《索引》专题
-
从当前索引处的当前列表中检索元素[重复]
我有一份我正在处理的项目清单。我正在寻找初始列表中的特定项目,并希望在遍历列表时从该列表中删除已找到的项目。我遍历列表使用 有没有一种方法可以在不操纵两个列表的情况下做到这一点?
-
MySQL哈希索引的数据结构以及索引的优缺点
主要内容:1 索引的优缺点,2 哈希索引,3 全文索引,4 空间数据索引(R-Tree)我们看看其他哈希索引结构的实现,以及索引的优缺点。 1 索引的优缺点 索引可以让服务器快速的定位到表的指定位置。但是这并不是索引的唯一作用,总结下来索引有以下4个优点: 索引大大减少了服务器需要扫描的数据量。 B-Tree索引可以帮助服务器避免排序和临时表,可以用于 ORDER BY 和 GROUP BY 操作,临时表主要是在去重、排序、分组过程中创建,不需要排序和分组,也就不需要创建临时表。 由
-
如果ES中存在索引的索引,是否有基于API的方法在Kibana中创建索引模式
问题内容: 我在ES中有一个索引。我需要使用API调用在.kibana中创建相同的索引模式。在此创建中,我什至要设置将成为timestamp列的列。赞赏。 问题答案: 您可以做到,但是您需要自己构建整个结构。索引模式定义如下所示: 是索引模式的名称,如果通过UI创建索引模式,则输入的名称与您输入的名称相同 是时间戳字段的名称 是一个字符串,其中包含索引模式中所有字段定义的JSON数组(请参见下
-
来自URL搜索的Elasticsearch搜索正文
如果我在浏览器中直接对elasticsearch进行搜索,例如: http://localhost:9200/mydocs/_search?q=awesome%20搜索 搜索体数据实际上是什么样子的?它是否执行并包含所有字段?我尝试过编写一个包含所有字段的,但在浏览器中正确操作会得到不同的结果。
-
在二进制搜索树中搜索(Leetcode)
给定二叉查找树(BST)和整数val的根。 在BST中找到该节点的值等于val的节点,并返回以该节点为根的子树。如果这样的节点不存在,则返回null。 为什么'ans=root'不起作用??
-
Hibernate搜索Lucene重音不敏感搜索
我正在使用Hibernate Search/Lucene Intégration开发一个J2E应用程序。我索引文档(和其他实体),并希望对其进行不区分重音的搜索(内容和类的字段)。 这样做好吗?是否没有param或conf属性让FrenchAnalyzer忽略重音? 谢谢
-
二叉搜索树搜索返回空值
我用java编写了一个实用的二叉搜索树,除了一个关键的函数,搜索。我使用的逻辑是,我将检查根是否为空,然后我要搜索的术语是否等于根(所以返回根)或>根(所以搜索右子树)或 使用printlns查看正在发生的事情,我发现如果值在那里,它将通过正确的if语句(包括将BNode n设置为找到的值),但随后由于某种原因将再次通过方法(返回null)。 这个方法唯一起作用的时候是在搜索根节点的时候,这对我来
-
elasticsearch,多个索引与一个索引和不同数据集的类型?
问题内容: 我有一个使用MVC模式开发的应用程序,我现在希望为其建立多个模型的索引,这意味着每个模型具有不同的数据结构。 使用多个索引(每个模型一个索引还是在每个模型的相同索引中使用一个类型)是更好的选择吗?我认为这两种方式都需要不同的搜索查询。我刚刚开始。 如果数据集很小或很大,这两个概念在性能上是否存在差异? 如果有人可以为我推荐一些好的样本数据,我自己会测试第二个问题。 问题答案: 两种方法
-
Elasticsearch索引比它索引的日志的实际大小大得多吗?
问题内容: 我注意到,elasticsearch在晚上消耗了超过30GB的磁盘空间。相比之下,我要索引的所有日志的总大小仅为5 GB …嗯,甚至不是,实际上更像是2.5-3GB。是否有任何原因,有没有办法重新配置它?我正在运行ELK堆栈。 问题答案: 有许多原因导致Elasticsearch内部的数据比源数据大得多。一般而言,Logstash和Lucene都在努力为数据 添加 结构,而这些数据原本
-
Android列表视图数组索引超出范围异常-没有线索?
问题内容: 我有一个应用程序,该应用程序在打开时会加载一个列表视图,但是我遇到了数组索引超出界限异常的情况,却没有任何问题的根源。它正在尝试在某个地方访问index = -1,但我不知道在哪里。 该应用程序从数据库加载家庭作业信息,将它们放入ArrayList中的单独的家庭作业对象中,然后从那里将其加载到ListView中。我真的不知道异常的来源,我已经检查了所有代码。列表中只有1个作业,但是该应
-
SQL Server中的聚集索引和非聚集索引之间的区别
本文向大家介绍SQL Server中的聚集索引和非聚集索引之间的区别,包括了SQL Server中的聚集索引和非聚集索引之间的区别的使用技巧和注意事项,需要的朋友参考一下 索引是与实际表或视图相关联的查找表,数据库使用该查找表来改善数据检索性能的计时。在index中, 键存储在结构(B树)中,该结构使SQL Server可以快速有效地查找与键值关联的一行或多行。如果在表上定义了主键和唯一约束,则会
-
如何在elasticsearch中将一个索引文档复制到另一索引?
问题内容: 我用映射创建了一个新索引。其中存储了500 000个文档。 我想更改索引的映射,但是在elasticsearch中是不可能的。所以我用新的新映射创建了另一个索引,现在我正尝试将文档从旧索引复制到新索引。 我正在使用扫描和滚动类型从旧索引中检索文档并将其复制到新索引。复制需要花费更多时间,并且系统运行缓慢。 下面是我正在使用的代码。 问题答案: 您不必编写类似的代码。周围有一些出色的工具
-
如何使用字符串作为数组索引路径来检索值?
问题内容: 假设我有一个类似的数组: 我希望能够构建一个可以传递字符串的函数,该函数将用作数组索引路径并返回适当的数组值,而无需使用。那可能吗? 问题答案: 您可以使用数组作为路径(从左到右),然后使用递归函数:
-
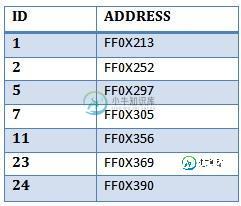 为什么非聚簇索引扫描比聚簇索引扫描更快?
为什么非聚簇索引扫描比聚簇索引扫描更快?问题内容: 据我所知,堆表是没有聚簇索引并且没有物理顺序的表。我有一个具有12万行的堆表“扫描”,并且正在使用以下选择: 如果为“ id”列创建非聚集索引,则将获得 223次物理读取 。如果删除非聚集索引并更改表以使“ id”成为主键(以及聚集索引),则将获得 515次物理读取 。 如果聚集索引表如下图所示: 为什么聚簇索引扫描的工作方式类似于表扫描?(或者在检索所有行的情况下更糟)。为什么不使用
-
基于SQL中的群集索引和非群集索引优化查询?
问题内容: 我最近一直念叨如何和作品。我的理解很简单(如果有错,请纠正我): 的数据结构,其背和IS :根据索引列(或键)对数据进行物理排序。每个只能有一个。如果在创建表的过程中未指定No ,则服务器将在上自动创建一个。 问题1 :由于数据是根据索引进行物理排序的,因此这里不需要额外的空间。这样对吗?那么,当我删除创建的索引时会发生什么? :在中,树的包含列值和指向数据库中实际行的指针(行定位符)