《迪普科技》专题
-
在Phonegap项目中使用普通JQuery(使用JQuery Mobile)
我正在构建一个使用Cordova/PhoneGap和JQuery Mobile的应用程序。 我想在应用程序中使用JQuery,但我无法让它工作-即使使用简单的代码,也不会发生任何事情。 我相信我的标题设置正确: 当我看到JQuery移动风格的标题和后退按钮等时。 但是当我尝试一些简单的事情时,比如: 在MyScript中。我什么都没有得到。我是否需要以不同的方式触发JQuery?有人能给我指出正确
-
Haskell中的存在类型与普遍量化类型
这些到底有什么区别呢?我想我理解存在类型是如何工作的,它们就像OO中的基类没有向下强制转换的方法一样。通用类型有何不同?
-
唯一索引比普通索引快吗, 为什么?
本文向大家介绍唯一索引比普通索引快吗, 为什么?相关面试题,主要包含被问及唯一索引比普通索引快吗, 为什么?时的应答技巧和注意事项,需要的朋友参考一下 唯一索引不一定比普通索引快, 还可能慢. 查询时, 在未使用limit 1的情况下, 在匹配到一条数据后, 唯一索引即返回, 普通索引会继续匹配下一条数据, 发现不匹配后返回. 如此看来唯一索引少了一次匹配, 但实际上这个消耗微乎其微. 更新时,
-
用普通ascii字符替换重音字符[重复]
我需要将姓氏列表转换为字母数字用户名,但不幸的是,其中一些包含非ascii字符: 现在有一种方法是使用正则表达式删除任何非字母数字字符,例如。然而,更直观的解决方案(至少对用户来说)是将重音字符替换为它们的“纯”等价物,例如将、转换为,将转换为等。在javascript中有没有简单的方法来做到这一点?
-
如何保持普通二叉树(非BST)的平衡?
我知道使用旋转保持二叉搜索树平衡/自平衡的方法。 我不确定我的情况是否需要那么复杂。我不需要像自平衡BST那样维护任何排序顺序属性。我只是有一个普通的二叉树,我可能需要删除节点或插入节点。我需要尝试在树中保持平衡。为简单起见,我的二叉树类似于段树,每次删除一个节点时,从根到这个节点的路径上的所有节点都会受到影响(在我的情况下,这只是节点值的一些减法)。类似地,每次插入一个节点时,从根到插入节点的最
-
将普通sql查询转换为hibernate条件查询
我需要将这个sql查询转换为hibernate条件,请大家帮忙。 按名称顺序按应用描述限制3从设备组中选择名称,计数(*)为应用
-
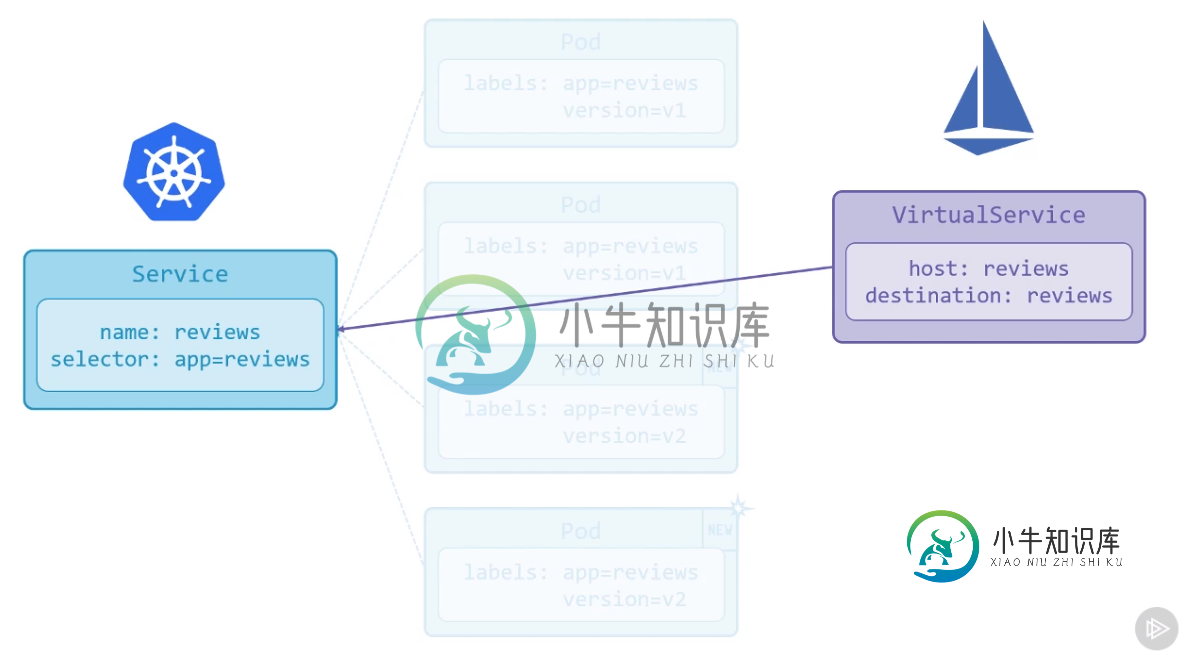 Istio虚拟服务与普通Kubernetes服务的关系
Istio虚拟服务与普通Kubernetes服务的关系我正在Istio服务网格上观看Pluralsight视频。演示文稿的一部分是这样说的: VirtualService使用库伯内特斯服务查找所有pod的IP地址。VirtualService不会通过[库伯内特斯]服务路由任何流量,但它只是使用它来获取流量可能去往的endpoint列表。 它显示了这个图形(显示pod发现,而不是流量路由): 我对此有点困惑,因为我不知道Istio如何知道要查看哪个库伯
-
