《货拉拉》专题
-
Python SCIKIT-镜像拉请求Travis CI Python 2.7构建失败
我试图提交pull请求,但Travis构建在python 2.7下失败: 安装可选依赖项+[[2.7!=3.2*]] +PIP安装--重试3-q-r./optional_requirements.txt--no-index--trusted-host travis-wheels.scikit-image.org--find-links=http://travis-wheels.scikit-ima
-
如何从卡桑德拉的八卦中删除节点
我们有3个节点cassandra集群,我们添加了一个节点并停止了集群中的另一个节点。因为我们认为一切都很好,但我们开始看到提示表正在增长。 我们发现我们犯了一个错误,并从集群中删除节点,但仍然当我们运行nodetool八卦信息时,它会显示删除节点,但它的节点没有显示在状态命令中。 问题是什么,我们仍然看到提示表在增长。我们不知道集群发生了什么,2到3天没有错误,突然一个种子节点出现OOM错误。 j
-
从卡桑德拉接收已经准备好的声明
我并不完全理解预准备语句的概念,但是根据python驱动程序文档,预准备语句是< code >“针对至少一个Cassandra节点准备的语句”。对我来说,在集群中的某个地方有关于已经准备好的查询的信息。该文档还规定< code >“prepared statement应该只准备一次。重新准备语句可能会影响性能(因为该操作需要网络往返),"。 如果我的概念是正确的,那么从集群中接收已经准备好的语句而
-
在卡桑德拉中存储架构较少的数据
我正在创建一个用于审计我的web应用程序的应用程序。所以我想在CASSANDRA db中存储所有审计日志,数据不是预定义的,我们要存储到db中的内容,基本上应该存储到一个无模式的db中。那么我们如何将它存储到卡珊德拉。请帮帮我。
-
使用批处理语句插入到卡桑德拉中
我正在使用批处理语句将来自csv文件的数据插入到卡桑德拉中。我的表格看起来像这样创建表格曝光(暴露比金特,文件比金特,研究文本,项目文本,w文本,x文本,y文本,z文本) 将所有Cassandra表colNames作为键,它们的值在地图中如下所示 makeSt方法准备预处理语句 这一切都很好。然后我做以下事情 当我运行程序时,我收到以下错误 程序中断的确切行是第486行,也就是 我正在使用Data
-
复合卡桑德拉键在Spring启动应用程序
我有一个卡桑德拉集群,使用以下方法创建: 我使用的Eclipse版本如下: 现在,我编写了以下实体: 因为该表使用复合主键,所以我必须使用下面提到的结构:http://docs.spring.io/spring-data/cassandra/docs/1.0.2.RELEASE/reference/html/cassandra.core.html 所以我的活动密钥类是这样的: 我的控制器是这样的:
-
如何修剪引导下拉菜单以适应内容?
我有有限的网站编码经验。我正在尝试将bootstrap实现到我的站点中,特别是通过使用它创建一个navbar。它的工作很好,除了当我舔下拉菜单的登录按钮,菜单显得太宽的内容。我使用css样式表将用户名和密码表单对齐到下拉菜单的右侧,但表单的左侧仍然有太多空格。 例如,我更希望它减少到“新闻通讯”按钮的开头。 站点可以在这里找到:my_test_site 代码:
-
