《优化》专题
-
优化从s3 bucket中分区拼花文件的读取
我有一个拼花格式的大数据集(大小约1TB),分为2个层次:
-
 Android中ListView的几种常见的优化方法总结
Android中ListView的几种常见的优化方法总结本文向大家介绍Android中ListView的几种常见的优化方法总结,包括了Android中ListView的几种常见的优化方法总结的使用技巧和注意事项,需要的朋友参考一下 Android中的ListView应该算是布局中几种最常用的组件之一了,使用也十分方便,下面将介绍ListView几种比较常见的优化方法: 首先我们给出一个没有任何优化的Listview的Adapter类,我们这里都继承自B
-
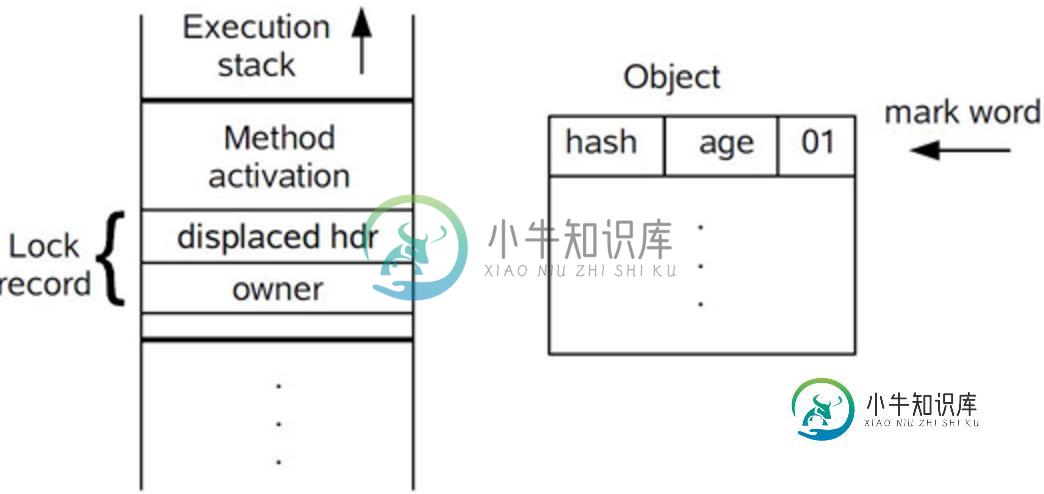 Java 并发编程学习笔记之Synchronized底层优化
Java 并发编程学习笔记之Synchronized底层优化本文向大家介绍Java 并发编程学习笔记之Synchronized底层优化,包括了Java 并发编程学习笔记之Synchronized底层优化的使用技巧和注意事项,需要的朋友参考一下 一、重量级锁 上篇文章中向大家介绍了Synchronized的用法及其实现的原理。现在我们应该知道,Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。但是监视器锁本质又是依赖于底
-
Oracle 表三种连接方式使用介绍(sql优化)
本文向大家介绍Oracle 表三种连接方式使用介绍(sql优化),包括了Oracle 表三种连接方式使用介绍(sql优化)的使用技巧和注意事项,需要的朋友参考一下 1. NESTED LOOP 对于被连接的数据子集较小的情况,nested loop连接是个较好的选择。nested loop就是扫描一个表,每读到一条记录,就根据索引去另一个表里面查找,没有索引一般就不会是 nested loops。
-
使用优化的约束间隔编译错误。关闭
我之前发布了一个类似的问题,这是固定的。然而,为了问这个问题,我简化了我最初的问题。但是,这个简单问题的解决方案似乎并没有解决我最初的问题 当我尝试这个简短的代码片段时,我尝试使用Interval.闭包类型从精炼库(https://github.com/fthomas/refined)约束一个Double类型,会产生一个编译错误。 显示此编译错误: 错误:(13,67)找不到参数v的隐式值:eu。
-
如何在PHP中优化指数移动平均算法?
