《全文检索》专题
-
检索给定年份中科学论文的引用次数
如何检索给定年份内论文的引用次数? 我看了Scopus引文概述应用编程接口,但是pybliometrics留档说应用编程接口密钥需要爱思唯尔为此目的批准,事实上它返回了错误403。 是否有其他数据源可以检索引用次数? rcrossref包提供了一个函数,该函数似乎可以获取当前引文的数量。 我需要给定年份的引用次数(例如,如果一篇论文在2010年发表,我可能需要2015年的引用次数,而不是2021年
-
从boto3检索S3存储桶中的子文件夹名称
问题内容: 使用boto3,我可以访问我的AWS S3存储桶: 现在,存储桶包含文件夹,例如,文件夹本身包含多个带有时间戳的子文件夹。我需要知道这些子文件夹的名称来完成我正在做的另一项工作,我想知道是否可以让boto3为我检索这些子文件夹。 所以我尝试了: 它提供了一个字典,其键“目录”为我提供了所有第三级文件,而不是第二级时间戳目录,实际上,我得到了一个包含以下内容的列表: {u’ETag’:’
-
使用Java从MongoDB检索数据时如何跳过文档?
本文向大家介绍使用Java从MongoDB检索数据时如何跳过文档?,包括了使用Java从MongoDB检索数据时如何跳过文档?的使用技巧和注意事项,需要的朋友参考一下 从MongoDB集合中检索记录时,可以使用skip()方法跳过结果中的记录。 句法 Java MongoDB库提供了一个具有相同名称的方法,以跳过记录,并绕过表示要跳过的记录数的整数值来调用此方法(基于find()方法的结果)。 示
-
Php proc_open-将进程句柄保存到文件并检索它
我使用以下代码打开proc_open进程,并将句柄和管道保存到文件中: 在第二个时刻,我需要从文件中检索这个文件句柄,我使用了这个代码: 当然,在这一点上,如果我试图关闭管道,我会得到一个错误,资源预期,整数给定。 我怎样才能让这工作?(注意:这是我正在寻找的解决方案) 但是或者,我也可以得到进程的pid,然后使用这个pid来停止或杀死进程,或者对进程做任何其他事情,但是管道呢?如何读取/写入或保
-
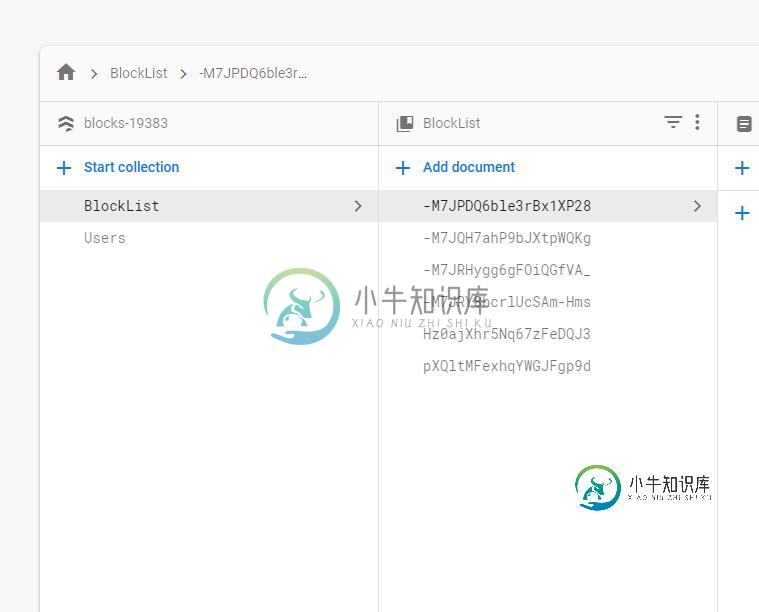 根据firestore在列表中的位置从firestore检索文档
根据firestore在列表中的位置从firestore检索文档我在firestore数据库中有两个集合,第一个是所有文档的列表(BlockList),第二个是用户的。当用户书签在应用程序的RecycerView上发布时,将文档的id和时间戳发送到Users Collection下的子Collection(收藏夹)。 我从主集合(BlockList)中检索基于此ID的文档列表,但我希望根据每个用户的时间戳来排列它们,所以我尝试在将它们添加到Arraylist并
-
 如何使用Jquery和Ajax从JSON文件中检索数据?
