《超参数科技》专题
-
 npm脚本使用yargs将参数/参数传递给节点脚本
npm脚本使用yargs将参数/参数传递给节点脚本当用作npm脚本参数时,是否可以调用从yargs检索密钥? OSX终端中的用户类型: 执行package.json: 这导致了 只有在package.json中硬编码时,这才有效,但我需要它是可配置的。 正如我所说的,我使用的是args,因为它似乎可以很容易地按名称检索键(与数组相反)。接受建议。 我错过了什么? 更新11-07-2017相关:发送命令行参数到npm脚本 但是,传入命令行OR会产生
-
类型List不是泛型的;它不能用参数[HTTPClient]参数化
所以我有那个代码,我是通过上传到Imgur v3使用Javahttps错误得到的,我在第50行得到一个错误,因为“列表”告诉我 类型列表不是泛型的;它不能用参数参数化 我能做些什么来解决这个问题? 我正在使用http://hc.apache.org/httpclient-3.x/并希望使用v3 API将图像上传到imgur。 编辑:更改导入后,我现在收到这些错误。 这就解决了这个问题,但又给了我两
-
RecycerView.Adapter。重写的方法onCreateViewHolder参数在viewType参数中始终为零
我想使RecycerView具有多种视图类型。如本主题:链接。 我知道这种方法的关键是方法getItemViewType(position:Int):Int{}。
-
@Part参数只能与多部分编码一起使用。(参数#8)
在我在这里发布这个问题之前,我已经尝试在接口方法上面添加并且在stackoverflow中搜索仍然没有找到与我的问题相似的。 在这种情况下,我尝试使用向服务器发送图像。我接口方法如下所示: 我正在使用改装1.9
-
类型{static:Boolean;}的参数不能赋值给类型{read?:any}的参数
在我新创建的Angular应用程序中,我尝试使用mattlewis92的Angular日历来创建他的日历。我已经复制了他的github:https://mattlewis92.github.io/Angulat-calendar/#/kitchenter-sink上列出的所有步骤和代码,但我在第一行总是发现一个错误,即指出“{static:boolean;}类型的参数不能分配给{read?:any
-
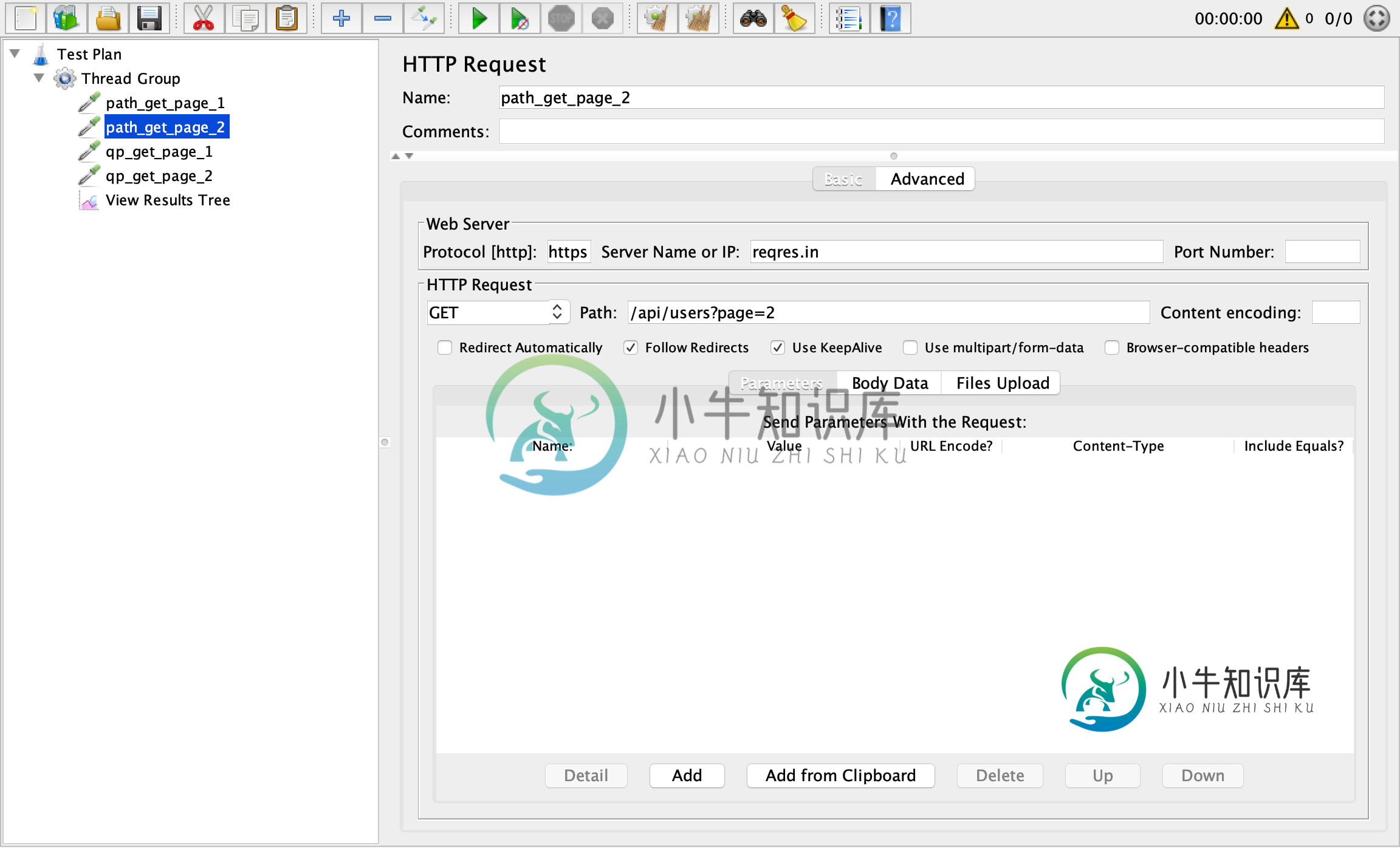 通过“参数”选项卡传递查询参数以获取请求
通过“参数”选项卡传递查询参数以获取请求当我将参数嵌入到下面的路径中时,我可以成功地传递参数 我应该使用‘参数’tabe只有当我做POST方法?我知道向JMeter传递参数是一个简单的问题,但我不能解决我的问题。
-
为什么修改的是ArrayList参数,而不是String参数?[副本]
在的情况下,将检索添加的元素。在的情况下,方法调用对所传递的字符串没有影响。JVM到底在做什么?有人能详细解释一下吗?
