《用户运营的核心技能是什么》专题
-
 百度用户运营一面
百度用户运营一面#运营人求职交流聚集地# 一面: (1)简历深挖,挑一个你印象最深的项目介绍 (2)对用户运营的了解 (3)当前实习的用户成长阶段分别是什么 (4)如何对于GMV指标进行拆解 (5)激励用户,答主的方法有哪些
-
 百度用户运营二面
百度用户运营二面#运营人求职交流聚集地# 百度用户运营二面 百度用户运营二面 (1)自我介绍 (2)三段实习经历介绍,挑两段介绍你参与的项目 (3)遇到的最大困难是什么 (4)如何解决 (5)未来的重点工作方向 (6)之前看过哪些知道的内容,一篇好的内容具备哪些重要的特征 (7)可以说一下你对于我们这个业务的了解吗?
-
 百度用户运营一面
百度用户运营一面#运营人求职交流聚集地# 一面: (1)简历深挖,挑一个你印象最深的项目介绍 (2)对用户运营的了解 (3)当前实习的用户成长阶段分别是什么 (4)如何对于GMV指标进行拆解 (5)激励用户,答主的方法有哪些 反问:对我的评价,对校招生的要求 感受:对校招HR来讲,匹配度胜于丰富度。 同时提一个略鸡汤的小tips,实习期间最好抱着“做的越多学的越多”的心态去工作,没有什么比工作成就感带给你更直接的
-
 百度用户运营二面
百度用户运营二面#运营人求职交流聚集地# (1)自我介绍 (2)三段实习经历介绍,挑两段介绍你参与的项目 (3)遇到的最大困难是什么 (4)如何解决 (5)未来的重点工作方向 (6)之前看过哪些知道的内容,一篇好的内容具备哪些重要的特征 (7)可以说一下你对于我们这个业务的了解吗? (8)性格优缺点 反问:对我的评价 校招生主要负责哪方面的工作,成长路径如何 一定要对自己有清晰的认知,明白自己擅长什么,兴趣点在哪
-
 美团用户运营一面
美团用户运营一面1,自我介绍,上来就让我先介绍实习经历 2.问我大学期间做过的创业项目是怎么设计问卷的 3.如何确认用户画像 4.在某段实习中最有成就感的一件事 5.怎么样使问卷的结果更具有准确性 6.为什么没有留在上一段实习的公司 7.怎么看待B端和C端,我如何选择 8.某段实习中的某数据是怎么得出来的,用了什么样的一些手段 总结:美团的一面超级详细,主要就是揪着简历一直面,当时面了我快一个小时吧,感觉答的也不
-
 用户运营-网易有道
用户运营-网易有道这是我第一份实习,也是我第一次面试,有很多地方已经记不太清了,还是很感谢网易面试我的姐姐,原因给我这个机会,虽然离职的时候闹了一些不愉快,不过我依旧很感谢他们,在网易,是我实习最欢乐的一段时间,开局就是王炸,以至于后面眼高手里了好一阵儿,我只是对运营感兴趣,从而想去互联网大厂更多的体验 1、自我介绍,很紧张,应该是重来了两次 2、面试管自我介绍,有道新开放的一条用户渠道在百度浏览页投放,需要一批0
-
 百度-用户运营实习
百度-用户运营实习👥 面试题目 1.自我介绍(2min) 2.询问过往实习经历的主要工作内容,以及个人成长与收获。 (个人认识有偏差,面试官很贴心给了一些分享:数据分析是需要深入业务,得出结论,从业务出发,是非常专业的方向) 3.对于当前应聘岗位的了解? (百度笔记是用小红书来进行生产的;给搜索用户一个极致的体验;真实的分享) 反问: 1.个人有哪些提升和了解的内容? 2.该岗位所做的用户运营和一般用户运营的差异
-
 小米用户运营一面
小米用户运营一面牛客的hr帮忙捞的,是小米游戏那边的 自我介绍 讲一下实习做什么,leader是做什么的 为什么不做开发了 你有什么优势 具体讲一下优势体现在哪里 了解小米游戏吗,了解小米吗? 初中是米孝子,给面试官讲了一下自己从小米4用到小米6的经历,然后吹了一波小米14 评价一下阴阳师这款游戏,从玩家和运营的角度 你是怎么看待运营这个岗位的,如何理解运营的工作 能否提前实习 有其他offer吗,怎么考虑的 反
