《志翔科技》专题
-
结合日志条目和logstash
问题内容: 我想从dnsmasq收集和处理日志,因此决定使用ELK。Dnsmasq用作DHCP服务器和DNS解析器,因此它为这两种服务创建日志条目。 我的目标是将所有包含请求者IP,请求者主机名(如果有)和请求者mac地址的DNS查询发送到Elasticsearch。这样一来,无论设备IP是否更改,我都可以按mac地址对请求进行分组,并显示主机名。 我想做的是以下几点: 1)阅读以下条目: 2)临
-
Python解析nginx日志文件
本文向大家介绍Python解析nginx日志文件,包括了Python解析nginx日志文件的使用技巧和注意事项,需要的朋友参考一下 项目的一个需求是解析nginx的日志文件。 简单的整理如下: 日志规则描述 首先要明确自己的Nginx的日志格式,这里采用默认Nginx日志格式: 其中一条真实记录样例如下: 其中,客户端型号信息用XXXXXXX代替。 项目中已经按照业务规则对Nginx日志文件进行了
-
Uvicorn/FastAPI重复日志记录
我的FastAPI应用程序似乎记录了很多事情两次。 这包括引发的任何异常,您将两次获得整个堆栈跟踪。我已经看到一些答案建议删除Uvicorn的日志处理程序,但这感觉是错误的。如果在堆栈的Uvicorn层发生日志事件,但在FastAPI中没有,该怎么办? 有没有一种方法可以只获取一次日志输出,而不只是覆盖uvicorn的日志处理程序?
-
DBMS基于日志的恢复
主要内容:使用日志记录恢复DBMS基于日志的恢复 - 日志是一系列记录。 每个事务的日志都保存在一些稳定的存储中,以便在发生任何故障时,可以从那里恢复。 如果对数据库执行任何操作,则它将记录在日志中。 但是,应该在数据库中应用实际事务之前完成存储日志的过程。 假设有一项事务,它执行修改学生所在的城市。 为此事务编写以下日志。 启动事务时,它会写入“启动”日志。 当事务城市从“Haikou”修改为“Shanghai”时,则会
-
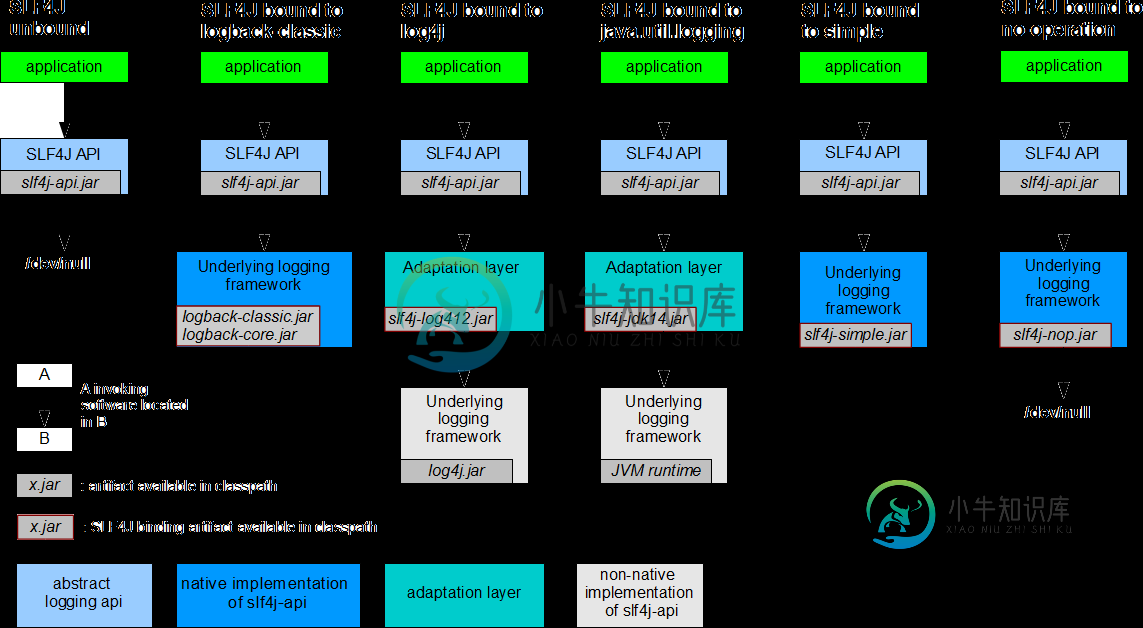 Spring Boot统一日志框架
Spring Boot统一日志框架主要内容:日志框架的选择,SLF4J 的使用,统一日志框架(通用),统一日志框架(Spring Boot)在项目开发中,日志十分的重要,不管是记录运行情况还是定位线上问题,都离不开对日志的分析。在 Java 领域里存在着多种日志框架,如 JCL、SLF4J、Jboss-logging、jUL、log4j、log4j2、logback 等等。 日志框架的选择 市面上常见的日志框架有很多,它们可以被分为两类:日志门面(日志抽象层)和日志实现,如下表。 日志分类 描述 举例 日志门面(日志抽象层)
-
SELinux auditd日志使用方法
主要内容:audit2why命令,audit2allow命令,sealert命令auditd 会把 SELinux 的信息都记录在 /var/log/auditd/auditd.log 中。这个文件中记录的信息会非常多,如果手工查看,则效率将非常低下。比如笔者的 Linux 中这个日志的大小就有 386KB。 [root@localhost ~]# ll -h /var/log/audit/audit.log -rw-------.1 root root 386K 6月 5
-
Linux日志服务器设置
我们知道,使用“@IP:端口”或“@@IP:端口”的格式可以把日志发送到远程主机上,那么这么做有什么意义吗? 假设我需要管理几十台服务器,那么我每天的重要工作就是查看这些服务器的日志,可是每台服务器单独登录,并且查看日志非常烦琐,我可以把几十台服务器的日志集中到一台日志服务器上吗?这样我每天只要登录这台日志服务器,就可以查看所有服务器的日志,要方便得多。 如何实现日志服务器的功能呢?其实并不难,不
-
