《拼多多秋招》专题
-
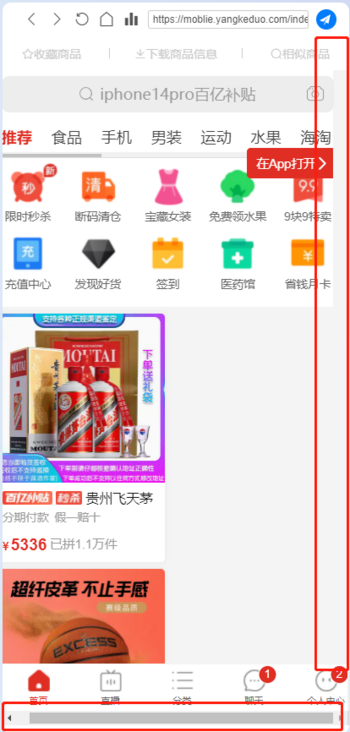 前端 - eletron的webview标签加载拼多多页面首页商品变一列改如何解决?
前端 - eletron的webview标签加载拼多多页面首页商品变一列改如何解决?看了一下发现是右边这个红框多出一个拉动格,导致宽度被撑开 因为拼多多页面是自适应的,所以修改webview的宽度也无济于事 想注入CSS或者js方式解决可是拼多多页面的样式名是 class="_2HlkOufU" 这种根本获取不到
-
Java 字符串拼接竟然有这么多姿势(收藏版)
本文向大家介绍Java 字符串拼接竟然有这么多姿势(收藏版),包括了Java 字符串拼接竟然有这么多姿势(收藏版)的使用技巧和注意事项,需要的朋友参考一下 但扪心自问,在我做程序员的前两年内,我也不知道为啥。遇到字符串拼接就上“+”号操作符,甭管是不是在循环体内。和小菜比起来,我当时可没他这么幸运,还有一位热心的“二哥”能够分享这份价值连城的开发手册。 既然我这么热心分享,不如好人做到底,对不对?
-
从Spark读取拼花地板数据时有多少个分区
我正在使用Spark 1.6.0。以及用于读取分区拼花数据的DataFrame API。 我想知道将使用多少个分区。 以下是我的一些数据: 2182个文件 Spark似乎使用了2182个分区,因为当我执行计数时,作业被拆分为2182个任务。 这似乎得到了的证实 对吗?在所有情况下? 如果是,数据量是否过高(即我是否应该使用df重新分区来减少数据量)?
-
ActiveAndroid多对多关系
问题内容: 我目前正在使用ActiveAndroid,并且在过去的几个小时里一直在尝试建立多对多关系,但是我还是无法正常工作。我希望你能帮助我: 我有“学生”和“课程”的模型,一个学生可以有很多课程,而一个课程有很多学生。基本上,这就是我在“ StudentCourse”模型中所拥有的: 现在,我要做的是使用以下代码获取“课程X中的所有学生”: 但是我收到以下错误: java.lang.Class
-
多对多查询jpql
问题内容: 我遇到了麻烦。 有一个实体发行人与与实体镇的ManyToMany关系有关: 那么实体镇也与地区有关 现在,我必须过滤(使用jpql)一个区域中的所有分发服务器。我能怎么做? 问题答案: 请参阅:https://en.wikibooks.org/wiki/Java_Persistence/JPQL
-
MySQL多对多选择
问题内容: 仍在学习MySQL的绳索,我试图找出如何进行涉及多对多的特定选择。如果表名太通用,我深表歉意,我只是在做一些自制的练习。我尽力成为一名自学者。 我有3个表,其中一个是链接表。如何编写 “显示哪些用户同时拥有HTC和Samsung手机” (他们拥有2部手机)的语句。我猜答案在WHERE语句中,但我不知道该怎么写。 问题答案: 关键是在GROUP BY / HAVING中使用COUNT个D
-
Spring,Hibernate-多对多-LazyInitializationException
问题内容: 我有2个模型。 用户: 汽车: 贴图: 用户: 汽车: HomePageController: 但是当我执行line时: 以下堆栈跟踪出现错误: 我是否构造了错误的映射文件,尤其是多对多关系? 问题答案: 默认情况下,Hibernate将延迟加载集合。换句话说,除非绝对需要,否则它不会进入数据库来检索汽车列表。这意味着从您的dao层返回的对象将不会初始化汽车列表,除非您尝试访问它。当您
-
mysql-多少列太多?
