《影石Insta360》专题
-
多维数组声明中的顺序对已用内存有影响吗?
问题内容: 多少字节将被分配给和? 请注意,我只是在询问纯数组占用的内存,内部没有对象。 我为什么要问?因为我在写Android游戏。对我而言,顺序并不重要,但是如果存在内存差异,最好保存一些。 问题答案: 是的,确实有所作为。 在Java中,2D数组是1D数组的数组,并且数组(像所有对象一样)除具有保存元素本身所需的空间外,还具有标头。 因此,请考虑vs和,并假设使用32位JVM。 由2个元素的
-
基于python实现的抓取腾讯视频所有电影的爬虫
本文向大家介绍基于python实现的抓取腾讯视频所有电影的爬虫,包括了基于python实现的抓取腾讯视频所有电影的爬虫的使用技巧和注意事项,需要的朋友参考一下 我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装、下载、运行起来不会花你5分钟时间。
-
使用geom_sf()和除lat long以外的任何投影打印sf对象
我正在尝试在除lat long以外的任何投影中使用geom_sf()绘制多边形。 我正在使用geom_sf()导入数据集手册页面中的示例: 从latlong转换到epsg: 3857 最后,使用ggplot2进行绘图,定义绘图的CR: 我一直在wgs84(即epsg:4326)中获得一张带有lat长轴的地图。我希望轴以米为单位,因此我需要来绘制投影多边形。我做错了什么?
-
matplotlib绘图中卡托地轴如何正确设置投影和变换
在使用Python geopandas、cartopy和matplotlib以正确绘制shapefile数据时,我面临着严重的困难。 问题来自于在正确设置转换和投影对象的shapefile数据的困难。 我在这里描述的示例是相对于SIRGAS 2000投影中的SHP而言的,其WKT格式为: GEOGCS[“SIRGAS 2000”,基准[“D_SIRGAS_2000”,球体[“GRS_1980”,6
-
 完全透明的导航栏,但不应影响Android上的状态栏
完全透明的导航栏,但不应影响Android上的状态栏我需要一个屏幕,有一个完全透明的导航栏,但状态栏应该有彩色口音。 我尝试了不同的解决方案,但都不管用。 1-尝试使用XML更改颜色 当我尝试上面的代码时,导航栏如下图所示。这是不透明的 2-试图更改windowTranslucentNavigation 我试图设置android: windowTransLucentNaviation=true和android: windowTransLucentS
-
如何在spring data jpa中进行POJO投影以实现原生查询
我有以下MySQL查询。我尝试了spring data jpa中的接口投影,但是投影字段id是UUID。所以它不会被映射到界面投影中。所以我想尝试POJO投影,但它不起作用。
-
融合模式如何帮助确保读取(投影)Avro模式进化?
SchemaRegistry 有助于与需要写入架构来解码接收到的消息的使用者共享用于对消息进行编码的写入 Avro 架构。另一个重要功能是协助架构演变。 假设生产者P定义了存储在逻辑模式S下的写Avro模式v1,消费者C1定义了读(投影)模式v1,另一个消费者C2定义了它自己的读(投影)模式。读取模式不共享,因为Avro在本地使用它们将消息从编写器模式转换到读取器模式。 想象一下没有任何突破性变化
