《无人车规划算法实习》专题
-
 网易 伏羲 大模型算法实习 二面 速通
网易 伏羲 大模型算法实习 二面 速通26分钟速通,感觉面试官是个主管 1.自我介绍 2.拷打第一个项目,我的是一个RAG的项目,让我讲了一遍,然后问我团队分工、哪种优化方式提升指标最多? 3.拷打第二个项目,我的是一个论文项目,直接祭出共享屏幕讲论文的连招,讲完没怎么问问题 4.反问,我再问一遍部门做什么业务的,又说了一遍做智能npc的,鼠鼠连忙表现出巨大的兴趣 5.问我到岗时间、实习时长这种的,我祭出祖传话术;问我有没有面其他的,
-
 字节 暑期实习 多模态算法 (二面凉经)
字节 暑期实习 多模态算法 (二面凉经)个人背景可以看之前写的腾讯LLM面经 一面 2024/3/28 下午17:00-18:00 上来没有自我介绍 直接介绍NeurIPS论文,中间穿插着一些提问 说一下Transformer的整体结构 了解有哪些位置编码方式吗 说一下LLaMA中的旋转位置编码 算法题:经典的求平方根,牛顿迭代法秒了 算法题:判断一个字符串能否由另一个字符串旋转而来,比如abcd旋转后可以变成dabc或者bcda等,写
-
 蚂蚁暑期实习推荐算法岗面经(已挂)
蚂蚁暑期实习推荐算法岗面经(已挂)时间:4月12日11:00~11:50 先是确认了一下,做的是cv,为什么投推荐算法岗。 然后是自我介绍。 自我介绍完选择一个自己最拿手的项目进行讲解,期间问了问细节。 然后问基础知识: BatchNorm和LayerNorm的区别,为什么cv当中用BN而nlp当中用LN,具体的计算方式。 L1和L2的区别,为什么计算L1容易导致稀疏矩阵而L2不容易导致稀疏矩阵,这两个求导分别是什么。 auc的含
-
 字节商业化技术-算法实习一面凉经
字节商业化技术-算法实习一面凉经1.自我介绍 2.coding 数据流中位数,要求手写堆 手写注意力机制 问softmax公式 手写梯度下降求sigmoid(x)等于某个值高数都忘了,求导都不会,sigmoid也忘了,大家一起绷不住的笑了。 3.反问 太菜了不敢问,然后评价我coding可以,估计没啥夸的了。
-
 小米 大模型算法实习生 30分钟速通
小米 大模型算法实习生 30分钟速通1.自我介绍 2.介绍第二个RAG项目,没有反问我 3.介绍第一个论文项目,我直接共享屏幕讲的论文,没有反问我 4.代码题,不是传统的算法题,是手写深度学习模型的那种😭第一题是写mask self attention的代码,鼠鼠哪见过这阵势,根本写不出来,幸亏记得思路,就给面试官讲了思路;第二题是写出batch norm、layer norm、RMS norm区别,鼠鼠不会第三个,就讲了前两个的
-
 百度 NLP算法实习 一面 最难崩的一集
百度 NLP算法实习 一面 最难崩的一集全程45分钟,部门是百度文库策略部 这次是鼠鼠遇到过最难崩的一次,从跟面试官打招呼的时候我就感觉到这是kpi面,面试官是个女生,感觉年龄还没我大,声音感觉萎靡不振,估计是被逼着来面人的 因为这个是之前在实习僧投的,我当时上传了我的简历并且在系统里填了,结果那个简历文件看不到,面试官只能看到系统里填的,我系统里填了四个项目,难崩 1.自我介绍 2.介绍第一个项目,无提问 3.让我介绍第二个项目,无提
-
 网易 伏羲 大模型算法实习 一面面经
网易 伏羲 大模型算法实习 一面面经全程36分钟 1.自我介绍 2.拷打第一个项目,我的是一个论文项目,直接共享屏幕开讲,讲完面试官提了几个问题,主要是情绪流建模的必要性、为什么模型不和chatgpt比等 3.拷打第二个项目,我的是一个RAG的项目,我先详细讲了一下,然后开始问问题,第一个问了数据集构建的细节,第二个问了假如说想提高模型问答的效果,需要从那几个方面提升? 4.场景题,第一个问了对话场景中假如说用户问了一个问题,如何更
-
 滴滴秋储实习视觉算法岗一二面经。
滴滴秋储实习视觉算法岗一二面经。#算法# #视觉算法# #实习# 一面 时间八十分钟。 主要流程: 自我介绍 介绍项目,围绕项目展开提问和交流 长尾分布场景题。 手撕iou,nms,三数乘积。 关于多模态,大模型见解。 反问 二面 时间四十分钟 自我介绍 论文介绍以及项目介绍以及提问 手撕前序遍历递归非递归 优缺点 反问 ps:两位面试官都很nice!