问题内容: 我正在建立一个可能有70列以上的表格。我现在正在考虑将其拆分,因为每次访问表时都不需要列中的某些数据。再说一次,如果我这样做,我就不得不使用联接。 在什么时候(如果有的话)是否认为列太多? 问题答案: 一旦超过数据库支持的最大限制,就认为它太多了。 不需要每个查询都返回所有列的事实是完全正常的;这就是为什么SELECT语句可让您显式命名所需的列的原因。 通常,您的表结构应反映您的域模型
-
JPA多对多映射
主要内容:@ManyToMany 示例,程序输出结果多对多映射表示集合值关联,其中任何数量的实体可以与其他实体的集合关联。 在关系数据库中,一个实体的任何行可以被引用到另一个实体的任意数量的行。 完整的项目目录结构如下所示 - @ManyToMany 示例 在这个例子中,我们将创建学生和图书馆之间的多对多关系,以便可以为任何数量的学生发放任何类型的书籍。 这个例子包含以下步骤 - 第1步: 在包中创建一个实体类,包含学生ID(s_id)和学生姓名(
-
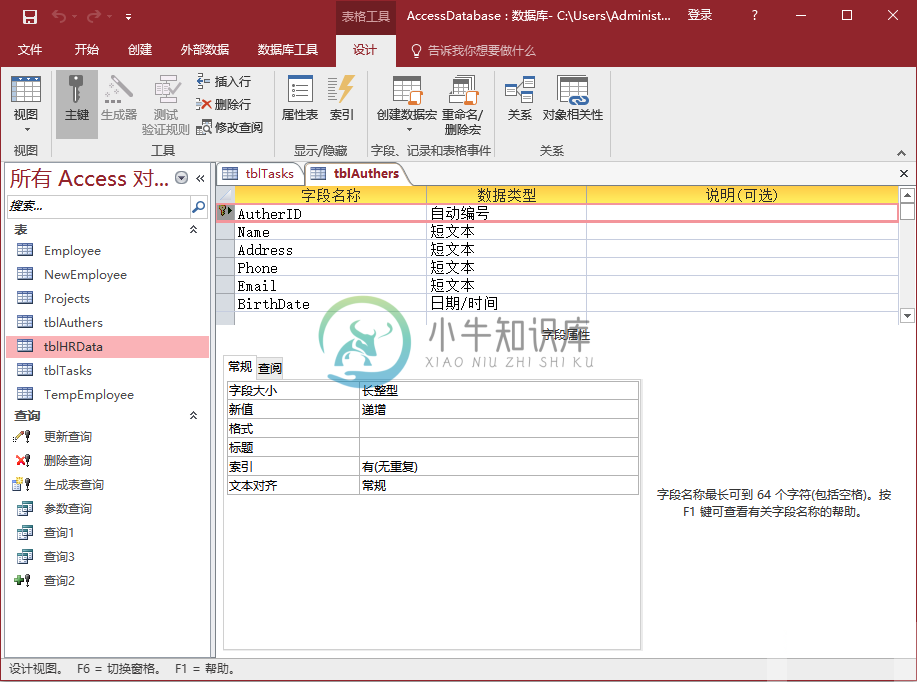 Access多对多关系
Access多对多关系在本章中,让我们了解和学习多对多的关系。要表示多对多关系,必须创建第三个表(通常称为联接表),将多对多关系分解为两个一对多关系。 为此,我们还需要添加一个联接表。 下面先添加一个表。表的定义如下所示 - 现在创建一个多对多的关系。假设有多个作者在多个项目上工作,反之亦然。 如您所知,我们在中有一个字段,所以为它创建了一个表。但现在不再需要这个字段了。 选择字段,然后按下删除 按钮,将看到以下消息。
-
MySQL多对多搜索
我已经开始开发我的第一个MySQL数据库,我遇到了一个简单的问题。 我将我的电影按“多对多”关系进行分类: 我试图做的是按类型搜索我的电影表,并显示每部电影的所有类型,例如: 这是一个我用来搜索恐怖电影的查询 我遇到的问题是,这个查询在筛选之前检索所有表的全部,我收集的结果非常低效。有没有更好的方法可以在显示所有相关类型的同时按一种类型搜索?
-
多对多的关系
我还想知道如何定义每个模型上的关系--你是否需要或者是否可以只在用户上定义关系?
-
3.5 多态一对多
在面向对象编程里面有一个特性就是多态,多态就是适应多种情况,有的时候我们有这样一个需求。评论需求,因为网站本来就不大,所以我期望所有的评论都放在一个表里面,可以评论图片,评论文章等等。 首先评论这个是一对多的关系。所以说应该在评论表里面存储一个被评论模型(比如文章、图片)的 Id,但是这个时候呢,文章的 ID 与图片的 ID 一定会有重合的情况。例如某用户评论了 Id 为 1的文章,某用户评论了
-
 多益网络2023秋招提前批前端开发笔试(已凉)
多益网络2023秋招提前批前端开发笔试(已凉)7月22日下午在多益校招官网注册的信息并填写简历 —————————————————————— 7月22日晚上完成的行测题 行测题共60道,45分钟,在多益官网上即可做答 —————————————————————— 7月23日晚上完成的主观题 主观题有11道,和其他描述的一样,分别是: 1.你认为这世界中各种事物,公平吗? 2.你是否希望中国人多生孩子? 3.这是一个周六,你原计划周日去健身房跑
-
Impala:如何查询具有不同模式的多个拼花文件
在Spark 2.1中,我经常使用类似的东西 加载拼花文件文件夹,即使使用不同的模式。然后,我使用SparkSQL对数据帧执行一些SQL查询。 现在我想试试黑斑羚,因为我读了这篇维基文章,其中包含如下句子: Apache Impala是一个开源的大规模并行处理(MPP)SQL查询引擎,用于存储在运行Apache Hadoop[…]的计算机集群中的数据。 读取Hadoop文件格式,包括text、LZ