《大厂实习》专题
-
拆分器 - 大小与子大小标志
https://docs.oracle.com/javase/8/docs/api/java/util/Spliterator.html SIZED特征值表示在遍历或拆分之前从估计大小()返回的值表示有限大小,在没有结构源修改的情况下,表示完整遍历将遇到的元素数量的精确计数。 SUBSIZE Character 值表示 trySplit() 生成的所有拆分器都将同时具有 SIZE 和 SUBSIZ
-
Clojure性能,大向量上的大循环
我正在对大小为50,000个元素的两个向量执行基于元素的操作,并且有不满意的性能问题(几秒钟)。是否存在明显的性能问题,例如使用不同的数据结构?
-
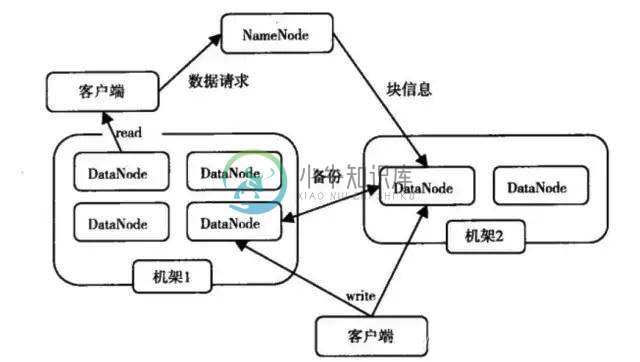 大数据技术十大核心原理
大数据技术十大核心原理主要内容:1.数据核心原理:从“流程”核心转变为“数据”核心,2.数据价值原理:有功能是价值转变为数据是价值,3.全样本原理:从抽样转变为需要全部数据样本,4.关注效率原理:由关注精确度转变为关注效率,5.关注相关性原理:由因果关系转变为关注相关性,6.预测原理:从不能预测转变为可以预测,7.信息找人原理:从人找信息,转变为信息找人,8.机器懂人原理:由人懂机器转变为机器更懂人,9.电子商务智能原理:大数据改变了电子商务模式,让电子商务更智能,科学进步越来越多地由数据来推动,海量数据给数据分析既
-
 科大讯飞一面凉经 | 大数据
科大讯飞一面凉经 | 大数据一面 共 30min 自我介绍 实习经历介绍 项目介绍:数仓分层的理解 为什么用spark而不用hadoop 为什么spark比hadoop快 spark开始计算的标志 java抽象类和接口的区别 对继承和多态的理解 最近有想要学习的新技术吗 #科大讯飞##秋招##大数据#
-
练习8:大小和数组
在上一个练习中你做了一些算术运算,并且使用了'\0'(空)字符。这对于其它语言来说非常奇怪,因为它们把“字符串”和“字节数组”看做不同的东西。但是C中的字符串就是字节数组,并且只有不同的打印函数才知道它们的不同。 在我真正解释其重要性之前,我先要介绍一些概念:sizeof和数组。下面是我们将要讨论的一段代码: #include <stdio.h> int main(int argc, char
-
G1 GC是否具有最大区域大小或最大区域数量?
问题内容: 在研究G1 GC时,我发现了这篇文章:http : //www.oracle.com/technetwork/articles/java/g1gc-1984535.html。在该文章中,内容如下: G1 GC是一个区域化的,按代划分的垃圾收集器,这意味着Java对象堆(堆)被划分为多个大小相等的区域。启动时,Java虚拟机(JVM)设置区域大小。区域大小可以从1 MB到32 MB不等,
-
调整窗口大小时自动调整文本大小(字体大小)?
问题内容: 我一直试图(徒劳地)建立一个页面,当我更改窗口大小时,其元素将重新调整大小。我可以在CSS中使用它来处理图像,但是没有问题,但是我似乎无法在文本上完成相同的操作,而且我不确定在CSS中是否有可能。而且我似乎找不到能完成此任务的jQuery脚本。 当用户调整窗口大小时,我实质上希望页面能够动态流畅地缩放,而无需用户调用页面缩放。通过css在我的img div上这可以正常工作,但对于文本则
-
我根本无法让“大口红宝石”或“大口大口”去工作
忘记vanilla sass测试,回到这里的gulp sass问题-在我的gulpfile中,我在运行递归复制任务之前运行gulp sass任务,所以如果它工作,那么应该应用并复制sass更改。至少我是这么想的。 下面是显示相关文件的dir结构: 在gulpfile.js中,有两个文件映射对象可以很好地用于src/assets/的递归副本。但是为了测试gulp-ruby-sass任务,我对SASS
-
17076203字节的突变对于16777216的最大大小来说太大了
我在cassandra设置中有“commitlog_segment_size_in_mb: 32”,但下面的错误表示最大尺寸为16777216,约为16mb。我在看修复下面错误的正确设置吗? 我指的是基于 http://mail-archives.apache.org/mod_mbox/cassandra-user/201406.mbox/<53A40144.2020808@gmail.com>中
-
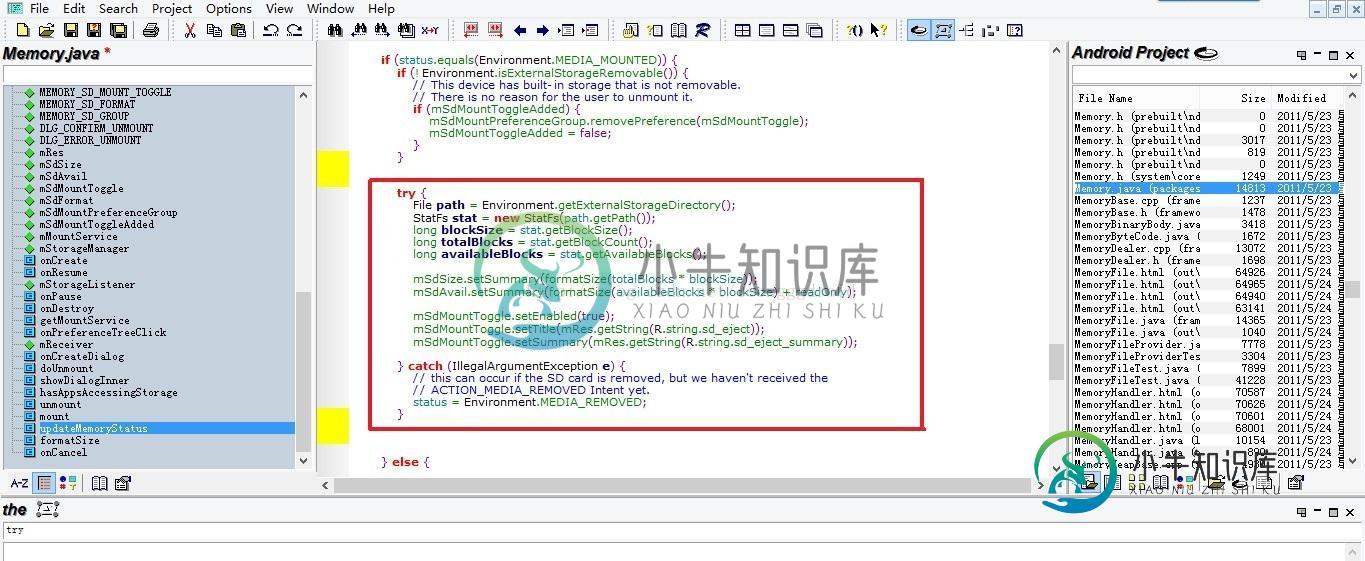 Android实现获取SD卡总容量,可用大小,机身内存总容量及可用大小的方法
Android实现获取SD卡总容量,可用大小,机身内存总容量及可用大小的方法本文向大家介绍Android实现获取SD卡总容量,可用大小,机身内存总容量及可用大小的方法,包括了Android实现获取SD卡总容量,可用大小,机身内存总容量及可用大小的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android实现获取SD卡总容量,可用大小,机身内存总容量及可用大小的方法。分享给大家供大家参考,具体如下: 可能有的同学不知道系统已经提供了获取获取SD卡总容量,可用
-
表列大小
问题内容: 在,我可以适用于在标签和随意调整表列。但是,这在Bootstrap 4中不起作用。如何在Bootstrap 4中实现类似的功能? 查看提供的codeply大小不正确,特别是如果您向表中添加一些数据。查看其运行方式: 问题答案: 更新于2018 确保您的表包含该类。这是因为Bootstrap4表是“选择加入”的,因此必须有意将类添加到表中。 Bootstrap 3.x还具有一些CSS来重
-
js module大战
本文向大家介绍js module大战,包括了js module大战的使用技巧和注意事项,需要的朋友参考一下 JS本身是一个多才多艺的语言,一个可以用自己编译自己的自由度极高的语言。正因为这份自由,出现了天花乱坠的规范与框架们,其中最基础的一块便是Module。 来来来,baby们,做个小测试: CommonJS·AMD·CMD·UMD·ES6,这些模块规范,大家熟悉几个? 注意注意:本文乃笔者主观
-
xml 大于号
本文向大家介绍xml 大于号,包括了xml 大于号的使用技巧和注意事项,需要的朋友参考一下 示例 ]]>元素内容中不允许使用字符序列。逃脱它最简单的方法是逃避>的>。
-
 山大地纬
山大地纬感觉十分友好哇,没啥技术问题,因为都是Java岗,楼主Java没啥基础,知道我是数据科学与大数据技术专业后问你觉得大数据是什么,5V特点,你认为大数据满足几个V就可以还是必须满足5V,大数据在生活中不同领域的应用有哪些,然后又问面了哪几个公司了,我说鼎信,牵扯到一点嵌入式,在产品上开发,然后问你觉得开发到产品上跟自己在电脑上写哪个更符合你的人生价值。。。大部分都是聊家常,问大学里你觉得最困难的是什
-
 大疆面试
大疆面试大疆后端 深圳互联网事业部 9.3一面,全程一个小时八股 9.17二面,类似综合面,全程大部分都是项目技术理解,性格没问,感觉对我不是很感兴趣 如果要感谢信能在一周收到吗兄弟们 9.26更新 发邮件进入评估阶段了,十月中下旬起开始陆续通知最终结果 #秋招##面经##校招##投票#