《昆仑万维》专题
-
三维卷积神经网络输入形状
我在使用Keras和Python对3D形状进行分类时遇到了一个问题。我有一个文件夹,里面有一些JSON格式的模型。我将这些模型读入Numpy数组。模型是25*25*25,表示体素化模型的占用网格(每个位置表示位置(i、j、k)中的体素是否有点),因此我只有1个输入通道,就像2D图像中的灰度图像一样。我拥有的代码如下: 在此之后,我得到以下错误 使用TensorFlow后端。回溯(最后一次调用):文
-
拉维excel导出下载
如何在laravel 4下载数以千计的行excel。我使用Maatsite包。我得到以下错误。 [2016-10-20 11:22:00]当地。错误:异常“Symfony\Component\Debug\exception\FatalErrorException”,并显示消息“允许内存大小为524288000字节(已尝试分配4194304字节)”#0[内部函数]:lighting\exceptio
-
输入具有自定义维度的张量流或Keras神经网络
我想提供以下形状的神经网络输入:每个训练条目都是一个维度为700x10的2D数组。总共有204个训练条目。标签只是204大小的一维数组(二进制输出) 我试图只使用密集层: 但是我得到了以下错误(与第一层上的input\u形状无关,但在输出验证期间): 204-训练数据量。 堆栈跟踪: 调试Keras代码时发现: 培训前验证失败。它验证输出数组。 根据神经网络的结构,第一个密集层以某种方式产生700
-
具有极小极大值的三维Tic Tac Toe
我正在尝试用Alpha-beta剪枝来实现Minimax,这是一款3D Tic-Tac-Toe游戏。然而,该算法似乎选择了次优路径。 例如,你可以通过直接跑过立方体的中间或穿过单板来赢得比赛。人工智能似乎选择了下一轮最佳的细胞,而不是当前一轮。 我尝试过重新创建并使用我返回的启发式算法,但没有取得多大进展。不管是哪一层,它似乎都有同样的问题。 代码在这里。 相关部分是和(以及'2'变体,这些只是我
-
Keras:预期为3维,但得到了形状密集型阵列
我想基于使用TfidfVectorizer的矢量化单词进行多标签分类(20个不同的输出标签)。我已经设置了39974行,每行包含2739个项目(0或1)。 我想使用Keras模型对这些数据进行分类,该模型将包含1个隐藏层(~ 20个节点,激活='relu'),输出层等于20个可能的输出值(激活='softmax'以选择最佳拟合)。 以下是我目前的代码: 但有错误: ValueError:检查输入时
-
Keras中嵌入层和LSTM的三维阵列输入
嘿,伙计们,我已经建立了一个有效的LSTM模型,现在我正在尝试(不成功)添加一个嵌入层作为第一层。 这个解决方案对我不起作用。在提问之前,我还阅读了这些问题:Keras输入解释:输入形状、单位、批次大小、尺寸等,了解Keras LSTM和Keras示例。 我的输入是一种由27个字母组成的语言的字符的单键编码(1和0)。我选择将每个单词表示为10个字符的序列。每个单词的输入大小是(10,27),我有
-
为什么Keras Conv1D层的输出张量没有输入维?
根据keras文件(https://keras.io/layers/convolutional/)Conv1D输出张量的形状为(batch\u size,new\u steps,filters),而输入张量的形状为(batch\u size,steps,input\u dim)。我不明白这是怎么回事,因为这意味着如果你传递一个长度为8000的1d输入,其中batch\u size=1,steps=
-
Keras构建9维特征向量网络
我有以下简单的数据集。它由9个特征组成,是一个二元分类问题。特征向量的示例如下所示。每行都有相应的0,1标签。 我知道CNN被广泛用于图像分类,但我正试图将其应用于我手头的数据集。我正在尝试应用5个大小为2的过滤器。鉴于这些数据的形状,我一直致力于以正确的方式构建网络。这是我构建网络的功能。 最后,我还将调用一个测试函数来测试我创建的模型的准确性。下面的函数试图实现这一点 当我建立模型并通过训练函
-
Keras CNN错误:预期序列有3维,但得到了形状为(500400)的数组
我得到这个错误: ValueError:检查输入时出错:预期序列有3个维度,但得到了形状为(500400)的数组 以下是我正在使用的代码。 输出(这里每行有500行): 代码: 有什么见解吗?
-
批量标准化:按维度固定样本还是不同样本?
当我读到一篇论文《批量规范化:通过减少内部协变量转移来加速深层网络训练》时,我想到了一些问题。 在报纸上,它说: 由于训练数据中的m个样本可以估计所有训练数据的均值和方差,因此我们使用小批量来训练批量归一化参数。 我的问题是: 他们是选择m个示例,然后同时拟合批次范数参数,还是为每个输入维度选择不同的m个示例集? E、 g.训练集由x(i)=(x1,x2,…,xn)组成:固定批次的n维,执行所有拟
-
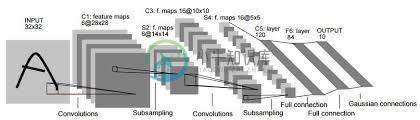 卷积神经网络特征图的维数计算
卷积神经网络特征图的维数计算我在Keras有卷积神经网络。我需要知道每个图层中要素地图的尺寸。我的输入是28 x 28像素的图像。我知道有一种计算方法,但我不知道如何计算。下面是我使用Keras的代码片段。 最后,这就是我想画的。非常感谢。
-
我什么时候想为TensorFlow卷积设置批处理或通道维度的步幅?
张量流用tf实现了一个基本的卷积运算。nn。conv2d。 我特别感兴趣的是“步长”参数,它可以设置卷积滤波器的步长——每次移动滤波器的距离。 早期教程中给出的示例是,每个方向的图像步幅为1 链接文档中详细介绍了跨步数组: 具体来说,使用默认的NHWC格式。。。 必须有步幅[0]=步幅[3]=1。对于最常见的相同水平和顶点步幅的情况,步幅=[1,步幅,步幅,1]。 注意,“跨步”的顺序与NHWC格
-
张量流卷积神经网络负维数
我正在制作这个CNN模型 ''' 但这是给我一个错误:-InvalidArgumentError:负尺寸造成的减去2从1'{{nodeconv2d_115/Conv2D}}=Conv2D[T=DT_FLOAT,data_format="NHWC",膨胀=[1,1,1,1],explicit_paddings=[],填充="VALID",步幅=[1,2,2,1],use_cudnn_on_gpu=t
-
三维卷积中输入图像的变化顺序
根据tf.keras.layers.Conv3D的官方留档 如果data\u format='channels\u first',带形状的5 D张量:batch\u shape(通道,conv\u dim1,conv\u dim2,conv\u dim3),如果data\u format='channels\u last',带形状的5 D张量:batch\u shape(通道,conv\u dim
-
如何使用批次规范化来规范化批次维度?
我想使用Batchnormalization来规范化批次维度,但keras中的批次维度自然是无维度的。那我该怎么办呢。 keras示例显示,conv2d的轴为-1,这表示通道尺寸。 轴:整数,应规格化的轴(通常是特征轴)。例如,在具有data\u format=“channels\u first”的Conv2D层之后,在BatchNormalization中设置axis=1。