《运营人找工作求助阵地》专题
-
Jenkis下游作业无法找到上游工件
问题内容: 该设置用于构建和部署到Adobe AEM。 主构建作业从git存储库中提取,构建和打包,运行测试,然后触发应使用上游作业中已构建软件包的下游作业。 问题是下游作业失败并显示以下消息: 在我看来,由下游作业触发的某种方式的CopyArtifacts插件正在寻找错误位置的工件。正确的位置是 但是然后,它抱怨 下游作业从另一个项目复制工件,然后该生成是“触发此作业的上游生成”或“从最新完成的
-
Pandas:在Excel文件中查找工作表列表
问题内容: 新版本的Pandas使用以下界面加载Excel文件: 但是,如果我不知道可用的图纸怎么办? 例如,我正在使用以下工作表的excel文件 数据1,数据2 …,数据N,foo,bar 但我不知道先验。 有什么方法可以从Pandas的Excel文档中获取工作表列表吗? 问题答案: 您仍然可以使用ExcelFile类(和属性): 有关更多选项, 请参阅文档以进行解析…
-
Mongodb查找不像我预期的那样工作
我想使用查找从一个集合中获取一些数据并将其放入另一个集合中。 在localfield或foreignfield中写什么都不重要,因为它从player_game_stats中获取所有数据并将其插入player集合中的每个文档中。我想检查localfield和foreignField是否相等,但lookup不检查这一点。我对mongodb使用NoSqlBooster
-
访问Excel工作簿返回“找不到资源”。
我希望连接到Microsoft Graph API,并与OneDrive上的一个小型Excel工作簿进行交互。 我能够通过Graph API成功授权并连接到OneDrive,查询我个人的OneDrive内容,甚至可以找到.xlsx工作簿并获取其ID。对此终结点的请求成功: 这是Microsoft Graph/O365业务帐户
-
按css查找选择器不能正确工作
我有场景 P/S我已经发现了熟悉的问题(https://github.com/minkphp/minkselenium2driver/issues/200),但降低浏览器版本不会产生影响。 提前感谢!
-
请说说,你在工作中喜欢和哪种人共事?
本文向大家介绍请说说,你在工作中喜欢和哪种人共事?相关面试题,主要包含被问及请说说,你在工作中喜欢和哪种人共事?时的应答技巧和注意事项,需要的朋友参考一下
-
Woocommerce添加更多不工作的电子邮件收件人
在woocommerce thank you页面上,如果订单状态正在处理,则向多个电子邮件地址发送WC_Email_Customer_Invoice电子邮件。 但问题是电子邮件只发送到客户的电子邮件地址,没有电子邮件发送到prohostreview@gmail.com。我正在使用最新的WordPress和woo-commerce插件。 请告诉我我在这里做错了什么。 问候。
-
Kafka Connect将同一任务分配给多个工作人员
我在分布式模式下使用 Kafka Connect。我现在多次观察到的一个奇怪行为是,一段时间后(可能是几个小时,可能是几天),似乎发生了平衡错误:相同的任务被分配给多个工人。因此,它们同时运行,并且根据连接器的性质,失败或产生“不可预测”的输出。 我能够用来重现该行为的最简单配置是:两个 Kafka Connect 工作线程,两个连接器,每个连接器只有一个任务。Kafka Connect 已部署到
-
spark独立集群:如何限制工作人员的数量?
> 提交应用程序未设置,然后它将创建 1名16芯工人 使用提交,然后它将创建一个包含15个核心的worker
-
Angular 5服务人员不工作/不缓存背景图像
我很难让我的angular5服务人员工作。我有两个主要问题: 服务工作者不缓存用作背景图像的资产图像 在模拟网络断开连接后,服务工作人员最初从缓存中提取文件(除了前面提到的非缓存文件),但在第二次刷新后,它会遇到错误。 下面是我的问题的更详细的报告。您可以通过克隆我所做的回购来强调这个问题。 我创建了带有--service-Worker标记的应用程序。然后我确保了Angular留档中列出的5个步骤
-
Celery工作人员无法连接到Docker实例上的Redis
问题内容: 我有一个运行Django应用程序的dockerized设置,在其中使用Celery任务。celery使用Redis作为经纪人。 版本控制: Docker版本17.09.0-CE,构建afdb6d4 docker-compose版本1.15.0,构建e12f3b9 的Django = = 1.9.6 django-celery-beat == 1.0.1 celery== 4.1.0 c
-
如何修复重启机器人后不工作的事件
我对消息的反应有问题,我让bot删除频道名称上发送的任何消息,并将其发送到另一个频道名称,并使用:white\u check\u mark:对消息作出反应,如果有人对消息作出反应时使用:white\u check\u mark:,bot将自动删除bot, 这是工作,但有一个问题,如果我重新启动机器人,并对重新启动前发送的消息作出反应,机器人不会删除消息 为什么?