-
Swagger显示没有参数到具有参数的控制器操作
Swagger不在UI和JSON中显示参数,即使我的方法有参数,当我添加[FromBody]标记 Swagger UI无参数JSON文件无参数 操作方法时,尤其会发生这种情况: 我使用全新的 Asp.net 核心3.1和2.2 Web应用程序与API模板来测试这一点,我完全按照文档配置 服务进行了配置: 配置:< br > 当我使用[FromRoute]等其他属性时,它确实起作用 我还尝试了这样的
-
Powershell[validateSet()]在使用相同参数名的单独参数集之间
好的,所以我正在尝试编写一个高级函数,它使用两个不同的参数集名称,一个是另一个是。 这大部分工作都很好,但是,我的问题是: 的输出在部分给出了以下内容: 从外观上看,这正是我想要的--一个参数集,我可以在其中验证几个不同的列表,并在其中移动,我有密码、描述等;另一个参数集,我只验证的一个值,并有一个只属于参数集的参数。 不幸的是,在ISE中尝试测试时,如果输入: ,我从IntelliSense得到
-
5.1.26 26.数组中出现次数超过一半的数字
一、题目 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。 二、解题思路 解法一:基于Partition 函数的O(n)算法 数组中有一个数字出现的次数超过了数组长度的一半。如果把这个数组排序,那么排序之后位于数组中间的数字一定就是那个出现次数超过数组长度一半的数字。也就是说,这个数字就是统计学上的中位数,即长度为n 的数组中第n/2 大的数字。 这种算法是受快速排序算法的启发。在随
-
 字节大数据开发-人力科技面经(已凉)
字节大数据开发-人力科技面经(已凉)字节大数据开发工程师- 人力科技面经 一面 网络模型,每一层的功能 访问一个网页的流程 tcp是如何保证可靠 线程和进程的区别 JVM的内存区域 垃圾回收算法 类加载的过程 Spark和MR的区别 Spark任务调度过程 spark中stag,job,task是如何划分的 spark宽窄依赖 为什么spark比MR快 Hadoop的框架 Hadoop提交作业的流程 Hadoop中是如何找到文件对应
-
 2023秋招—数据开发面经—杰创智能科技
2023秋招—数据开发面经—杰创智能科技笔试:选择题+填空题+判断题+简答题 简答题 1、说说大数据技术的特点 2、说一下Spark任务执行的流程 3、1G的文件,每一行是一个词,词大小不超过16字节,内存1M,找出频数最高的100个词。 技术面 1、自我介绍 2、本专业主要学什么? 3、介绍一下实习的项目 4、小文件问题怎么处理?(SequenceFile、CombineInputFormat、JVM重用) 5、Hive支持哪些存储格
-
 深圳闻泰科技 大数据开发 技术面经
深圳闻泰科技 大数据开发 技术面经1、自我介绍 2、什么是维度建模?什么是关系建模? 3、星型模型和雪花模型有什么区别? 4、数据仓库分层的意义是什么? 5、对哪些大数据框架比较熟悉?(答了Hadoop和Kafka) 6、Hadoop的进程有哪些?作用分别是什么? 7、Kafka的特点是什么? 8、Kafka为什么可以支持海量数据吞吐? 9、问实习工作内容,以及实习收获 10、能否接受加班? 11、有什么问题要问我的?问了日常工作
-
 国企金融科技部门大数据实习面经
国企金融科技部门大数据实习面经目前已offer。 面试内容: 1.自我介绍:我就说了一下学校专业学的课然后之前的几段实习是做什么的。 2.SQL:这一块没有问具体的题目,问了一些窗口函数比如三个求rank的函数,sum() over 和groupby求和的区别,join后面跟where和on的区别,inner join 和left join使用场景这种,其他的记不清了。 3.Hadoop:问了Hadoop的组成,操作HDFS的
-
 杭州产链数字科技一面--JAVA日常实习
杭州产链数字科技一面--JAVA日常实习1.自我介绍 2.介绍短链接项目,读写锁与RabbitMQ实现延迟队列 3.介绍短链接监控功能怎么实现的 4.介绍分库分表,问怎么实现分库分表后分页查询 5.怎么实现单点登录 6.rabbitmq怎么实现的不重复消费,消息不丢失 7.redis数据结构有哪些 8.介绍redisson一下看门狗机制 9.redis过期数据删除策略 10.MySQL 介绍B+树,为什么不用其他数据结构 11.事务隔离