《上汽大众》专题
-
试图用CASE语句更新多行时,Postgres挂起在大表上
我正在尝试使用postgres更新多行,我正在使用以下代码: 如果我创建一个新表,它可以完美地工作,但是当在具有800万行的大表上运行它时,它会无限期地挂起。我首先在管理员(Web界面)和控制台中尝试。 然而,这工作得很好: 我不太愿意在我的代码中实现这种方法,因为我一次会有数千个更新,并且更愿意将它们放在一个语句中。关于为什么第一个例子会挂postgres,而第二个例子会很好地工作,有什么想法吗
-
Google play console不再在大多数设备上测试应用程序
自2019年1月15日更新我的android studio以来,google play console不再在P8 Lite以外的任何设备上测试我的应用程序。所有其他设备状态为“此时无法测试此设备,请上载新的APK”。 我在任何地方都找不到关于为什么会发生这种情况的任何信息。是不是因为谷歌不再支持这些设备上的测试?或者这是对我的代码进行的更新? 我已经包括了我的gradle代码,以防它是由于SDK冲
-
 【小红书面经-Android】终于上岸了,希望帮助到大家
【小红书面经-Android】终于上岸了,希望帮助到大家希望下面的面试心得和知识点能帮助大家,帮大家早提Offer早上岸。面试心得和技巧也可以留言相互交流哦~。 先说说自己的面试经历 211院校,研究生,。从7月份开始就开始找工作。一开始投递的是后端的岗,面了知乎、携程、网易等,都挂了。连续挂好几次之后,感觉自己都快失业了。 后来和小红书的师兄聊,师兄告我我说今年后端和算法非常难找工作,淘汰率非常高,建议我转投客户端,客户端相对好找,而且待遇也超级的高
-
 上海人工智能实验室大模型算法实习面经
上海人工智能实验室大模型算法实习面经问的很细很深,狠狠拷打了80分钟,这个组做LLM pretrain的,我主要会rl,nlp缺乏点,一面凉 自我介绍 项目 微调模型训练数据来源? LORA的理解 Ptuning和全量微调对比 RLHF全流程 写出RLHF的优化目标公式 目标公式中衰减因子的作用,取大取小有什么影响? RLHF的目标公式可以加入什么其他的项? 熵正则项是如何加入的? KL散度理解? RLHF中PPO算比率相对什么来算
-
 【小红书面经-Android】终于上岸了,希望帮助到大家
【小红书面经-Android】终于上岸了,希望帮助到大家希望下面的面试心得和知识点能帮助大家,帮大家早提Offer早上岸。面试心得和技巧也可以留言相互交流哦~。 先说说自己的面试经历 211院校,研究生,。从7月份开始就开始找工作。一开始投递的是后端的岗,面了知乎、携程、网易等,都挂了。连续挂好几次之后,感觉自己都快失业了。 后来和小红书的师兄聊,师兄告我我说今年后端和算法非常难找工作,淘汰率非常高,建议我转投客户端,客户端相对好找,而且待遇也超级的高
-
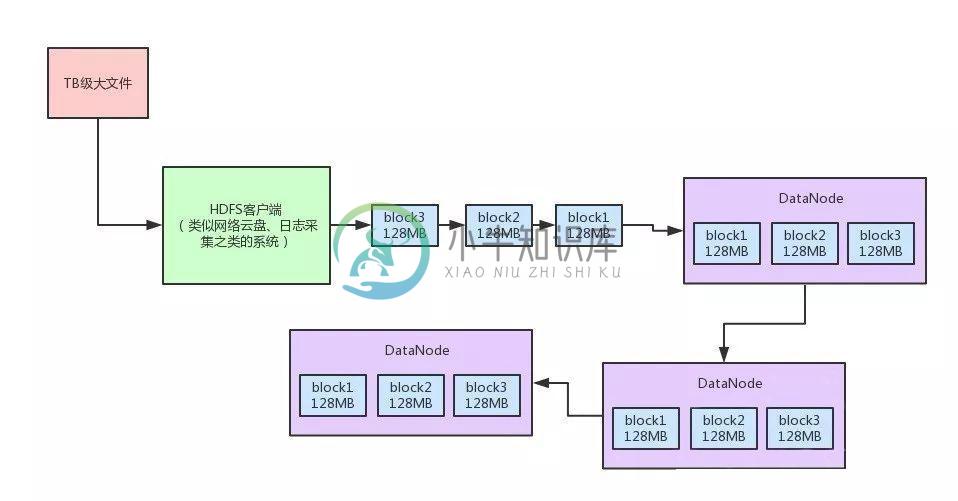 大厂面试题: TB级文件上传该怎么优化性能?