如何使用Jquery和Ajax从JSON文件中检索数据?今天发生了一件奇怪的事情:我正试图使用jquery和ajax从一个JSON文件中检索一些数据,并将这些数据显示在一个网页上。我在互联网上找到的这个例子对我在基础操作系统上起作用。当我尝试从带有Win10操作系统的虚拟机运行它时,它不起作用,这意味着它会将我抛到:。为什么?提前多谢! 这在我的data19.json文件中: 我的脚本script19.js是: 我的HTML文件是:
-
如何检索特定索引中的所有文档id(_ id)
我试图检索一个索引中的所有文档,但只得到_id字段。 基本上,我想检索我拥有的所有文档ID。 使用时: 我得到的命中包含:" _index "、" _type "、" _id "、" _score "、" _source ",这比我需要的要多得多。 编辑(回答):所以我的问题是我使用KOPF来运行查询,结果不准确(得到了_source等等…)!当使用curl时,我得到了正确的结果! 所以上面的查询
-
在cosmos db中,通过id检索文档的速度很慢
我有一个场景,我需要根据其id属性从azure cosmos db检索单个文档。唯一的问题是我不知道分区键,因此无法使用文档URI来访问它。 根据我的理解,编写一个简单的查询,如 这应该是一条路,但我遇到了这个查询的严重性能问题。大多数查询需要30到60秒才能完成,并且似乎消耗了大量的RU/s。当执行10个并发查询时,每个分区的最大RU/s高达30.000(每个分区配置10.00),导致节流和响应
-
如何在Python中检测文件是否为二进制文件(非文本)?
问题内容: 如何判断Python中文件是否是二进制文件(非文本)? 我正在Python中搜索大量文件,并始终在二进制文件中获取匹配项。这使输出看起来异常混乱。 我知道我可以使用,但是我对数据所做的事情超出了grep所允许的范围。 过去,我只会搜索大于的字符,但是类似的字符在现代系统上是不可能做到的。理想情况下,解决方案应该很快。 问题答案: 您还可以使用mimetypes模块: 编译二进制mime
-
以任何方式在InnoDB上实现类似全文的搜索
问题内容: 我有一个非常简单的查询: 进行搜索,但是正如您所看到的,它会分别搜索每个字符串,而且对性能也不好。 有没有一种方法可以在InnoDB表上使用LIKE重新创建类似全文的搜索。当然,我知道我可以使用Sphinx之类的东西来实现此目的,但是我正在寻找一个纯MySQL解决方案。 问题答案: 使用myisam全文表来索引回innodb表,例如: 使用innodb构建系统: 现在是全文搜索表,我们
-
Laravel使用scout集成elasticsearch做全文搜索的实现方法
本文向大家介绍Laravel使用scout集成elasticsearch做全文搜索的实现方法,包括了Laravel使用scout集成elasticsearch做全文搜索的实现方法的使用技巧和注意事项,需要的朋友参考一下 本文介绍了Laravel使用scout集成elasticsearch做全文搜索的实现方法,分享给大家,具体如下: 安装需要的组件 如果composer require larave
-
使用Lucene在多字段上进行OrientDB全文索引搜索
我在建立一个简单的地址数据库。有一个名为的类,其中的地址被分解为字段(street、city、state、ZIP)。每个字段都是字符串类型。 我想能够搜索地址中的任何一个字。例如:查找地址,无论搜索的词是在街道名称或城市名称等。换句话说,我希望用户能够轻松搜索,而不必指定他们感兴趣的地址的哪一部分。 但是当我执行以下查询时,我不会得到结果或错误消息: =>没有结果,应该是2条邮政编码为46250和
-
我想从包资源管理器中检索所选Java文件的路径/文件名
问题内容: 我正在开发一个插件,该插件需要检索Java文件的路径/文件名。 我编写的代码成功检索了xml或清单文件的文件名/路径,但是无法检索包中Java文件的路径。 我使用的代码是:- 问题答案: 感谢GUYZ,我有能力帮助您解决问题 解决方案是- 对象o =((IStructuredSelection)选择).getFirstElement(); den IPath loc =(((IComp
-
在C程序中使用strtok():为什么不能检索文本文件的下一行?
我正在编写C代码来读取包含多行单词的文本文件。对于文本文件中的每一行,我想标记字符串以删除空格。 例如,假设要读取的文本文件名为“testlist.txt”,内容为: 其中下划线表示空格,“\n”字符不可见。程序输出应为: 将输出以下代码: 第二次打印“Token:”后没有换行。此外,我希望getline()能够获得testlist的下一行。txt,以使进程重复,但程序已完成执行/终止,没有错误/
-
检索包含``
当我用R在web上抓取研究文章时,我遇到了HTML代码,其中a