-
JPA投影:只选择@OneTomany关系的部分项目和整个实体
我有这两个实体: 所以一个组织可以有一个或多个OrganizationMeta,这是一个简单的情况。 有可能做到这一点吗?有人遇到过这个问题吗?
-
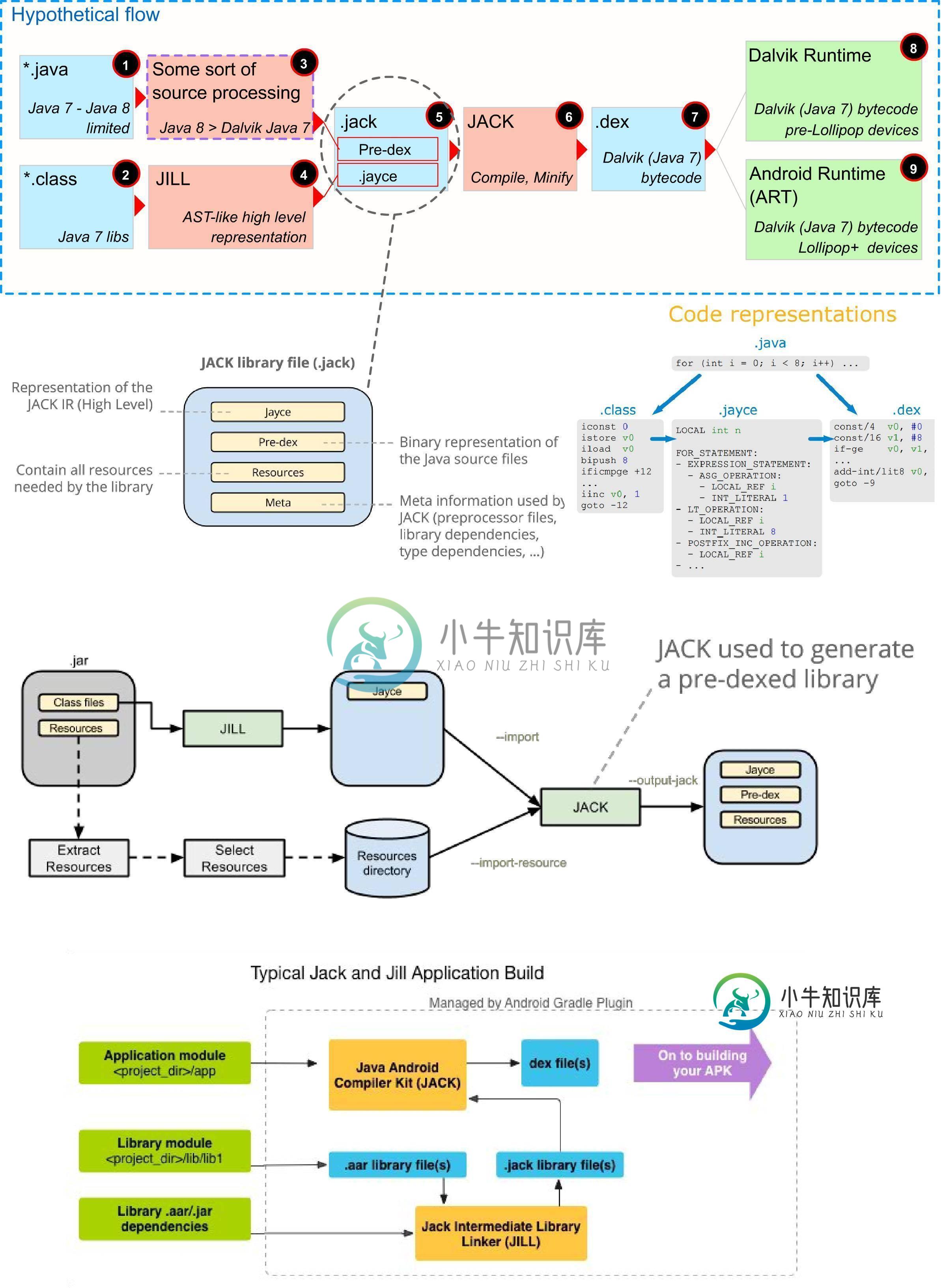 Jack(Java Android编译器工具包)将如何影响Scala开发人员
Jack(Java Android编译器工具包)将如何影响Scala开发人员现在,随着杰克的宣布,谷歌澄清了Java与Android之间可预见的未来。但是这对Scala和其他基于JVM的语言开发人员有什么影响。特别是: Scala之所以如此神奇,是因为它有自己的编译器来生成Java字节码。但是Jack toolchain不处理字节码。生成的字节码会获得Jack处理的任何优化好处吗? 从Scala12开始,只支持Java8+。也就是说,生成的字节码也是Java8+。Jack
-
如何在不影响Dockerfile的情况下加载多个环境变量?
我正在处理一个简单的Docker映像,其中包含大量环境变量。你能像docker-compose一样导入环境变量文件吗?我在docker文件留档中找不到任何相关信息。 Dockerfile 我想重新表述这个问题的一个好方法是:如何在Dockerfile中高效地加载多个环境变量?如果无法加载文件,则无法将docker文件提交到GitHub。
-
视图的行号,该视图的行号不受where子句的影响
SQL Server 2008 我有一个有许多行的视图,在那里也可以有精确的行多次。我已经尝试将ROW_NUMBER()作为row_id(按col1排序),但遇到问题: 编辑:我添加了一个例子,应该在发帖之前就做了。 没有WHERE子句: 选择ROW_NUMBER()OVER(按col1排序)作为row_id,RESULT.* FROM ( 选择“Adam”col1,“West”col2 全部联合
-
为什么扫描器对象会影响BufferedWriter写入文件的能力?
扫描器实例如何阻止BufferedWriter写入文本文件?我没在考虑什么?任何帮助/反馈将非常感谢!
-
gradle中的影子插件不起作用-gradle构建不构建胖jar
我有以下内容: 问题是运行并没有创建一个胖jar。 通过运行显示任务存在,但是任务不依赖于它:
-
使用--debug运行spring应用程序不会影响我的记录器
我创建了几个类似上面示例的记录器,问题是,当我使用运行Spring应用程序时,不会被记录,只有Spring默认/内部记录器才会实际使用参数。 如何使记录器也使用参数?
-
将Kafka Topic迁移到新集群(以及对德鲁伊特的影响)
我正在从Kafka的话题中摄取数据到德鲁伊。现在,我想将我的Kafka Topic迁移到新的KafkaCluster。在不重复数据和不停机的情况下,有哪些可能的方法可以做到这一点 我考虑了以下将Topic迁移到新Kafka集群的可能方法。 手动迁移: 在新的Kafka集群中创建具有相同配置的主题。 停止在Kafka集群中推送数据。 开始在新集群中推送数据。 停止从旧集群消耗。 从新集群开始消费。