的计算,包括了Python计算库numpy进行方差/标准方差/样本标准方差/协方差的计算的使用技巧和注意事项,需要的朋友参考一下 使用numpy可以做很多事情,在这篇文章中简单介绍一下如何使用numpy进行方差/标准方差/样本标准方差/协方差的计算。 variance: 方差 方差(Variance)是概率论中最基础
-
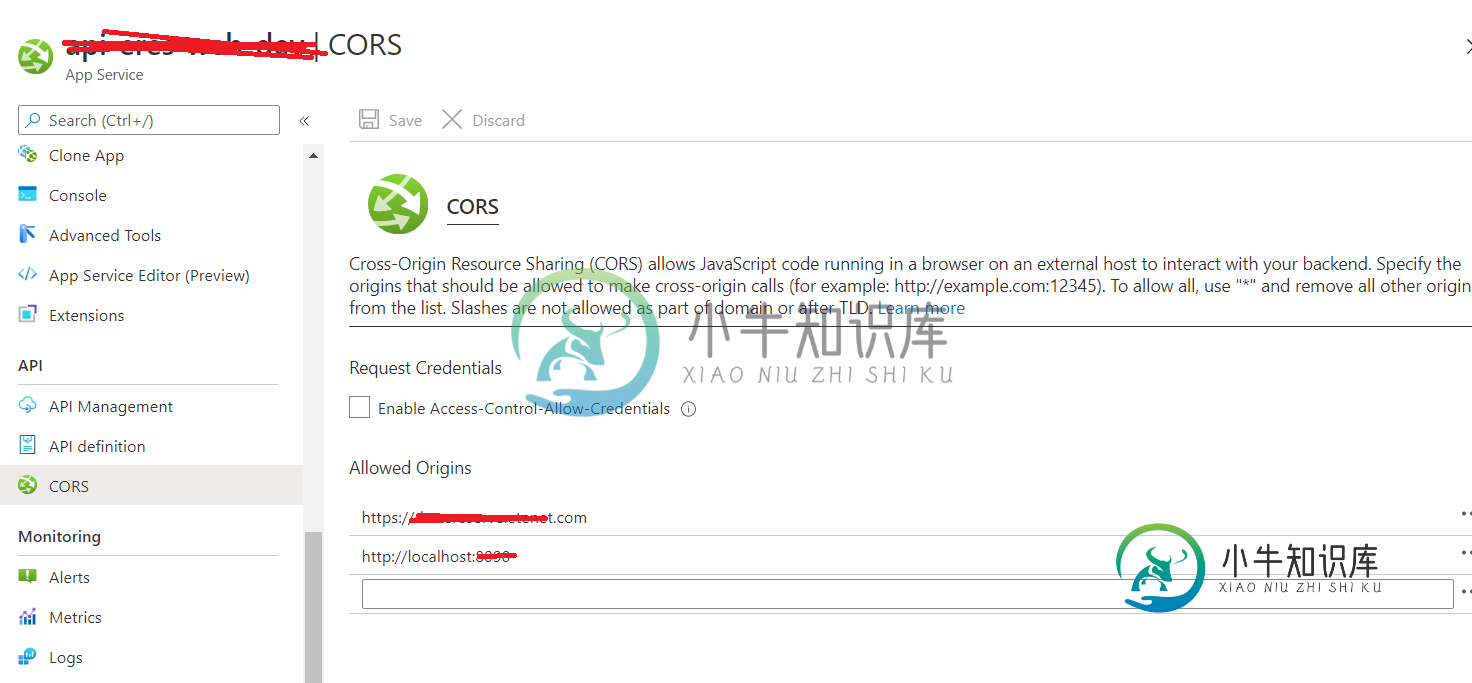 Angular应用程序无法与asp.net core的信号器安排进行协商。由于CORS错误
Angular应用程序无法与asp.net core的信号器安排进行协商。由于CORS错误我的statup.cs类代码如下: 在角度上,我创造了这样的连接: 此安排在本地工作,但部署时会导致CORS错误: 在'https://abc-api.com/lockNotification/negotiate?negotiateVersion=1“起源”https://abc-ui.com'已被CORS策略阻止:对飞行前请求的响应未通过访问控制检查:响应中的'access control Al
-
修复Bottom导航栏在其片段包含协调器布局时不断扩展的问题
我有底部导航栏活动,上面有一个片段。3个菜单中的1个,我有一个片段,使用协调器布局作为其父应用程序栏布局和折叠工具栏。有协调器布局不工作得很好,使底部导航栏自行扩展其高度。在这里,我提供了我的代码和一些屏幕截图。谢啦 这是我碎片布局的代码 下面是我的活动代码,底部有一个导航栏 这是它的活动java 这就是我的错误 这是我选择profile选项卡时出错的屏幕截图 我选侧写栏的时候它就拉屎了 谢谢:)
-
内容协商:如何从接受标题中提供最高排名类型以外的服务
我有这个SpringJava配置与几个自定义HttpMessageConverters: 如果我用Jena查询这个设置,我得到一个错误: 此请求标识的资源只能根据请求“接受”标头生成具有不可接受特征的响应 Jena发送带有此Accept标头的请求: 接受:文本/海龟,应用程序/n-三元组;q=0.9,应用程序/rdf xml;q=0.8,应用程序/xml;q=0.7,/;q=0.5 据我所知,,应
-
在Delphi汇编程序中,如何用`. align '协调短条件跳转和分支目标对齐?
