《无人车规划算法实习》专题
-
 星环科技ML算法岗无效面经
星环科技ML算法岗无效面经一二面是 8.12下午 一面40min 产品部门小姐姐 自我介绍 提场景让设计方案 手写一个简单程序 二面1h AI部门负责人(大概) 主要在聊RL 说今年刚开始招RL 最后反问岗位和部门对应关系 部门架构 终面8.16 和技术VP聊大模型 自己这方面了解不多 主要在听面试官介绍 反问新人培训 另外 笔试题是技术VP出的
-
Jenkins Dockerfile-无法准备上下文:无法计算Dockerfile中的符号链接
我在尝试使用“在Docker容器内构建”功能在Jenkins中构建一个项目时遇到了以下问题。 通过在工作区中构建用户用户名LastName开始/opt/bitnami/apps/jenkins/jenkins_home/jobs/app/workspace/opt/bitnami/Git/bin/Git rev-parse--is-inside-work-tree#timeout=10从远程Git
-
马尔可夫链算法(markov算法)的awk、C++、C语言实现代码
本文向大家介绍马尔可夫链算法(markov算法)的awk、C++、C语言实现代码,包括了马尔可夫链算法(markov算法)的awk、C++、C语言实现代码的使用技巧和注意事项,需要的朋友参考一下 1. 问题描述 马尔可夫链算法用于生成一段随机的英文,其思想非常简单。首先读入数据,然后将读入的数据分成前缀和后缀两部分,通过前缀来随机获取后缀,籍此产生一段可读的随机英文。 为了说明方便,假设我们有如下
-
iOS SpriteKit-碰撞和联系人无法按预期工作
问题内容: 有时在我的SpriteKit程序中,我的碰撞和接触(使用SKPhysicsBody)没有按预期触发或起作用。我想我已经设置了所需的一切,但仍无法获得正确的交互。我如何轻松检查将与建立碰撞的物体和物体建立碰撞? 问题答案: 为了帮助诊断这些类型的问题,我编写了一个可以在任何地方调用的函数,该函数将分析当前场景并生成一个列表,列出哪些节点与其他节点发生碰撞以及将通知我的场景发生哪些碰撞。
-
MongoDB-管理员无法成为root用户。“不是主人”
我在Mongo4.4实例(Ubuntu)上创建了一个管理员用户 然后,我尝试,它告诉我我不是“大师”。我读了这篇文章,人们建议我做,但它不工作! 它给我以下错误: 我必须卸载MongoDB,重新安装,然后创建根用户,然后创建管理员用户吗?
-
“本机字体无法制作”仅适用于某些人
我有一个应用程序,可以更改某些元素的字体。这对大多数人来说都很好,但可能有0.5%的人在尝试更改字体时会出现异常。堆栈跟踪的重要部分是: 正如我所说,它适用于大多数人,所以我认为这不是字体文件或我的代码的问题。关于如何解决这个问题,有什么建议吗? 编辑:这是我的代码:
-
FB messenger机器人无法获取回发有效负载
我正在开发一个facebook聊天机器人。我面临着一个我无法解决的问题。我正在拉维尔开发这个。在这里,我无法获取回发有效负载。这是我的密码 而我的路线是 这里的信息是有效的。但回发负载请求不会发送到服务器。另一方面,在普通的php文件中使用相同的代码,我能够获得回发的回报。 如何解决这个问题?有人能给我指条路吗?
