《用户运营的核心技能是什么》专题
-
播放核心应用内审阅API,但未显示审阅activity
我正在尝试利用昨天刚刚发布的Google的Review API(Play Core Library1.8.0)。参见https://developer.android.com/guide/playcore/in-app-review 我仔细地遵循了疑难解答部分,我确保应用程序是从内部测试轨道下载的,我的帐户没有对应用程序的审查,应用程序在该用户的库中等等。我甚至尝试过使用一个全新的帐户,但每次显示
-
使用 AspNetUserTokens 表在核心 Web API 中存储刷新令牌 ASP.NET
我和ASP一起工作。NET核心Web API应用程序。我正在尝试在ASP之上实现基于Jwt令牌的身份验证。NET标识(内置数据库表)。 我已经实现了所有的场景,如注册用户,登录等,但现在试图实现刷新令牌流(当访问令牌过期时,客户端需要使用刷新令牌替换访问令牌)。我看到人们正在创建新的表(refreshToken)来存储刷新令牌,这样就可以用访问令牌来验证它,并将生成新的访问和刷新令牌 https:
-
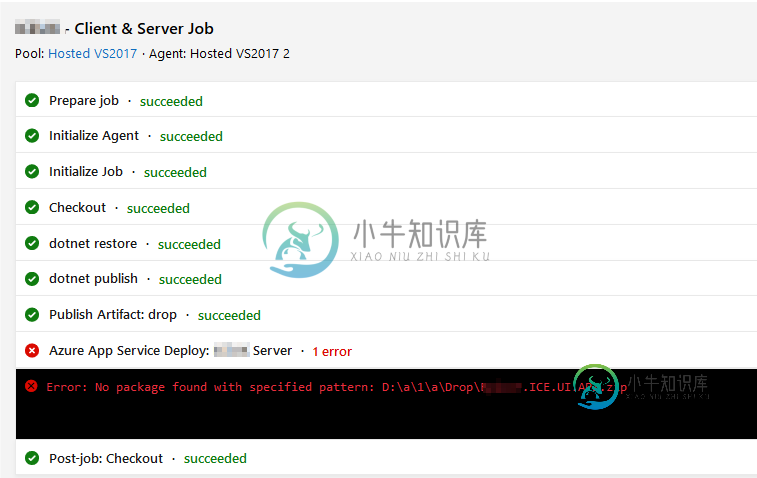 Azure DevOps生成管道-无法部署.NET核心应用程序
Azure DevOps生成管道-无法部署.NET核心应用程序我正在尝试为我的项目创建CI/CT管道。所有步骤都已成功完成,包括,但不幸的是,我在azure webapp部署期间出错 我在这一步中收到以下错误 错误:未找到具有指定模式的包:D:\a\1\a\Drop\xxx.xx.UI.API.zip 知道我做错了什么吗?
-
.NET核心应用程序与Azure应用程序服务身份验证
我的webapp是用。NET核心并部署在Azure中。我已启用Azure应用程序服务身份验证,并将其配置为使用Azure Active Directory。当我访问webapp时,我确实会被重定向到正确的登录页面。登录后,我可以浏览到endpoint。对我进行身份验证,并查看是否存在针对我的用户的声明。我还可以验证下面的请求标头是否存在值: X-MS-TOKEN-AAD-ID-TOKEN X-MS
-
Asp.Net 使用 TCPS 与 Oracle 数据库建立核心连接 不起作用
我正在尝试使用带有TCPS协议的内核与oracle数据库建立连接 asp.net。当我打开连接时,它给了我可执行文件 网络传输:解析钱包位置的SSL失败 TCPS:无效的SSL钱包(魔术版) 注意:当我尝试使用与TOD预言机相同的钱包位置连接databes时,它已成功连接。但不连接 with.net 核心。
-
如何在asp中为每种类型的请求启用Cors。净核心3.1
如何为核心3.1中的每种类型asp.net请求启用Cors? 我遵循的MS文档,但他们似乎不工作。 注意:我能够实现特定领域的cors,但不是每个领域。例如,我已将以下配置应用于我的项目: > 服务。AddCors(); 在我添加的方法中: app.UseCors(构建器= 但是当我试图从另一个url访问jQuery的API时,我会得到: 访问位于“”的XMLHttpRequesthttps://
-
Android:包含/重新打包引用Javax核心类的依赖项时出错
问题内容: 我正在使用Maven作为构建工具的Android应用程序上工作。我设法正确设置了Evertyhing(将Maven依赖项导出到apk等),但是我还有一个剩余的问题使我发疯。 我想在我的POM文件中包含对simpleframework的xml解析器的依赖,定义如下: 当我在项目上发布时,出现以下错误(被截断): 我知道来自引用这些javax类的简单xml解析器的错误结果,但是我还没有找到
-
 使用windows身份验证的Asp.net核心web API-Cors请求未经授权