如何在Delphi汇编程序中协调短条件跳转与分支目标对齐? 我使用Delphi版本10.2 Tokyo,用于32位和64位汇编,完全使用汇编编写一些函数。 如果我不使用,编译器会正确编码条件跳转指令(2字节指令,由1字节操作码和1字节相对偏移量组成 - 高达07Fh)。但是,如果我放一个,甚至小到 - 所有条件跳转指令都位于.align之前,目标位于之后 - 在这种情况下,所有这些指令都变成了6字
-
隐式评价和基于物品的过滤算法 - 基于用户/物品的协同过滤
目前为止我们描述的都是基于用户的协同过滤算法。我们将一个用户和其他所有用户进行对比,找到相似的人。这种算法有两个弊端: 扩展性 上文已经提到,随着用户数量的增加,其计算量也会增加。这种算法在只有几千个用户的情况下能够工作得很好,但达到一百万个用户时就会出现瓶颈。 稀疏性 大多数推荐系统中,物品的数量要远大于用户的数量,因此用户仅仅对一小部分物品进行了评价,这就造成了数据的稀疏性。比如亚马逊有上百万
-
尝试连接到Symantec NetBackup时,JSch中出现“算法协商失败”错误-远程获取报告
问题内容: 我一直在网上搜索,发现了类似的帖子,但是找不到阅读它们的解决方案。 我试图从计算机上使用ssh连接到NetBackup服务器,并运行报告并基于它们创建图形。我正在使用Java和JSch库执行此操作。问题是我得到: com.jcraft.JSch.Session.recieve_kexinit(…上的“算法协商失败” 我对协商和密钥以及diffie-hellman等不同方法知之甚少。请您
-
Goroutine是协作调度的。这是否意味着不执行的goroutine将导致goroutine逐一运行?
问题内容: 来自:http : //blog.nindalf.com/how-goroutines-work/ 由于goroutine是协同调度的,因此不断循环的goroutine会使同一线程上的其他goroutine饿死。 Goroutine很便宜,并且如果被阻塞,不会导致对其进行复用的线程阻塞 网络输入 睡眠 渠道运营或 阻塞sync包中的原语。 因此,鉴于以上所述,假设您有一些类似这样的代码
-
在空手道中,我们如何与BA协同工作来实现业务场景的自动化
在使用Karate时,我们能够对web服务进行大部分验证,我们能够成功地将Karate与Selenium webdriver集成,并使用java类进行DB断言。对于DB,我们通过将每一行转换为一个hashmap来返回结果集作为列表,而Karate则将其作为json数组。因此验证变得简单。我们在QA方面的大部分需求都是通过空手道来实现的。