《上汽大众》专题
-
 大早上更新了Visual Studio 2019 试用一下
大早上更新了Visual Studio 2019 试用一下本文向大家介绍大早上更新了Visual Studio 2019 试用一下,包括了大早上更新了Visual Studio 2019 试用一下的使用技巧和注意事项,需要的朋友参考一下 一、界面改变 1.项目创建界面 首先启动界面改变就不说了,创建项目的界面做了较大改变,感觉在向vs for mac 靠拢 ,而后者感觉像xcode。。 2.菜单 2019 2017 2019将解决方案名放到了菜单右边
-
 JSP通用高大上分页代码(超管用)
JSP通用高大上分页代码(超管用)本文向大家介绍JSP通用高大上分页代码(超管用),包括了JSP通用高大上分页代码(超管用)的使用技巧和注意事项,需要的朋友参考一下 先给大家展示下分页效果,如果亲们还很满意请参考以下代码。 在超链接中要保留参数 当使用多条件查询后,然后在点击第2 页时,这个第2页超链接没有条件了,所以会丢失条件,所以我们需要在页面上的所有链接都要保留条件! 我们要把条件以一个字符串的形式保存到PageBean的u
-
优化大表(75M +行)上的简单mysql选择
问题内容: 我有一个统计表,该表的增长速度非常快(每天约有2500万行),我希望针对选择进行优化,该表可容纳内存,并且服务器具有大量备用内存(32G,表为4G)。 我的简单汇总查询是: 统计信息是一个innodb表,在结束时间上有一个正常的索引。 注意:我确实计划添加汇总表,但是目前这是我所坚持的,并且我想知道是否有可能在没有其他应用程序代码的情况下对其进行修复。 问题答案: 我一直在做本地测试。
-
将大型视频文件上传到Google App Engine
我正在尝试通过谷歌应用引擎将一个大视频上传到谷歌云存储中。 我遵循了这篇文章中的原则,这篇文章提到了上传一个大的电子表格。在GCP应用引擎中无法将大文件上传到Python+Flask 这是我的后端代码 这是我的前端代码。
-
SpringBoot:使用Apache Commons FileUpload上传大型流文件
我试图使用“流式”Apache Commons文件上传API上传一个大文件。 我使用Apache Commons文件上传器而不是默认的Spring多部分上传器的原因是,当我们上传非常大的文件大小(~2GB)时,它会失败。我在一个GIS应用程序中工作,这样的文件上传非常常见。 我可能做错了什么?
-
如何在IntelliJ IDEA上增加内存堆大小?
我想分配大约1GB的堆大小,但我似乎无法弄清楚。 如何做到这一点?
-
放大,用户无权在资源上执行iam:passRole
所以我试图初始化一个现有的“反应”放大项目,其中配置了大约8个服务。当我运行放大推送时,除了以下内容,一切似乎都很好,也很成功,我得到了这个错误: 以下是给定地址的cloudwatch日志: 我试图创建角色“snsb927798344500 staging”并添加所需的策略,但当我尝试重新运行命令时,我收到一个错误,称。所以我认为是amplify在每一次推送中创建了角色,并且在过程失败后删除了它。
-
MySQL从机上的大量复制写入负载
我们在Debian8上使用Percona MySQL5.6作为电子商务聚合器。为此,有一个主后端服务器执行整个ETL(处理来自合作伙伴的产品提要),还有一个由前端web服务器使用的从MySQL服务器。它是一个包含约600GB数据的单一产品数据库。 这两台机器都带有RAID10和datacenter系列固态硬盘。主MySQL是128GB内存的双至强E5,从MySQL是64GB内存的单至强E5。我们的