普通生产者Kafka流的自定义分割器
我有一个kafka streams应用程序 或 这是一个类,用于将消息分发到不同的分区,即使在kafka 2.4版本中使用相同的键 RoundRobinPartitioner具有以下实现: 我的分区器由完全相同的代码组成,但分区方法实现不同,我的代码块是: 当我这样配置时,消息在两种实现中都被分发到不同的分区,但决不使用某些分区。 我有50个分区,而分区14和34从未收到消息。我的分区不是没有价值
-
使用普通谷歌账户作为服务账户
我有一个使用Google Drive的应用程序,它必须(a)不需要用户登录,(b)填充授权用户可以查看的文档。 正因为如此,如本文所述,使用常规帐户作为服务帐户似乎是我唯一的选择https://developers.google.com/drive/web/service-accounts 使用常规Google帐户作为应用程序拥有的帐户 你可以像任何用户一样,通过谷歌账户注册流程或在你的谷歌应用程
-
普罗米修斯endpoint上没有出现千分尺
我已经在一个千分尺计的方法中检测了我的代码,如下所示: 我还添加了一些其他指标。 其他指标显示在普罗米修斯endpoint上,但此指标指标不会。 我错过了什么?
-
千分尺相当于普罗米修斯的标签
我正在将Spring Boot应用程序从Spring Boot 1(使用Prometheus Simpleclient)转换为Spring Boot 2(使用微米)。 我很难将我们在《春靴1》和《普罗米修斯》中的标签转换为千分尺的概念。例如(普罗米修斯): Micrometer的标签似乎与Prometheus的标签有些不同:所有的值都必须预先声明,不仅仅是键。 可以将普罗米修斯的标签与Spring
-
普罗米修斯查询。回溯增量建议值
我在这里阅读并理解了普罗米修斯2.0版本中的陈旧概念 在我正在开发的导出器中,指标由远程设备作为 gRPC 流推送,因此我使用 prometheus 动态创建指标。使用时间戳并实现收集器接口。 每当远程设备停止发出度量时,这些度量就不再在Prom客户端HTTPendpoint中公开。但是,query.lookback-delta标志的默认值(5分钟)会使Prometheus在5分钟内将度量标记为陈
-
Spring引导2普罗米修斯不拉db指标
我在普罗米修斯使用spring boot2。我们使用Postgres作为数据库。普罗米修斯url没有获取数据库指标。 任何参考资料都会很有帮助。 我已经试过了 当我到达终点/普罗米修斯时,我得到了这个错误
-
春云侦探错误发布跨度到齐普金
还有人在使用Zipkin时遇到以下问题吗?
-
普罗米修斯合成级数的条件规则
我想从节点导出器获取时间序列向量节点\内存\可用内存\字节。它在RHEL7上运行良好,但在RHEL6上没有此数据,因为在旧内核的/proc/meminfo中没有此数据。 所以没问题,普罗米修斯给了我通过它的规则来计算这个时间序列矢量的可能性。 我想总结node_memory_MemFree_bytesnode_memory_Buffers_bytesnode_memory_Cached_bytes