《运营人找工作求助阵地》专题
-
 什么是人工智能
什么是人工智能主要内容:写在前面的话,人工智能应用,人工智能发展简史,机器学习&深度学习很早就想写一门关于 Python“机器学习”的教程,不过碍于自身知识的局限性,不知如何下手。如果写的教程通篇只是探讨代码、数学知识、算法原理,这样的教程读起来必然索然无味。经过冥思苦想,终于突发灵感,可不可以写一部关于“机器学习算法”的入门教程呢?让初学者更容易理解常用的机器学习算法,从而帮助那些想要了解机器学习的人,打开通往人工智能世界的大门。 写在前面的话 机器学习是一门涉及了大量逻辑与算法的
-
蛇游戏人工智能
我正在为iOS开发一个贪吃蛇游戏:https://github.com/ScottBouloutian/Snake 我的目标是让AI以最佳方式完成蛇的游戏(让蛇填满棋盘)。 我正在使用IDA*找到一条从蛇当前位置到食物的路径。这是有效的。然而,该算法没有考虑到它将来可能需要获得更多食物的事实。因此,有时它倾向于把自己框起来。 也就是说,蛇在任何给定时间的目标都是找到食物,而它的目标应该是填满棋盘(
-
码头工人ERR_NAME_NOT_RESOLVED http ajax
问题内容: 我有3个简单的微服务(mysql,apirest,gui),我开始使用docker-compose: 在 MySQL的 和 apirest 微服务没有问题可以进行通信(我可以连接到我的数据库 apirest 使用 的MySQL 作为主机名。 但是,当我尝试使用 apirest* 作为主机名执行http请求(角度)时,我在 gui 微服务中收到以下错误: * 无法加载资源:net ::
-
TimeoutError:工人启动失败
我在jupyter笔记本电脑上的conda环境中工作。尝试使用以下过程创建客户端时 出现以下错误 回调(f)827尝试:-- 在结果(self,timeout)237中尝试:-- 提升exc信息(exc信息) 运行(自我)1068其他:- 在启动工人(自我,死亡超时,**kwargs)228个自我工人。移除(w)-- 在init(self、n_-worker、线程/worker、进程、循环、启动、
-
 闲置的火花工人
闲置的火花工人我已经配置了连接到Cassandra集群的独立spark集群,其中有1个主服务器、1个从服务器和Thrift服务器,该服务器用作Tableau应用程序的JDBC连接器。无论怎样,当我启动任何查询时,从属服务器都会出现在工作者列表中。所有工作负载都由主执行器执行。同样在Thrift web控制台中,我观察到只有一个执行器处于活动状态。 基本上,我希望火花集群的两个执行器上的分布式工作负载能够实现更高
-
动态maven人工关节
POM是否可以声明(或至少发布)包含系统属性的?我指的是实际项目的工件,而不是依赖项。 我正在使用maven构建一个scala项目,因此,为了允许为不同的scala版本发布项目,pom.xml我想声明:
-
Heroku工人没有出现
我已经将Python discord机器人部署到Heroku并启用了自动部署,但是当我转到参考资料时,我在任何地方都看不到worker,即使我已经部署了它。此外,我使用的是Github,而不是CLI (据我所知,没有文件)