使用windows身份验证的Asp.net核心web API-Cors请求未经授权在我的ASP.NET核心web api中,我已经按照MS文档中的文章配置了Cors。web api应用程序正在使用windows身份验证(未启用匿名身份验证)。创建Cor的策略,并在< code>startup.cs中添加中间件,如下所示 还应用了每个控制器级别的策略 选项请求越来越未经授权。请求 我见过类似的问题,也尝试过几乎所有的解决方案,但选项请求仍然失败。
-
12.2.利用JDBC核心类实现JDBC的基本操作和错误处理
12.2. 利用JDBC核心类实现JDBC的基本操作和错误处理 12.2.1. JdbcTemplate类 JdbcTemplate是core包的核心类。它替我们完成了资源的创建以及释放工作,从而简化了我们对JDBC的使用。它还可以帮助我们避免一些常见的错误,比如忘记关闭数据库连接。JdbcTemplate将完成JDBC核心处理流程,比如SQL语句的创建、执行,而把SQL语句的生成以及查询结果的提
-
为什么我不能在Python 3.10上运行matplotlib?
我的问题。我试图运行matplotlib在Python 3.10在我的MacOS,但我得到以下错误: 然而,当我试着跑步的时候 然后我回来 另外,针对 终端说 此外,如果我在Sublime Text 3上使用Python 2.7.16编译代码,我可以使用matplotlib。 我的问题。如何让matplotlib在Python 3.10上运行? 因为我对Python还是新手(或者编程,就此而言),
-
如何在Elasticsearch集群上最大化CPU核心
问题内容: 我必须设置多少个分片和副本才能使用群集中的每个cpu核心(我希望100%的负载,最快的查询结果)? 我想使用Elasticsearch进行聚合。我读到Elasticsearch使用多个cpu核心,但是没有找到关于cpu核心在分片和副本方面的确切细节。 我的观察是,单个分片在查询时使用的内核/线程不超过1个(考虑到一次仅查询一个)。使用副本时,查询1-shard索引的速度不会更快,因为E
-
Spark:以编程方式获取集群核心数
问题内容: 我在纱线簇中运行我的spark应用程序。在我的代码中,我使用队列的可用数量核心在数据集中创建分区: 我的问题:如何通过编程方式而不是通过配置获取可用的队列核心数? 问题答案: 有多种方法可以从Spark获取执行程序的数量和集群中的核心数量。这是我过去使用的一些Scala实用程序代码。您应该可以轻松地使其适应Java。有两个关键思想: 工人人数是执行者人数减去一或。 每个工人的核心数可以
-
如何阅读直到eof没有核心倾销?
我目前正在尝试从头开始做一个学习型Ai来熟悉它是如何工作的(项目代码链接在这里,我当前的问题是找到一种方法,一旦eof已经达到,就停止第20行的while循环。我尝试过使用fin.eof,当我使用它时得到的输出是“分段错误(核心转储)”。我如何让代码正常运行? 下面是我的代码:
-
火花独立编号执行器/核心控制
我不明白的是,当我提交作业并指定: 应该只占用4个核心。然而,当提交作业时,它将使用所有16个内核,并跳过参数而旋转8个执行器。但是,如果我将参数更改为,它将相应地调整,4个executors将向上旋转。
-
如何指定实体框架核心表映射?
问题内容: 我已经制作了一个简单的Entity Framework ASP Core Application,它可以工作,但是我不知道为什么: 我做了这样的上下文: 我有两个表,像这样的模型: 有趣的是,当我运行我的应用程序时,它实际上可以拾取数据。似乎很奇怪,因为我没有指定任何表映射。我假设这只是自动映射,因为指定的表具有相同的名称。 我的问题是: 如果我不希望模型名称与数据库完全相同,该如何指