我正在尝试检索大型数据集(15000个值)的最后一个EMA。这是一个非常消耗资源的算法,因为每个值都依赖于前一个值。这是我的代码: 我已经做了什么: 隔离$k,因此不会计算10000次 仅保留最新计算的EMA,而不是将所有EMA都保留在一个数组中 使用for()而不是foreach() $data[]数组没有键;这是一个基本阵列 这使我能够将15000个值的执行时间从2000ms减少到500ms左
-
C语言中三维直接卷积实现的优化
在我的项目中,我编写了一个简单的直接3D卷积C实现,在输入上使用周期性填充。不幸的是,由于我是C新手,所以性能不太好。。。代码如下: 按照惯例,所有矩阵(图像、内核、结果)都以列为主的方式存储,这就是为什么我以这种方式循环遍历它们,以便它们在内存中更近(听说这会有所帮助)。 我知道这个实现非常天真,但由于它是用C编写的,我希望性能会很好,但结果有点令人失望。我用大小为100^3的图像和大小为10^
-
使用x86/x64 Streaming SIMD扩展进行块匹配优化
这将是我发布的第一个问题! 我正在尝试使用Intel的SSE4优化立体视觉应用程序的“块匹配”实现。2和/或AVX内部函数。我用“绝对差之和”来寻找最佳匹配块。在我的情况下,blockSize将是一个奇数,例如3或5。这是我的C代码片段: 我知道,数据流单指令多数据扩展指令集包含许多指令,以便于使用SAD进行块匹配,例如mm\u mpsadbw\u epu8和mm\u SAD\u epu8,但它们
-
Keras中的"无法解释优化器标识符"错误
当我试图在Keras中修改SGD optimizer的学习率参数时,我遇到了这个错误。我是否在代码中遗漏了什么,或者我的Keras安装不正确? 这是我的密码: 下面是错误消息: 回溯(最后一次调用):文件“C:\TensorFlow\Keras\ResNet-50\test\u sgd.py”,第10行,在model.compile(loss='mean\u squared\u error',op
-
优化片段和顶点着色器之间的操作
我正在学习使用OpenGL制作图形引擎。我想知道,重复操作是否应该从顶点着色器移动到片段着色器,因为据我所知,顶点着色器每个顶点只运行一次? 例如,当规格化灯光方向的向量时,由于该灯光在整个顶点中相同,是否应将其移动到顶点着色器,而不是为每个像素计算它?在着色器中保留片段有什么特别的原因?
-
如何量化优化tflite模型的输入和输出
我使用以下代码生成量化的tflite模型 但是根据训练后量化: 生成的模型将完全量化,但为了方便起见,仍然采用浮点输入和输出。 要为Google Coral Edge TPU编译tflite模型,我还需要量化输入和输出。 在模型中,我看到第一个网络层将浮点输入转换为,最后一个网络层将转换为浮点输出。如何编辑tflite模型以除去第一个和最后一个浮动层? 我知道我可以在转换期间将输入和输出类型设置为
-
使用多个子拓扑优化Kafka Streams应用程序
我正在运行一个Kafka Streams应用程序,它有三个子拓扑。活动的阶段大致如下: 主题A 主题A、B和C都是物化的,这意味着如果每个主题有40个分区,我的最大并行度是120。 起初,我运行5个流应用程序,每个线程8个。在这种设置下,我遇到了不一致的性能。似乎某些共享同一线程的子拓扑比其他子拓扑更渴望CPU,过了一会儿,我会得到这个错误:组[consumer_group]中的中删除。一切都会重
-
如何优化hadoop作业中的洗牌/排序阶段
我正在使用单个节点hadoop作业做一些数据准备。我的作业中的映射器/组合器输出许多键(超过5M或6M),显然作业进行得很慢,甚至失败。映射阶段最多运行120个mapper并且只有一个reducer(这些是自动确定的,我没有为它们设置任何值)。我想优化作业,使洗牌/排序阶段更有效地发生。我将增加到300M,但作业失败了,因为它的值大于映射器堆。然后我将设置为-xmx1024m,但它再次失败,因为它
-
如何在不调用System.gc()的情况下优化内存;
谢谢
-
为什么不对类内存类型执行tailcall优化?
如果类型具有类内存,则调用方为返回值提供空间,并将此存储的地址传递到%RDI中,就像它是函数的第一个参数一样。实际上,这个地址成为一个“隐藏”的第一个参数。此存储区不得通过此参数以外的其他名称与被调用方可见的任何数据重叠。 返回时,%RAX将包含调用方在%RDI中传入的地址。 考虑到这一点,下面的(愚蠢的)函数: 不用说,对于SSE类的类型(例如,只有2个和不是3个doubles),会执行尾调优化