Azure DevOps Rest API-按标记/标签列出拉取请求
有没有什么方法可以查询Azure DevOps的REST API来返回给我一个带有特定标记/标签的拉请求列表? 在没有什么帮助的情况下查看了这里的文档:https://docs.microsoft.com/en-us/rest/api/azure/devops/git/pull%20requests/get%20pull%20requests?view=azure-devops-rest-6.0
-
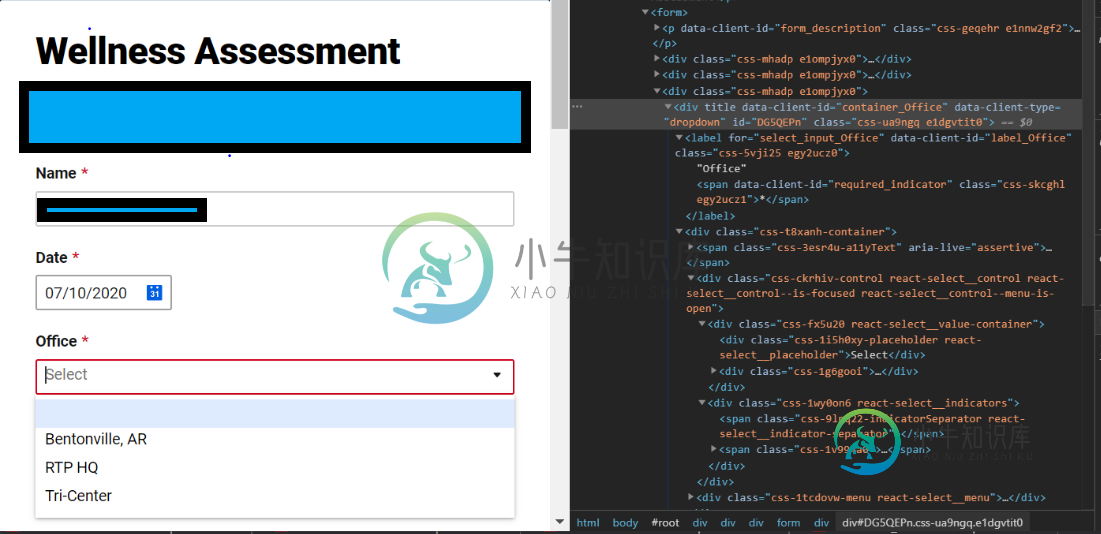 如何使用div标记/类下拉选择选项?.selenium
如何使用div标记/类下拉选择选项?.selenium我已经尝试了所有可能的事情。此外,尝试搜索尝试不同的组合和变化。我可以点击打开下拉列表的元素。但我无法在其中选择一个选项。我尝试了actions、sendkeys、keys.down/enter和多个东西。然而,这无济于事。那是我唯一被困住的东西。 //选择办公室 1.driver.findElement(by.id(“dg5qepn”)).click(); Actions Actions=新操作
-
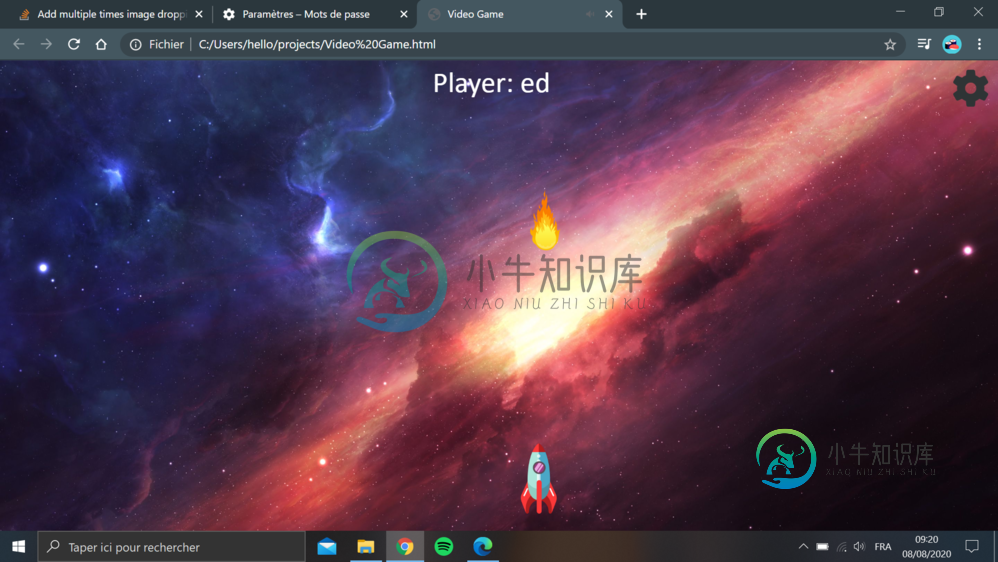 添加多次图像下拉屏幕(视频游戏js)
添加多次图像下拉屏幕(视频游戏js)但是我想做的不是只有一个图像(火球)下屏,我想有一堆图像下屏。 以下是火球的代码: 和图像: 谢了!
-
 ExoPlayer-奇怪的阿拉伯语/波斯语字幕格式
ExoPlayer-奇怪的阿拉伯语/波斯语字幕格式我正在尝试创建一个带有字幕的视频播放器。除了一件事,一切都设置好了,工作正常。我的阿拉伯语字幕显示不正确。他们用符号之类的东西看起来很奇怪。。比如: 以下是我的ExoPlayer设置和子倾斜: 有什么解决办法吗?
-
如何进一步优化埃拉托斯特尼筛网
我正在解决Project Euler问题10,我可以使用Eratosthenes Sieve来完成,但现在我想进一步优化代码。 考虑到所有大于3的质数都是< code>6k 1或< code>6k-1的形式,我只将数组中的那些值设置为真,但并不是所有这种形式的数都是质数,所以我必须筛选这些值并删除非质数,我的代码如下: 那么,我怎样才能优化我筛选出的较少数字的代码呢?例如,如果我的数字是5,那么像
-
提高红宝石中埃拉托色尼筛的效率?
下面是我对埃拉托色尼筛的实现,以找到达到上限参数的质数。 目前,当我的参数为 2,000,000 时,我的代码将在大约 2 秒内完成。我看到我正在通过将数字设置为零来做一个额外的步骤,然后压缩而不是一步删除这些数字。 我将如何着手实现这一点?你还有其他提高我的代码速度的建议吗?
-
筛选埃拉托色尼素数高达一百万c
所以我的代码需要帮助。由于某种原因,当我输入超过500,000的数字时,它总是崩溃。这是确切的分配。 实现埃拉托斯特尼筛,并用它来查找所有小于或等于一百万的素数。使用结果来证明哥德巴赫猜想对于 400 万到 100 万之间的所有偶数(包括 100 万)。 使用以下声明实现函数: 此函数采用整数数组作为其参数。数组应初始化为值 1 到 1000000。该函数修改数组,以便仅保留质数;所有其他值均归零
-
埃拉托斯特尼筛子程序的分割故障
我正在尝试实现筛选算法,它会询问连续数字列表的大小,并打印出该列表中的素数,但我收到了一个seg错误:11错误。 这是我的代码: