《运筹优化》专题
-
优化多个文件的并行处理
我有一个处理大量文件的程序,其中每个文件需要做两件事:首先,读取并处理文件的一部分,然后存储生成的MyFileData。第一部分可以并行,第二部分不能并行。 按顺序做每件事都非常慢,因为CPU必须等待磁盘,然后工作一点,然后发出另一个请求,然后再次等待。。。 我做了以下事情 这很有帮助。然而,我想改进两件事: > 以固定顺序执行,而不是首先处理任何可用的结果。如何更改它? 有数千个文件需要处理,启
-
优化抽屉和活动启动速度
我正在使用谷歌抽屉布局。 当一个项目被点击时,抽屉被顺利关闭,并且会启动一个。将这些活动变成不是一个选项。正因为如此,启动一个活动然后关闭抽屉也不是一个选项。关闭抽屉和同时启动活动会使关闭动画结巴。 鉴于我想先顺利关闭它,然后启动活动,我对用户单击抽屉项目和他们看到他们想要去的活动之间的延迟存在问题。 这就是每个项目的单击侦听器的外观。 我的活动也是DrawerListener,它的方法如下所示:
-
使用并行化优化批量更新
我有一个用于将实时数据移动到测试环境中的事务数据置乱的过程。该表包含大约一亿行,分布在50个分区中。每月添加一个新分区。随着音量的增加,过程的执行速度比以前慢。 我正在考虑在我的代码中引入某种程度的并行化。这是一个新领域,我想知道是否有任何最佳实践。也许使用dbms_parallel_execute将更新拆分为块? 任何关于如何优化我的代码的建议都非常感谢! 编辑,我的解决方案基于以下反馈:重写部
-
高内聚力和松耦合的优化
在一次技术采访中,我被问及项目的凝聚力和耦合性。我详细解释了它们的定义,尽管我没有像他说的那样正确回答问题的第二部分。 “我们如何在一个项目中同时实现高度内聚和松散耦合的设计,请解释这种方法应该如何在一个整体项目中实现?” 我回答说这两个目标是矛盾的,所以我们需要找出每个项目或模块的最佳选择,但我无法提供全面的答案。 如果有人能帮我,我将不胜感激。
-
C#编译器会优化此代码吗?
我经常遇到这种情况。乍一看,我认为,“这是糟糕的编码;我正在执行一个方法两次,必然会得到相同的结果。”但想到这里,我不得不怀疑编译器是否像我一样聪明,并能得出相同的结论。 编译器的行为是否取决于 方法的内容?假设它看起来像这样(有点类似于我现在的真实代码): 除非对这些对象来自的任何存储进行处理不当的异步更改,否则如果连续运行两次,肯定会返回相同的内容。但是,如果它看起来像这样(为了论证而无意义的
-
启用优化会导致权限问题
我在Windows 10中使用cmake构建了一个C项目(Visual Studio 2019,尽管它只使用了构建工具而不是GUI,实际使用的编译器是clang)。如果我在没有编译器优化的情况下构建它,它会构建得很好,但是如果我使用< code > set(CMAKE _ CXX _ FLAGS _ RELEASE“-O3”)传递< code>-O3,那么编译后的二进制文件会有某种权限问题。cte
-
使用MySQL查询或javascript优化数据
我在mysql中有这些数据。 我想调整数据并将其发送到json使用节点js / expressjs与每日,每月,每年的总和。 首先我尝试这个查询。 这个查询运行良好。但我认为这是浪费。因为反复查询代码数量。 输出: 我可以用一个查询获取所有数据吗? 最后,我想用Expresjs发送这种形式的数据。 或此表单 我尝试过mysql查询,sequelize,洛达什。但我找不到正确的方法。
-
全局常数优化和品种介位
我在用gcc和clang做实验,看看它们是否可以优化 以返回中间常量。 事实证明,他们可以: 但是令人惊讶的是,移除静态输出会产生相同的汇编输出。这让我很好奇,因为如果全局变量不是< code>static,它应该是可插值的,用中间变量替换引用应该可以防止全局变量的插值。 的确如此: 产出 编译器可以用中间变量替换外部全局变量的引用吗?这些不也应该被干预吗? 编辑: Gcc 不会优化外部函数调用(
-
用Spark优化配置单元SQL查询?
我对这些技术的理解是否正确?
-
VS:_BitScanReverse64内部的意外优化行为
以下代码在调试模式下工作良好,因为_BitScanReverse64被定义为如果未设置位则返回0。引用MSDN:(返回值为)“如果已设置索引,则为非零;如果未找到设置位,则为0。” 如果在发布模式下编译此代码,它仍然可以工作,但是如果启用编译器优化,例如\o1或\o2,则索引不为零,将失败。 这是故意的行为吗?我正在使用Visual Studio Community 2015,版本14.0.254
-
如何在python中对此进行优化?
我想找到配对的数量,一个很大的数字。如果我给数字n,并要求确定配对的数量,这样 <代码>S(x) 而constants是
-
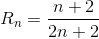 PHP解释器代码中的微优化
PHP解释器代码中的微优化由于在这个so线程上遇到了困难,我决定用PHP编写类似的测试。我的测试代码是这样的: 在PHP版本中运行与非常相似, 因此PHP解释器没有像Java中的JVM那样优化字节码 即使在我手动优化代码的时候--我也有~的加速比,而Java的版本有~的加速比。所以PHP版本的加速系数是Java代码的1/2。 我不想多说细节,但优化和未优化代码的乘法比是-> 1求和:3/4 2求和:4/6 3求和:5/8
-
Yen优化Bellman-Ford算法的正确性
我试图解决算法简介中的问题24-1,它指的是Yen对Bellman Ford algirithm的优化,我在wiki中找到了介绍,改进: Yen的第二个改进首先在所有顶点上分配一些任意的线性顺序,然后将所有边的集合划分为两个子集。第一个子集Ef包含所有边(vi, vj),使得i 不幸的是,我不能证明至少两个边松弛距离的方法如何匹配正确的最短路径距离:一个来自Ef,一个来自Eb。
-
优化。NET POCOs的JSON序列化性能
我一直试图优化要导入到MongoDB中的超过500k个POCO的JSON序列化,但除了头痛之外什么也没有遇到。我最初尝试了Newtonsoft json.convert()函数,但这花费了太长时间。然后,根据SO、NewtonSoft自己的站点和其他位置上的几篇文章的建议,我尝试手动序列化这些对象。但没有注意到太多,如果有任何业绩增益。 这是我用来启动序列化过程的代码...在每行上面的注释中,是给
-
Apache Beam/Dataflow中重复转换的优化
我想知道Apache Beam.Google DataFlow是否足够聪明,能够识别数据流图中的重复转换,并只运行一次。例如,如果我有2个分支: null