《jsoup》专题
-
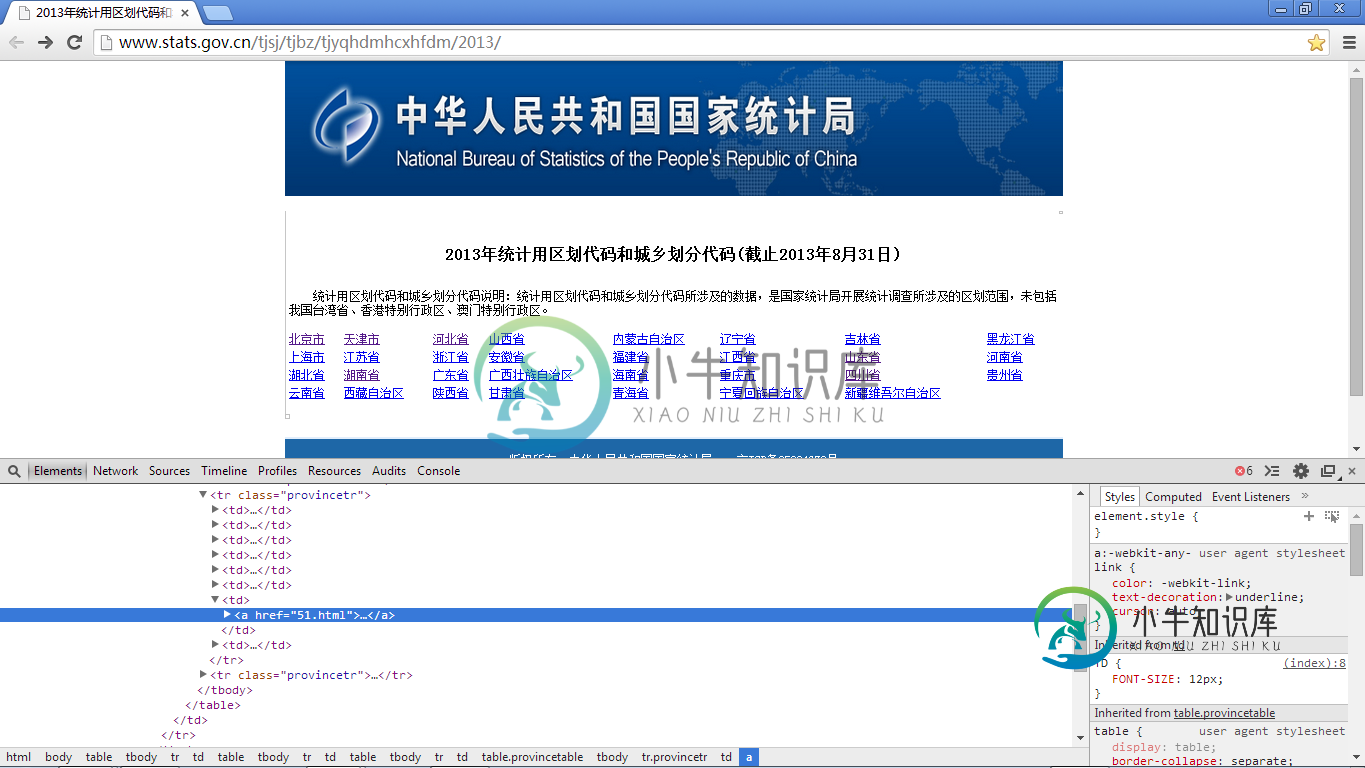 Jsoup获取全国地区数据属性值(省市县镇村)
Jsoup获取全国地区数据属性值(省市县镇村)本文向大家介绍Jsoup获取全国地区数据属性值(省市县镇村),包括了Jsoup获取全国地区数据属性值(省市县镇村)的使用技巧和注意事项,需要的朋友参考一下 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 最近手头在做一些东西,需要一个全国各地的地域数据,从
-
Java中使用开源库JSoup解析HTML文件实例
本文向大家介绍Java中使用开源库JSoup解析HTML文件实例,包括了Java中使用开源库JSoup解析HTML文件实例的使用技巧和注意事项,需要的朋友参考一下 HTML是WEB的核心,互联网中你看到的所有页面都是HTML,不管它们是由JavaScript,JSP,PHP,ASP或者是别的什么WEB技术动态生成的。你的浏览器会去解析HTML并替你去渲染它们。不过如果你需要自己在Java程序中解析
-
Jsoup 使用CSS选择器选择元素
本文向大家介绍Jsoup 使用CSS选择器选择元素,包括了Jsoup 使用CSS选择器选择元素的使用技巧和注意事项,需要的朋友参考一下 示例 您可以在此处找到支持的选择器的详细概述。
-
Jsoup 提取URL和链接标题
本文向大家介绍Jsoup 提取URL和链接标题,包括了Jsoup 提取URL和链接标题的使用技巧和注意事项,需要的朋友参考一下 示例 Jsoup可用于轻松地从网页中提取所有链接。在这种情况下,我们可以使用Jsoup提取我们想要的特定链接,这里h3是页面标题中的链接。我们还可以获取链接的文本。 这给出以下输出: 这里发生了什么事: 首先,我们从指定的URL获取HTML文档。此代码还将请求的用户代理标
-
线程“main”java.lang.noClassDefFoundError:org/jsoup/jsoup中出现异常
包com.copiedcrawler;
-
如何使用jsoup维护可变cookie和会话?