-
 蚂蚁用户运营二面
蚂蚁用户运营二面二面 1. 自我介绍 2. 请你介绍实习中最大的learning,以及重来一次如何改善 3. 你认为影响目标实现的因素是什么? 4. 如果让你分析用户拉新的方法,你会怎么去考量 ? 5. 你实习过的公司里面,谈谈他们对用户的不同策略方法和你的感受 6.反问了面试官认为这个岗需要具备哪些能力,问了下对我刚才的评价 #运营面经#
-
 众安用户运营一面
众安用户运营一面自我介绍 你为什么选择用户运营这个岗位?对这个岗位的理解是什么? 你有什么方法可以提升引流效果? 有哪些措施可以增强引流的广度? 你是否购买过众安的保险产品? 你是否添加过我们的保险官?是通过什么方式建立联系的? 目前你有其他的offer吗? 你对自己的就业规划是怎样的? #非技术面试记录#
-
 携程用户运营面经
携程用户运营面经一面: 时间:大约30分钟 1.自我介绍。 2.深挖实习经历。 3.之前实习的难忘点,做过什么项目,遇到什么困难,怎么解决的。 4.两个优点两个缺点。 5.针对某个简历经历的提问。 6.反问(主要工作内容)。 二面: 时间:大约30分钟 1.对用户运营的看法。 2.精细化运营的经验。 3.自己在岗位中的作用,什么是我的工作核心。 4.针对上一段实习的某些经历提问。 5.父母支持你的异地求职吗。 6
-
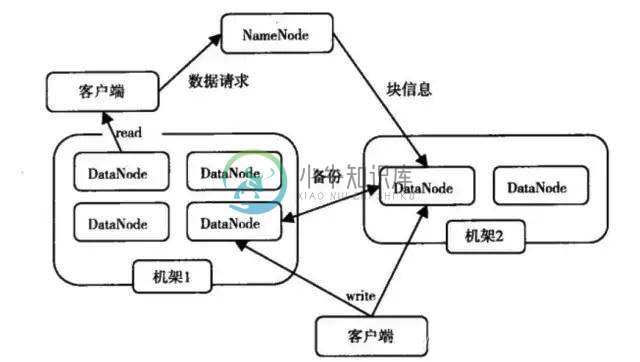 大数据技术十大核心原理
大数据技术十大核心原理主要内容:1.数据核心原理:从“流程”核心转变为“数据”核心,2.数据价值原理:有功能是价值转变为数据是价值,3.全样本原理:从抽样转变为需要全部数据样本,4.关注效率原理:由关注精确度转变为关注效率,5.关注相关性原理:由因果关系转变为关注相关性,6.预测原理:从不能预测转变为可以预测,7.信息找人原理:从人找信息,转变为信息找人,8.机器懂人原理:由人懂机器转变为机器更懂人,9.电子商务智能原理:大数据改变了电子商务模式,让电子商务更智能,科学进步越来越多地由数据来推动,海量数据给数据分析既
-
核心API
0.15 新版功能. 该节文档讲述Scrapy核心API,目标用户是开发Scrapy扩展(extensions)和中间件(middlewares)的开发人员。 Crawler API Scrapy API的主要入口是 Crawler 的实例对象, 通过类方法 from_crawler 将它传递给扩展(extensions)。 该对象提供对所有Scrapy核心组件的访问, 也是扩展访问Scrapy核
-
1.6 核心
理解核心 iScroll使用基于设备和浏览器性能的各种技术来进行滚动。通常不需要你来配置引擎,iScroll会为你选择最佳的方式。 尽管如此,理解iScroll工作机制和了解如何去配置他们也是很重要的。 options.useTransform 默认情况下引擎会使用CSStransform属性。如果现在还是2007年,那么可以设置这个属性为false,这就是说:引擎将使用top/left属性来进行
-
核心层
全连接层 全连接层实现了output = activation(dot(input, kernel) + bias) 全连接的的神经网络层。 对输出使用激活函数。单一层对神经网络输出施加一个激活函数。 对输入数据进行适当的丢弃 对输入进行Flatten,不影响batch 大小 对输出重新定义唯独。 根据一定的模型改变输入序列 重复输入n次 自定义层,嵌入自定义的表达式。 tensorflow中定义