Linux日志文件及功能
日志文件是重要的系统信息文件,其中记录了许多重要的系统事件,包括用户的登录信息、系统的启动信息、系统的安全信息、邮件相关信息、各种服务相关信息等。这些信息有些非常敏感,所以在 Linux 中这些日志文件只有 root 用户可以读取。 那么,系统日志文件保存在什么地方呢?还记得 /var/ 目录吗?它是用来保存系统动态数据的目录,那么 /var/log/ 目录就是系统日志文件的保存位置。我们通过
-
android删除WebView调试日志
就像这个 这个能去掉吗? 我尝试使用Proguard删除日志,但只删除了我的日志。WebView日志仍然存在。 编辑:这与过滤日志无关。我不希望有人在运行我的应用程序时看到日志,这更难破解。
-
Java SDK的log4j2日志记录
假设我们构建了一个JavaSDK,不同的项目可以通过将其添加为类路径中的jar或添加为mavenpom.xml或gradle文件中的依赖项来使用它。当其他项目使用该库时,SDK中的日志在运行时不可见。我尝试使用SL4J,当其他项目使用它时,没有一个日志在运行时可见。我应该用log4j2吗?如果是,我应该在我的SDK中提供log4j配置 /properties文件吗?是否会在运行时从消费者库中提取属
-
 阿里云日志SLS一面
阿里云日志SLS一面只记了部分题目,不是全部 1、Java为什么跨平台 2、为什么选择Java,Java相较于C++有何优势 3、在项目中,节点资源不足时,使用钉钉机器人报警,但在海量报警信息的情况下,钉钉机器人是有请求数限制的,怎么办? 我:利用缓存,缓存一部分报警信息 面试官:OOM 我:持久化到磁盘 其实这里应该要用到消息队列的,我只说了持久化到磁盘,没想到消息队列 4、RocketMQ相较于Kafka有哪些新
-
SLF4J参数化日志消息
主要内容:参数化日志的优势,两个参数变体,多个参数变体正如本教程前面所讨论的,SLF4J提供了对参数化日志消息的支持。可以在消息中使用参数,并在稍后的同一语句中将值传递给它们。 语法 如下所示,需要在消息(String)中的任何位置使用占位符(),稍后可以在对象形式中为占位符传递值,并使用逗号分隔消息和值。 示例 以下示例演示使用SLF4J进行参数化日志记录(使用单个参数)。 执行时,上述程序生成以下输出 - 参数化日志的优势 在Java中,如果需要
-
禁用apache日志访问access.log
问题内容: 我一直在阅读有关禁用apache服务器的日志记录的信息,这对我来说至关重要,因为我正在对其进行大量测试,并且该文件会填充磁盘。 我尝试过更改http.conf并将内容定向到/ dev / null,但是没有一个起作用,因为大多数是错误日志记录。 有人知道吗? 谢谢 问题答案: 为了禁用和关闭Apache日志记录,只需注释掉Apache配置文件中的日志行。在这里阅读更多。
-
GKE和Stackdriver:Java logback日志格式?
问题内容: 我有一个在Kubernetes上的docker映像中运行Java的项目。流利的代理会自动提取日志,并最终将其存储在Stackdriver中。 但是,日志的格式是错误的:多行日志在Stackdriver中放入单独的日志行,并且所有日志都具有“ INFO”日志级别,即使它们确实是警告或错误。 我一直在寻找有关如何配置登录以输出正确格式以使其正常工作的信息,但是在Google Stackdr
-
抓取日志处理程序
问题内容: 我在以下两个问题中寻求您的帮助-如何为不同的日志级别(如python)设置处理程序。目前,我有 但是Scrapy生成的调试消息也会添加到日志文件中。这些时间非常长,理想情况下,我希望将DEBUG级别的消息保留在标准错误上,并将INFO消息转储到我的。 其次,在文档中,它说我的问题是,我应该在哪里运行它?它在我的蜘蛛里面吗? 问题答案: 嗯, 只是想更新一下,我能够使用来获取日志文件处理