-
loadbalanced Docked Flask应用程序中有多少gunicorn工作人员?
我使用Gunicorn为我的烧瓶应用程序。到目前为止,我一直遵循指导方针,因此每台机器的Gunicorn工人数量是(2 xnum_cores)1(他们坐在负载均衡器后面)。我正在处理这个应用程序,我的问题是:我应该每个容器运行一个Gunicorn工作者吗(同样,docker处理的是负载平衡的)?或者在每个Docker容器中运行多个Gunicorn工人有什么意义吗?
-
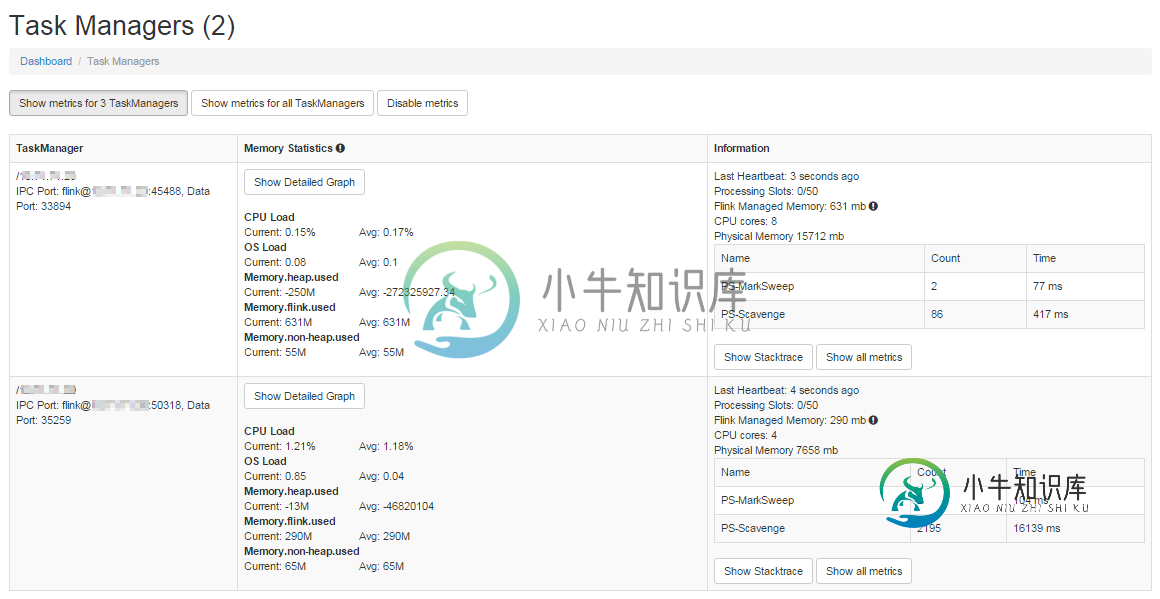 集群中的Apache Flink流不会与工人拆分作业
集群中的Apache Flink流不会与工人拆分作业我的目标是使用Kafka作为源设置一个高吞吐量集群 我在主服务器和辅助服务器上设置了一个2节点集群,配置如下。 flink-conf.yaml大师 Worker flink-conf.yaml 主节点上的文件如下所示: 两个节点上的 flink 设置位于具有相同名称的文件夹中。我通过运行 这将启动Worker节点上的任务管理器。 我的输入源是Kafka。以下是片段。 这是我的水槽功能 这是我的po
-
 为什么JavaAWT机器人不在游戏窗口上工作?
为什么JavaAWT机器人不在游戏窗口上工作?我目前正在试验java awt机器人,现在我想尝试在我的游戏窗口中按下一些东西。 为了蒸汽。exe时,我设置了以下属性:“与Windows 7的兼容性”、“始终以管理员身份运行”。 然后,我用这个启动了游戏“反击:全球进攻”。bat文件: 游戏启动了,现在我想用下面的代码点击游戏中的一些东西: 鼠标会转到正确的位置,但当它应该点击某个东西时,游戏不会做出反应或识别它。 然而,如果我不把蒸汽。exe