-
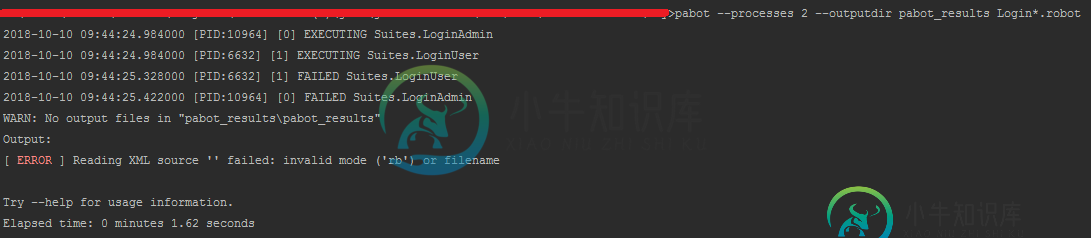 Pabot-无法运行并行的机器人框架测试
Pabot-无法运行并行的机器人框架测试所以,我正在进行一个robotframework测试项目,目标是并行运行多个测试套件。为此,选择了pabot作为解决方案。我正试图实施它,但收效甚微。 我的问题是:在安装了Pabot(我可以说,我是通过克隆项目并运行“setup.py install”来完成的,而不是使用pip,因为我背后的公司代理已证明是我无法克服的障碍),我在项目树中创建了一个新目录,将一些套件移到了那里,然后运行: pabo
-
获取Python错误“发件人:无法读取/var/mail/Bio”
我正在运行(bio)python脚本,该脚本导致以下错误: 由于我的脚本与邮件没有任何关系,我不明白为什么我的脚本要查看/var/mail。 这里有什么问题吗?我怀疑它是否会有帮助,因为脚本似乎不是问题所在,但这是我的脚本: 这里有什么问题?糟糕的python设置?我真的不认为这是剧本。
-
Kafka制作人创建主题但无法发送消息
我是斯卡拉和Kafka的新手,遇到了一些麻烦。 我正在尝试将scala kafka producer连接到安装在cloudera express服务器上的kafka服务器。我已经用这些指令在VMs中这样做过一次了,没有任何问题。 当我运行producer时,所需的主题被创建,但没有任何消息被发送,或者我是这样认为的。 Kafka制作人 当我执行run方法时,我看到“producer-send:#”
-
Kafka:本地制作人无法发送或接收消息
我试图使用谷歌云计算引擎VM实例作为Kafka消费者。我发现虚拟机阻止了来自任何外部计算机的通信,我成功地设置了防火墙规则,从本地计算机访问虚拟机。 我能够在云虚拟机实例上创建和列出主题。但我无法收发Kafka主题的信息。它抛出超时异常。 我使用telnet检查端口是否打开,并获得了端口的转义序列(9092)。 当我尝试使用另一个云虚拟机实例实现相同的事情时,我能够执行所有kafka操作。(发送/
-
无法安装聊天机器人。引发错误[重复]
我试图安装chatterbot,但我得到了以下错误,我试图降级到chatterbot==1.0.5,但它仍然提出了错误,给出错误,而安装依赖关系 请帮助我没有愚蠢的答案提前谢谢你!aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
-
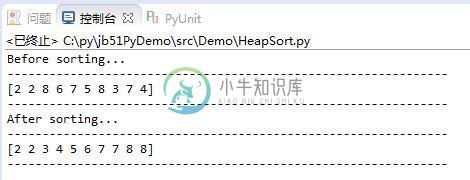 Python实现的堆排序算法原理与用法实例分析
Python实现的堆排序算法原理与用法实例分析本文向大家介绍Python实现的堆排序算法原理与用法实例分析,包括了Python实现的堆排序算法原理与用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现的堆排序算法。分享给大家供大家参考,具体如下: 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节
-
精心策划的传奇故事无法“存活”服务失败
假设您有两个不同的微服务(Customer和Account),它们都作为Spring Boot应用程序在Docker容器中运行。每次创建新客户时,也应创建相应的帐户。为了编排这个流程,我有第三个“服务”来实现基于编排的传奇逻辑。 传奇“服务”包含以下代码。 当所有服务都启动并运行时,一切正常。CustomerCreatedEvent由saga处理程序处理,并按预期激发CreateCountComm
-
生产中机器学习算法的实验设计
我已经准备好了机器学习算法。我想在一个拥有70个城市的国家将其投入生产。但在将其推广到 70 个城市之前,我想在 1 个城市进行实验,以评估它在生产中的性能。但是,我现在面临一个问题,如果出现以下情况,我应该设置什么标准:1. 时间(我可以将其投入生产多少个月)2.数据(在实时环境中我需要多少数据来评估算法性能) 任何人都可以在生产环境中指导此机器学习实验吗? 编辑:我正在将机器学习应用于美国的价