-
8.3人工模型编辑
添加模型 LSV支持添加gcm,3ds,obj格式的模型,可以通过将其倒入LSV后进行一系列的操作。 首先,通过点击“添加模型”选择所需要添加的模型文件: 之后可以分别对模型的各项参数进行设置,如旋转、缩放以及其空间信息等。 模型操作 对已经加载入LSV的模型,可以通过“模型操作”对模型进行平移、升降、旋转以及缩放等操作。 并可
-
10.3人工模型编辑
添加模型 LSV支持添加gcm,3ds,obj格式的模型,可以通过将其倒入LSV后进行一系列的操作。 首先,通过点击“添加模型”选择所需要添加的模型文件: 之后可以分别对模型的各项参数进行设置,如旋转、缩放以及其空间信息等。 模型操作 对已经加载入LSV的模型,可以通过“模型操作”对模型进行平移、升降、旋转以及缩放等操作。 并可
-
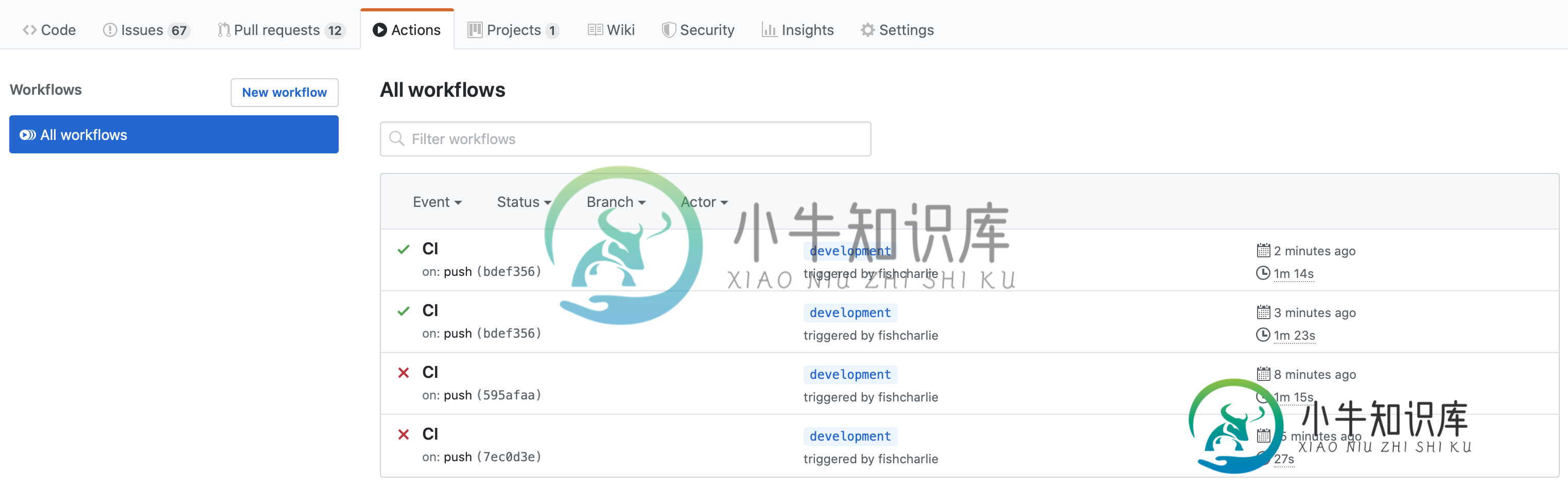 GitHub操作在错误的分支上运行工作流
GitHub操作在错误的分支上运行工作流我有以下GitHub操作的文件(删除了一些代码,以便更容易理解这个问题): 我经历了以下步骤: 在分支上进行一些提交,并推动这些更改 我期望GitHub Actions在第2项之后运行测试和部署阶段作业。但是相反,它只是再次运行,而没有运行。 如上所述,即使在推送到之后,它仍然在分支上运行,而不是在分支上运行。我有点假设这可能是由于一些奇怪的行为与快进合并。但是GitHub显然意识到我推动了,因为
-
Nodemon不工作:[Nodemon]不工作
-
如何在电报机器人运行时停止作业
我正在使用python-telegram-bot处理一个Telegram bot,我希望停止运行Telegram.job对象。 例如,我希望在hello函数处于while循环时停止运行该函数。 问题是,当我在作业开始前使用end命令时(最初10秒),它可以正常工作并停止作业,但当我在运行作业时使用end命令时,它什么也不做,因为正在运行的作业不在作业队列中。 你知道吗?如何停止正在运行的作业?
-
Jenkins和多配置(矩阵)作业
问题内容: 为什么Jenkins有两种工作,即多配置项目和自由样式项目?我读过某个地方,一旦选择其中一个,就无法(轻松地)转换为另一个。为什么我不总是选择多配置项目以确保将来的更改安全? 我想为在Windows和Unix(以及其他平台)上构建的项目设置构建。我发现了这个问题),它提出了相同的问题,但我并没有真正找到答案。为什么我需要三个矩阵项目(而不是三个自由样式项目),每个平台一个?为什么不能将
-
n乘n矩阵作业分配
我有一个家庭作业,要求我用用户输入生成一个n×n矩阵。我试过几种解决办法,但似乎都不管用。我想对你们中的许多人来说,这是一个相对简单的任务。 这是分配文本:编写一个方法,使用以下签名显示一个n×n矩阵:public static void printMatrix(int n)每个元素都是0或1,这是随机生成的。编写一个测试程序,提示用户输入n,并显示n×n矩阵。 我最近的尝试如下(显然我还没有调用
-
spark UDF对阵列进行操作
我有一个spark数据帧,如: 以 如何构造一个在列上运行的UDF,即由火花创建的包装数组,以计算变量平均值?