大厂面试题: TB级文件上传该怎么优化性能?主要内容:一、写在前面,二、原始的文件上传方案,三、HDFS对大文件上传的性能优化,1. Chunk缓冲机制,2. Packet数据包机制,3. 内存队列异步发送机制,四、总结一、写在前面 上一篇文章,我们聊了一下Hadoop中的NameNode里的edits log写机制。 主要分析了edits log写入磁盘和网络的时候,是如何通过分段加锁以及双缓冲的机制,大幅度提升了多线程并发写edits log的吞吐量,从而支持高并发的访问。 如果没看那篇文章的同学,可以回看一下:《放几十亿数据的系统还
-
在json数组集中,下一个索引的最小数量应大于上一个索引的最大数量
在这个 Json 数组中,我需要增加索引中的所有最小金额必须大于以前的索引最大金额,另一个条件是 maxamount 应该大于最小金额的相同索引 在上面的例子中,我已经根据更改最小金额更改了下一个索引值,我的例外输出是在更改单个最大金额的同时检查所有索引
-
 JVM进程大小和内存堆大小之间的巨大差异
JVM进程大小和内存堆大小之间的巨大差异我正在Windows 8.1 64位上开发java swing应用程序,带有4GB内存和JDK版本8u20 64位。 问题是当我使用带有监视器选项的Netbeans profiler启动应用程序时。 加载第一个Jframe时,应用程序Memory Heap约为18mb,JVM进程大小约为50mb(Image1)。 然后,当我启动另一个Jframe时,它包含一个带有webView的JFxPanel,
-
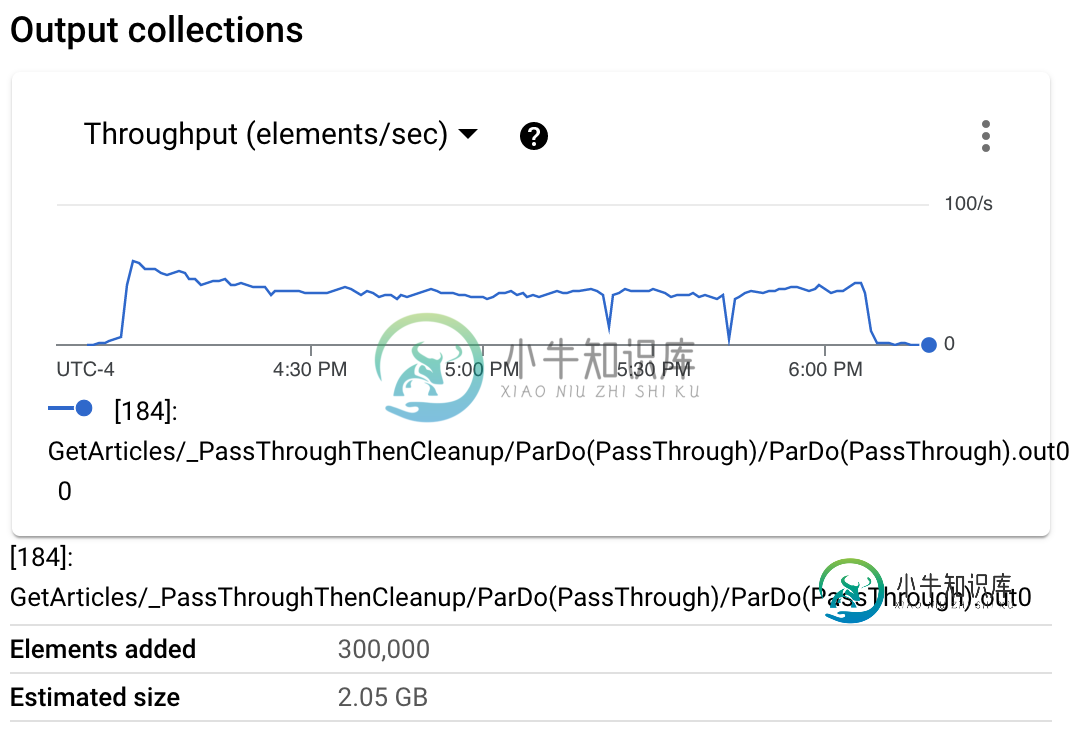 Dataflow Bigquery Bigquery管道在较小的数据上执行,但不在大型生产数据集上执行
Dataflow Bigquery Bigquery管道在较小的数据上执行,但不在大型生产数据集上执行这里的数据流有点新手,但是已经成功地创建了一个运行良好的pipleine。 pipleine从BigQuery读入查询,应用ParDo(NLP函数),然后将数据写入新的BigQuery表。 我试图处理的数据集大约为500GB,有4600万条记录。 当我试着用完整的数据集运行它时,它开始的速度非常快,但随后逐渐变慢,最终失败。此时,作业失败,添加了约900k个元素,约为6-7GB,然后元素计数实际上
-
如何识别我的Android设备何时通过蓝牙连接到汽车系统
我想知道当我检查我的设备是否通过蓝牙连接到汽车系统时,是否有任何特定的回调或类似的东西。 我知道有些公司在连接到这些系统时会更改用户界面。比如说,一个没有蓝牙连接或戴着耳机的蓝牙连接的用户界面与一个连接到汽车时完全不同的用户界面(例如,在开车时很容易点击的大按钮) 我看了Android的BluetoothAdapter。我特别感兴趣的是,ACTION\u CONNECTION\u STATE\u