-
 小米机器学习算法岗暑期实习一面
小米机器学习算法岗暑期实习一面1,自我介绍 2,项目不太相关所以没有过多问项目 3,编程题简单 4,常见的机器学习算法 5,特征归一化对树模型和神经网络的作用 6,神经网络防止过拟合的方法 7,线程和进程的区别
-
Bash中的文件名无法正确打印,并带有下划线“ _”
问题内容: 我正在用这个 我的输出是 但是如果我用 下划线代替 那我的输出是正确的 这是为什么? 问题答案: 是变量名的有效字符,并且不存在。
-
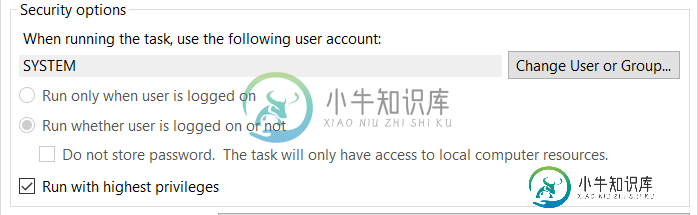 任务计划程序无法启动。附加数据:错误值:2147943726
任务计划程序无法启动。附加数据:错误值:2147943726我正在使用Windows 10任务调度程序来运行需要我使用我的个人用户帐户的任务(由于权限问题,必须使用我的用户而不是系统用户-我是组织的一部分)。在Windows 7计算机中,一切正常,但当我们升级到win 10时,我无法在不使用系统用户的情况下运行任务(如前所述,由于权限问题,它不起作用)。我得到以下错误 附加数据:误差值:2147943726 我在网上找到的只是一个使用系统用户的建议,除此之
-
重新启动计算机后,Eclipse无法启动
问题内容: 我的日食没有启动,因为我的计算机有点死机了,所以我不得不强制重新启动它。当我不得不重新启动时,Eclipse是打开的,我相信这很可能是原因。我不知道该如何解决。每当我尝试打开它时,它都会告诉我检查工作区中的.log文件,并显示: http://paste.strictfp.com/26579 而且我不知道如何解决它。请帮忙? 问题答案: 您缺少 第125行的 类,您必须重新安装才能解决
-
无法在DynamoDb查询中使用IN运算符
问题是我得到错误(过滤器表达式只能包含非主键属性:主键属性:名称)。租户是我的主分区键,名称是我的主排序键。 我需要在dynamo db中编写与此等效的内容:从项目中选择*,其中tenant='testProject',name in('John','Dave')。
-
无法连接到 jmeter 中的远程计算机
我正在尝试在远程机器中启动我的jmeter测试,因为我将在.jmx文件上运行批量用户(大约200 000线程)。我有一个远程机器,我已经下载了jmeter并将文件夹保存在桌面上。在命令提示符下,我有一个命令 现在在Jenkins我有一个指挥权 当我在詹金斯找到工作时 我在远程计算机中创建了一个 rmi 密钥库文件。
-
JavaScript算法-无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 示例 2: 输入: "bbbbb" 输出: 1 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 示例 3: 输入: "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是 "wke",