问题内容: 此方法不正确。我试图找出的是一种不知道将存在哪些cookie,能够处理cookie更改以及维护会话的方法。 我正在为我的简单机器论坛编写一个应用程序,当您单击某些自定义行为时,它会更改其cookie配置。 但是,如果该应用程序对我的网站运行良好,我将发布一个供其他论坛使用的版本。 我知道我朝着正确的方向前进,但是逻辑有点像在踢我的屁股。 任何建议将不胜感激。 问题答案: 这段代码很混乱
-
JSoup使用未关闭的标签解析无效的HTML
问题内容: 使用最新的JSoup 1.7.2版存在一个错误,该错误分析带有 未关闭标签的* 无效 HTML 。 * 例: 生成的文档为: 浏览器将生成如下内容: Jsoup应该用作浏览器或源代码。 有什么解决办法吗?调查API我什么也没找到。 问题答案: 正确的行为是在解析此无效的HTML时充当其他浏览器。感谢您提交此错误。我已解决了阻止采用机构将原始属性保留在新节点中的问题。它将在1.7.3中可
-
当我使用jsoup或htmlunit获取页面时,href字段丢失
问题内容: 我正在尝试解析Google图片搜索结果。 我正在尝试获取元素的 href属性 。我注意到以编程方式获取页面时, href字段 丢失了(jsoup和htmlunit都会发生这种情况)。 比较通过java以编程方式获得的页面元素和实际浏览器加载的页面元素,唯一的区别是,确实缺少了 href字段 (其余部分相同)。 href属性(IMAGE_LINK)如下: javascript引擎可能有问
-
处理连接错误和JSoup
问题内容: 我正在尝试创建一个应用程序,以从站点的多个页面上抓取内容。我正在使用JSoup进行连接。这是我的代码: 在大多数情况下,一切正常。但是,我想做一些事情。 首先,有时会返回404状态,或者会返回500状态,可能会返回301状态。在下面的代码中,它将仅打印错误并移至下一个URL。我想做的是尝试能够返回所有链接的url状态。如果页面连接,则打印200,否则打印相关的状态码。 其次,有时我会遇
-
如何使用jsoup从此html页面获取文本?
问题内容: 我正在使用此代码检索本页主要文章中的文本。 问题是textview中没有显示任何内容。我要检索的文字都没有出现。Log.i与调试日志中的段一起显示。因此,我知道其连接成功。只是不知道为什么即时通讯没有在textview中获取任何文本。 问题答案: 以下是您问题的相关摘要: 您在这里犯了一个根本性的错误。文档中没有HTML标签。但是,有一个。根据有关Jsoup食谱一半的CSS选择器概述,
-
TagSoup,Jsoup,HTML解析器,HotSax和
问题内容: 可供选择(并坚持使用)的大量HTML解析器令人难以置信: http://java-source.net/open-source/html-parsers 如何选择最适合以下要求的产品: 成熟(错误比其他错误少) 生活和呼吸(即得到维持) 快速且资源高效(打算在Android上运行) 根据您的经验,您会推荐哪种HTML解析器(以满足上述要求),为什么? 问题答案: 好吧,我找到了答案,它
-
通过Jsoup登录Facebook
问题内容: 我尝试使用我从已经发布的问题的答案中读取的这些行登录我的Facebook帐户,但无论如何我都无法登录!我正在寻找一些更正代码的提示: PS:不,我不想使用Facebook API! 问题答案: 在请求中传递了许多其他参数: 并且不要忘记参数。Facebook可能会为登录请求提供某种一次性令牌,以防止绕过Facebook API。
-
如何使用jsoup从此html标记获取文本?
问题内容: 当我使用jsoup提取数据时遇到一个职位。数据如下: 我想要这样的数据: 我怎样才能做到这一点?谁能帮我? 问题答案: 您可以将html解析为,选择-Element并获取其文本。 例: 输出:
-
解析器JSoup将标签更改为小写字母
问题内容: 我做了一些研究,似乎标准的Jsoup做出了更改。我想知道是否有一种配置方式,或者是否可以将其他解析器转换为Jsoup文档,或者通过某种方式解决此问题? 问题答案: 不幸的是,类的构造函数没有将名称更改为小写: 但是有两种方法可以改变这种行为: 如果您想要一个 干净的 解决方案,则可以克隆/下载JSoup Git并更改此行。 如果您想使用 肮脏的 解决方案,则可以使用反射。 #2的示例:
-
使用JSoup在保留换行符的同时删除HTML实体
问题内容: 我一直在使用JSoup解析歌词,到目前为止一直很棒,但是遇到了问题。 我可以用来返回所需节点的完整HTML,这样就保留了换行符: 但是,如您所见,保留HTML实体和标签具有不幸的副作用。 但是,如果使用,我可以获得更好的外观,并且没有标签和实体: 这有另一个不幸的副作用,即删除了换行符并压缩为单行。 在调用之前简单地从节点进行替换会产生相同的结果,而且该方法似乎将文本压缩到方法本身的一