-
如何编辑nginx。增加上传文件大小
我想增加可以上传的。 在网上做了一些研究后,我发现你必须编辑文件'nginx.conf'。 我目前可以访问该文件的唯一方法是通过遍历Putty并输入命令: 这将打开文件,但我现在有两个问题: 如何编辑此文件 我在网上发现,您必须添加以下代码行:
-
413邮递上的有效载荷太大[重复]
我制作了一个notes应用程序,我可以提交notes,并通过post请求将数据发送到我的mysql数据库。只要我的帖子不超过64kb,一切都很好。 我希望我的帖子能够超过64kb。每次我把一篇文章写得太大,我就会得到一个“413有效载荷太大”的错误。我正在使用axios、express、nginx等。我的notes应用程序代码可以在https://github.com/ericx2x/notes
-
通过 lambda 的 Amazon S3 分段上传段大小
我有几个lambda函数,可以将多部分上传到Amazon S3存储桶。它们负责创建多部分上传,然后为每个部分上传创建另一个,最后一个用于完成上传。 前两个似乎工作正常(它们以statusCode 200响应),但最后一个失败了。在Cloudwatch上,我可以看到一个错误,说“您建议的上传小于允许的最小大小”。 事实并非如此,因为我上传的文件大于文档上指定的最小大小5Mb。但是,我认为问题发生在每
-
多个图像的大小和上传与描述
我正在寻找一种方法来上传多个图像的描述。用户将从摄像头上传1-10张相当大的图片,所以最好在上传前调整图片大小。 要求: 浏览器兼容(包括手机浏览器和IE),可以依靠JavaScript(jQuery) 多个文件作为本机文件管理器中多个文件的选择,或者至少必须单击某个按钮来输入另一个文件 给每个文件添加一个描述 上传前调整文件大小(不需要与浏览器兼容) 上传提交 保留EXIF信息或至少提取GPS坐
-
Node.js中大文件上传至Azure blob的处理
我的目标是将一个大文件(任何文件类型)上传到Azure Blob中。 下面是我得到的错误 方法1工作很好,但上传时间太长。(统计数据:上传40 MB文件花了80秒)。 我的第二个方法是正确的一个提高性能?如果是,如何实现此方法? 有没有更好的方法来提高性能?在这方面有什么建议吗? 下面是套接字错误 我在这里错过了什么?为什么在创建块时发生套接字错误?
-
定制大小注释上的Java验证消息
在HTML方面,我有一个表单,它有两个textbox,这两个textbox包含名称和值。当用户输入一个大于10个字符大小的值时,我想显示一个类似“值大于10个字符”的定制消息。 我试过这个 但似乎不起作用。我仍然会收到丑陋的Java消息
-
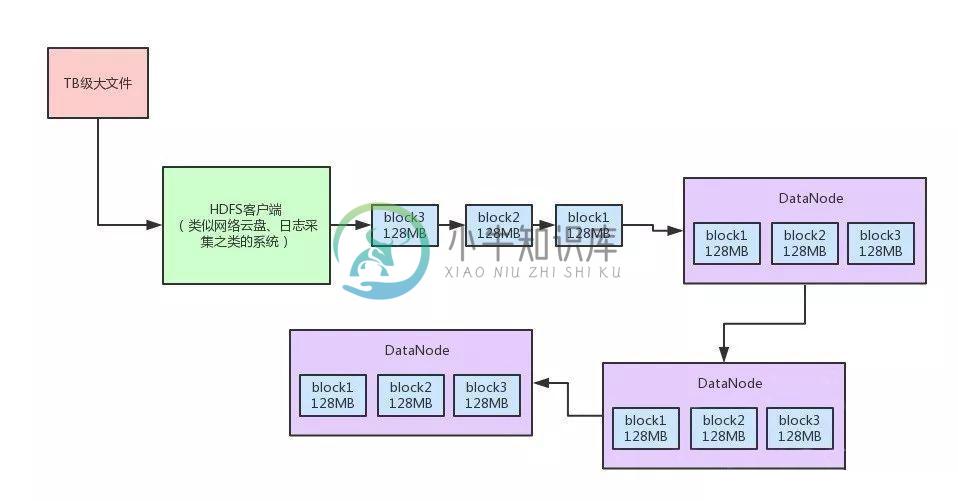 Hadoop的TB级大文件上传优化实践!
Hadoop的TB级大文件上传优化实践!主要内容:一、写在前面,二、原始的文件上传方案,三、HDFS对大文件上传的性能优化,1. Chunk缓冲机制,2. Packet数据包机制,3. 内存队列异步发送机制,四、总结一、写在前面 上一篇文章,我们聊了一下Hadoop中的NameNode里的edits log写机制。 主要分析了edits log写入磁盘和网络的时候,是如何通过分段加锁以及双缓冲的机制,大幅度提升了多线程并发写edits log的吞吐量,从而支持高并发的访问。 如果没看那篇文章的同学,可以回看一下:《每秒上千次高并发访问