-
根据div大小调整字体大小
问题内容: 它由9个框组成,中间带有文本。我已经制作了框,以便它们可以随着屏幕大小的变化而调整大小,以便始终保持在同一位置。 但是,即使我使用百分比,文本也不会调整大小。 如何调整文本的大小,使其在整个页面上始终具有相同的比例? 这是处理多种分辨率的合适解决方案吗?还是我应该在CSS中进行很多检查并为每种媒体类型设置许多布局? ``` html, body { } #launchmain { }
-
HttpRequest在tomcat中的最大允许大小?
问题内容: 我可以一次发送到的最大数据大小HttpURLConnection是Tomcat多少?请求大小是否有限制? 问题答案: maxPostSize 容器FORM URL参数解析将处理的POST的最大大小(以字节为单位)。可以通过将此属性设置为小于或等于0的值来禁用该限制。如果未指定,则将该属性设置为2097152(2兆字节)。 另一个限制是: maxHttpHeaderSize请求和响应HT
-
JavaScript localStorage值的最大大小是多少?
问题内容: 由于(当前)仅支持将字符串作为值,并且为了做到这一点,需要先将对象进行字符串化(存储为JSON- string),然后才可以定义值的长度。 有谁知道是否存在适用于所有浏览器的定义? 问题答案: 引用有关Web存储的Wikipedia文章: 可以简单地将网络存储视为Cookie的一种改进,它提供了更大的存储容量(Google Chrome中每个原始站点10 MB,Mozilla Fire
-
Elasticsearch文档的最大大小是多少?
问题内容: 我阅读了有关Lucene限制2Gb文档的说明。在Elasticsearch中可以建立索引的文档大小是否还有其他限制? 问题答案: Lucene内部使用一个字节缓冲区,该缓冲区使用32位整数进行寻址。根据定义,这限制了文档的大小。因此,理论上最大2GB。 在ElasticSearch中: ES GitHub代码中有一个,并将其设置为或。因此,基本上, 2GB是通过HTTP进行批量索引的最
-
Spring自动填充列表最大大小?
我对Spring AutoPopulatingList有问题。我的用例如下:管理可以访问应用程序的用户列表。 在GUI方面,我使用自动完成字段来搜索用户并将其添加到右侧的表中。用户也可以从表中删除。当GUI用户提交时,GUI会动态构建一个表单,其中包含用户字段:选择用户[1],…,选择用户[N]。 我的问题是,我的“支持”bean中的AutoPopulatingList似乎只增长到256项,然后停