《自动驾驶计算机视觉算法实习》专题
-
 滴滴-视觉算法工程师-地图-24提前批-一面
滴滴-视觉算法工程师-地图-24提前批-一面大概为了照顾双非本同学的提前批参与感,滴滴给了面试机会 一面40分钟: 计算iou,大概是笔试中比较舒服的哪一种,并不是为了考察思维能力这些,大概就是经典题目慢慢优化,在优化中判断你的工程能力之类的。 项目:讲讲实习中做了什么,一问一答,大概就是这样。 表现比上次好一些,这次至少把实习做的东西将清楚了。不过感觉一直没有聊到面试官擅长的领域,挂的概率80%#提前批面试##如何判断面试是否凉了#
-
 实战-Swing实现计算器
实战-Swing实现计算器主要内容:1 Swing实现计算器1 Swing实现计算器 我们可以借助Swing的事件处理功能来开发Java计算器。让我们看看在Java中创建计算器的代码。 最终运行效果为: 点击下载完整计算器源码
-
我如何启动一个Twilio自动驾驶聊天会话,而不需要用户问候机器人?
-
 长安汽车视觉深度学习算法开发线下综合面
长安汽车视觉深度学习算法开发线下综合面1.自我介绍 2.说一下的你的缺点 3.加入长安你给长安带来什么? 4.你对加班怎么看 5.反问 多半无了,下午三点群面三个人一起,一起的都答的很好,二面技术应该没有了
-
 基于AngularJS实现iOS8自带的计算器
基于AngularJS实现iOS8自带的计算器本文向大家介绍基于AngularJS实现iOS8自带的计算器,包括了基于AngularJS实现iOS8自带的计算器的使用技巧和注意事项,需要的朋友参考一下 前言 首先创建angularjs的基本项目就不说了,最好是利用yeoman这个脚手架工具直接生成,如果没有该环境的,当然也可以通过自行下载angularjs的文件引入项目。 实例详解 main.js是项目的主要js文件,所有的js都写在这个文件
-
机器人计算自己的反应不一致。js
我一直在做一个反应菜单系统,基地是从我做的反应角色复制过来的东西,反应角色工作得很好,但当我把它复制到新的机器人时,机器人开始计算自己的反应,我不知道为什么,我没有改变任何过滤器 反应代码在下面
-
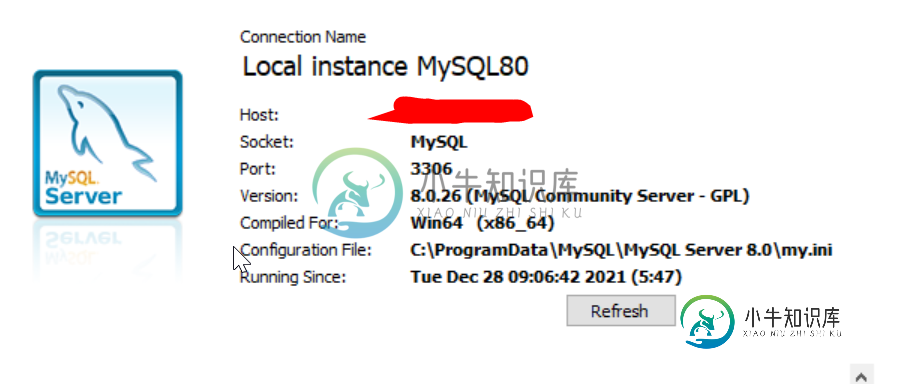 无法加载驱动程序类:com。mysql。希杰。jdbc。驾驶员
无法加载驱动程序类:com。mysql。希杰。jdbc。驾驶员我的Spring Boot项目正在尝试使用驱动程序连接MYSQL数据库。我已经导入了最新的mysql驱动程序和 我已经在文件中配置了数据库连接 MYSQL版本是8.0.26 Spring启动版本2.6.2 当用Intellij运行项目时,我得到一个错误 原因:org。springframework。豆。BeanInstationException:未能实例化[com.zaxxer.hikari.H
-
Java实现的计算最大下标距离算法示例
本文向大家介绍Java实现的计算最大下标距离算法示例,包括了Java实现的计算最大下标距离算法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java实现的计算最大下标距离算法。分享给大家供大家参考,具体如下: 题目描述 给定一个整形数组,找出最大下标距离j−i, 当且A[i] < A[j] 和 i < j 解法 复杂度:三次扫描,每次的复杂度O(N) 算法:{5,3,4,0,1,4,
-
 中国移动设计院 算法 一面
中国移动设计院 算法 一面腾讯会议 1104/10:30 大约十几分钟 两位面试官/一人提问 1.一分钟自我介绍 2.评价一下性格方面的优缺点 3.简单说一下对创新性与责任心的认识? 4.日常生活中最能体现你责任心的一件事情或一项工作? 5.场景题:阅读一段材料,回答两个问题(面试官投屏给你) 6.薪资期望是多少?
-
机器学习:感知机算法(PLA)
感知机可以理解为几何中的线性方程:w*x+b=0 对应于特征空间 R^n 中的一个超平面 S ,其中 w 是超平面法向量,b 是超平面的截距。这个超平面将特征空间划分为两个部分。位于两部分的点(特征向量)分别被分为正、负两类。
-
 vivo 图像/视频算法
vivo 图像/视频算法9.19线下一面 约30min 1.自我介绍 2.科研项目(原理,方法,结果对比,算法提升等) 3.实习经历(就在vivo工具组实习的,mtk视频算法,自动化调试原理,个人的主要工作和贡献) 4.反问 9.21 线下hr面 约20min 1.自我介绍 2.你在工具组实习的感受,和上司冲突怎么办 3.讲讲你对手机影像的理解(镜头,sensor,算法等) 4.你对你面试官的印象怎么样(一面的面试官可能
-
查询计算与编程计算
我正在使用Hibernate作为ORM进行Java EE项目,我已经到了一个阶段,我必须在我的类上执行一些数学计算,比如和、计数、加法和除法。 我有两个解决方案: 选择我的类并在代码中以编程方式应用这些操作 对命名查询进行计算
-
计算下个月开始日的算法
我正在写一个简单的日历课程。我正在尝试重载,以便使用它将日历移动到下个月。然而,我找到下个月开始日期的算法并不完全正确。 1月定义为0,12月为11,周日为0,周六为6。start Day、previousStartDay、nextStartDay、月份和年份都是私有类变量 当我在2013年进行测试时,日期直到3月都是正确的。在这一点上,它将下一个开始日定为周二,而不是周一。 我也试过: 然而,它
-
 android studio实现计算器
android studio实现计算器本文向大家介绍android studio实现计算器,包括了android studio实现计算器的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了android studio实现计算器的具体代码,供大家参考,具体内容如下 效果图: 资源文件: color.xml white.xml 设置input text的填充色为白色 selector.xml 点击按钮时产生阴影效果 equeal
-
无法计算出此算法的运行时间
我被要求为这个问题编写一个算法:给我们一个数组A,我们想知道数组中是否有两个元素U和L,U和L=K 我是这样写我的算法的: 但问题是,这个算法的运行时间是多少?它是O(nlogn)吗?如果是,为什么?如果不是,我如何在O(nlogn)中实现它?