《快消实习》专题
-
Kafka消费者接收相同消息
我是Kafka的新手,我有一个使用Java Apache Camel库实现的Kafka消费者。我发现的问题是-消费者花了很长的时间(>15分钟)来处理很少的消息-这对于我们的用例来说是很好的。 需要一些配置帮助,因为相同的消息会在15分钟后重新发送,如果在15分钟内没有处理(我相信线程控制不会返回)。我想这可能是默认间隔,不确定这是哪一个属性。 那么,我必须在哪里修复配置 生产者级别,以便它不重新
-
阻止Kafka消费者消费信息
有什么方法可以阻止Kafka的消费者在一段时间内消费信息吗?我希望消费者停止一段时间,然后开始消费最后一条未消费的消息。
-
Kafka10.2新消费者与旧消费者
我花了几个小时想弄清楚发生了什么,但没能找到解决办法。 这是我在一台机器上的设置: 1名zookeeper跑步 我正在使用kafka控制台生成器插入消息。如果我检查复制偏移量(
-
如何消费消息从RabbitMQ在Laravel
我是一个新的学习者,试图理解拉雷维尔的拉比MQ。我已找到驱动程序vyuldashev/laravel队列rabbitmq 我已经配置应用程序/queue.php,并运行驱动程序与此语法"php工匠队列:工作Rabbitmq"。控制器。我不会在我的控制器中调度作业,因为laravel只是监听消息并处理消息。谁能帮我解释一下这是怎么回事?谢啦
-
Kafka消费群体抵消降至-1
我们在Kubernetes中基于<code>gcr.io/google_containers/Kubernetes-Kafka:1.0-10.2.1</code>docker映像运行一个Kafka集群,使用<code>gcr.io/google_containers/Kubernetes-zookeeper:1.0-3.4.10</code>,使用三个Kafka和zookeer实例。 我们有几个不
-
Kafka消费者离开消费群体
我在使用Kafka时遇到了一些问题。非常感谢任何帮助!我在docker swell中分别有zookeeper和kafka集群3个节点。您可以在下面看到Kafka代理配置。 我的情况: < li > 20x位制片人不断向Kafka主题传达信息 < li>1x消费者读取和记录消息 < li >终止kafka节点(docker容器停止),因此现在群集有2个Kafka代理节点(第3个节点将自动启动并加入群
-
取消特定的Spark日志消息
TL; DR是否有可能在不破坏所有日志的情况下抑制单个Spark日志消息? 我正在EMR上运行火花流作业,并获得日志消息,如: 在开发的这个阶段,没有一个是有用的,它掩盖了我的应用程序故意发出的真实日志。我想阻止Spark发出这些日志消息,或者禁止它们的记录。 AWS客户支持和各种答案(例如)表明,这可以通过在集群创建时传递一些JSON配置来实现。然而,由于这是一个流式作业(理想情况下,群集将永远
-
 Kafka消费者不接收旧消息
Kafka消费者不接收旧消息Kafka消费者不接收在消费者开始之前产生的消息。 ConsumerRecords始终为空 虽然,如果我启动我的消费者比生产者比它接收消息。(Kafka-客户端版本2.4.1)
-
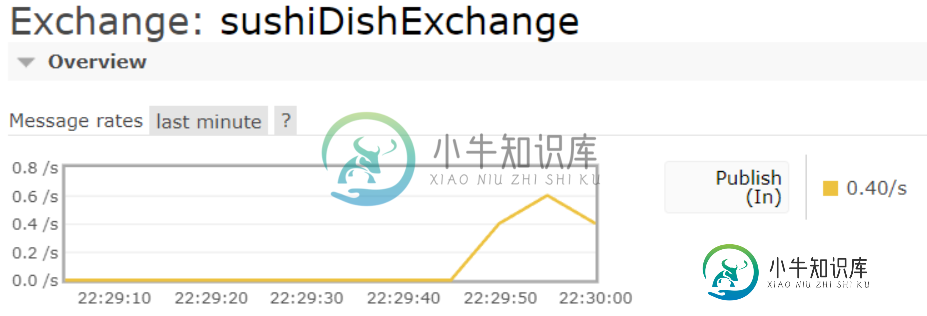 RabbitMQ直接交换不消耗消息
RabbitMQ直接交换不消耗消息我有一个服务员线程想使用RabbitMQ direct exchange向Java中的客户线程发送一道寿司,但是我的客户没有收到这道菜。下面是我的服务员用来发布寿司菜肴对象的方法: 请注意,<code>dishKey</code>作为参数传递,并在之前的if-else语句中被确定为<code>的“tamagoDishKey”</code>或<code>“ebiDishKey”的 以下是我的客户用来
-
Apache Kafka中的消息消费确认
我实现了一个Java使用者,它使用来自Kafka主题的消息,然后将这些消息与POST请求一起发送到REST API。 假设一个消息已经被使用,但是Java类未能到达REST API。消息将永远不会被传递,但它将被标记为已消耗。处理这类案件最好的办法是什么?当且仅当来自REST API的响应成功时,我能以某种方式确认消息吗?
-
Spring Kafka-消费者:未收到消息
我正在使用以下在docker上运行kafka、zookeeper和kafdrop: 我有一个具有以下配置的Spring Boot Producer应用程序-: 在我的中,我有以下内容: 这是一个单独的应用程序,我在我的服务中这样称呼Kafka制作人: 在一个完全不同的spring引导应用程序中,我有一个像这样的使用者: 我可以看到消费者正在连接到代理,但是有消息的日志。下面是我能看到的完整日志:
-
消费者连接到zookeeper而不是消息消费的代理?
启动使用者接收消息 根据我的理解,consumer直接使用来自broker的消息,但在上面的consumer命令中,我们没有提到broker,而只提到zookeeper。消费者是否会连接到zookeeper(而不是broker)来消费消息?
-
Kafka消费者正在重新消费来自主题的消息
生产者发送消息到一个有四个分区的主题。我们有一个消费者在消费来自这个主题的消息。应用程序在工作日一直运行周末例外:它不会在周末期间调用poll方法。 使用者配置:自动提交,自动提交时间为5s(默认)。 应用程序一直运行良好,直到一个星期天,当它重新开始调用poll方法。我们看到有数百万条消息从这个话题中被轮询出来。消费者基本上是轮询来自主题的所有消息。将新的偏移量与它在周末停止之前的偏移量进行比较
-
如何提高Spring Kafka消费者每批消费的消息数?
我正在构建一个使用来自Kafka主题的消息并执行数据库更新任务的Kafka消费者应用程序。消息是每天一次大批量生产的--所以该主题在10分钟内加载了大约100万条消息。主题有8个分区。 Spring Kafka消费者(使用@KafKalistener注释并使用ConcurrentKafkaListenerContainerFactory)在非常短的批处理中被触发。 批处理大小有时仅为1或2条消息。
-
 Kafka消费者仅在两条消息堆叠时读取消息
Kafka消费者仅在两条消息堆叠时读取消息我们有一个Kafka制作人,偶尔会制作一些信息。 我写了一个消费者来消费这些消息。问题是,只有当两个消息叠加时,它们才会被使用。例如,如果消息是在13:00产生的,消费者不做任何事情。如果另一条消息是在13:01生成的,则消费者会使用这两条消息。在kafkaTool中,在消费者属性中有一个名为LAG的列,当消息未被消费时,该列为1。我缺少的这个东西有什么配置吗? 消费者配置: