《群面模拟》专题
-
无法在spark应用程序中设置System属性[在客户端和群集模式中]
要设置,我尝试了以下方法。 方法1:使用broadcast变量将tns.ora文件复制到所有执行程序sparksession.sparkcontext()。broadcast(“/tmp/conf/”,classTagTest) 方法2:在spark submit命令中使用--files参数传递tns.ora文件,并设置--conf spark.executor.extrajavaoptions=
-
在集群环境中使用Quartz
问题内容: 我希望在我的应用程序中使用石英调度程序,因为我有一个集群环境,并且想保证每小时只能运行一个工作实例。我的问题是…我是否必须使用JDBC作业存储库或某种形式的作业数据“外部”存储库,以确保集群中只有一个实例在任何给定的时间运行该作业,或者对Quartz来说,还有更多的魔力我知道吗? 问题答案: 是的,您需要使用JDBC- JobStore或TerracottaJobStore来启用节点相
-
更新单个项目GoolgeMap集群
问题内容: 我正在使用此 libray将Android中的GoogleMap集群化。我的问题是如何更新我昨天从Google查过的单个项目,没有答案可以解释更新单个项目。我在项目中使用websocket,因此我需要更新从websocket接收到的项目数据。在下面查看我的实现。 我的概念是每当我从websocket接收数据时,就执行mClusterManager.remove(item)mCluste
-
Redis Pods无法加入Redis集群
问题内容: 我想在Kubernetes中创建6个节点的Redis集群。我正在使用 Minikube 运行 kubernetes 。 以下是我创建6节点群集的实现。 创建有状态集之后,我将从一个Pod内部执行redis create cluster命令。 这些都是pod的ips。有了这个,我就能启动集群了。但是一旦我手动删除使用 例如,删除IP地址为172.17.0.6:6379的Redis节点(假
-
如何在pandas群中使用cumsum?
问题内容: 我有 我想为每个运行一些,所以所需的输出如下所示: 这是我尝试的: 和 这是我得到的错误: 问题答案: 您可以调用并传递函数以将该列添加到df中: 关于错误,您无法调用Series groupby对象,其次,您将列名作为无意义的列表传递。 所以这有效:
-
Elasticsearch 5.0.0。群集节点未加入
问题内容: 好的,这应该不难,我试图在Elasticsearch集群中运行2个节点,并在尝试启动node-1(作为主节点的node-2已经启动)时遇到异常。对两个实例都使用elasticsearch v 5.0.0 例外: 无法将加入请求发送到主节点,原因是RemoteTransportException无法添加找到的具有相同ID但却是不同节点实例的现有节点的节点] 节点1配置: 节点名称:SAN
-
Elasticsearch:如何删除(群集)设置
问题内容: 我当前的光泽配置设置如下所示: 并且想知道如何删除设置的 “ max_bytes_per_sec” 部分。 你能给我一个建议吗? 问题答案: 好的。我发现了如何删除持久性设置:您转到主节点的已定义数据路径,更具体地说(在我的情况下),然后删除全局状态文件。然后重新启动elasticsearch。
-
在群集节点上设置vm.max_map_count
问题内容: 我尝试在Google Container Engine的群集节点上安装ElasticSearch(最新版本),但是ElasticSearch需要变量:>> 262144。 如果我ssh到每个节点并手动运行: 一切正常,但是任何新节点将没有指定的配置。 所以我的问题是: 有没有办法在引导时在每个节点上加载系统配置?Deamon Set并不是一个好的解决方案,因为在Docker容器中,系统
-
Swift中的自定义类集群
问题内容: 它允许您从调用中返回子类。 我正在尝试找出使用Swift实现相同功能的最佳方法。 我确实知道,很可能有一种更好的方法可以用Swift实现相同的目的。但是,我的类将由我无法控制的现有Obj- C库初始化。因此,它确实需要以这种方式工作并且可以从Obj-C调用。 任何指针将不胜感激。 问题答案: 我不相信Swift可以直接支持这种模式,因为初始化程序不会像在Objective C中那样返回
-
限制Hazelcast群集中的成员
我正在进行一个Spring启动项目,我使用Hazelcast作为缓存。我启用了tcp作为连接方法,我还提到了一些成员。会员可以加入。但问题是其他节点也可以加入除了成员。有人能告诉我如何限制它吗? 这是我的配置,
-
Akka集群”连接拒绝”混淆
我一直在通过Akka示例集群应用程序教程和本文档研究Akka集群。我让它在本地运行(127.0.0.1),但我似乎无法使用我的静态IP(192.168.0.99)让它工作。我这样做是为了快速检查是否正常,因为我在尝试使用我的Raspberry Pi作为节点时收到了类似的消息。 [警告][05/30/2016 11:01:41.432][ClusterSystem akka.remote.defau
-
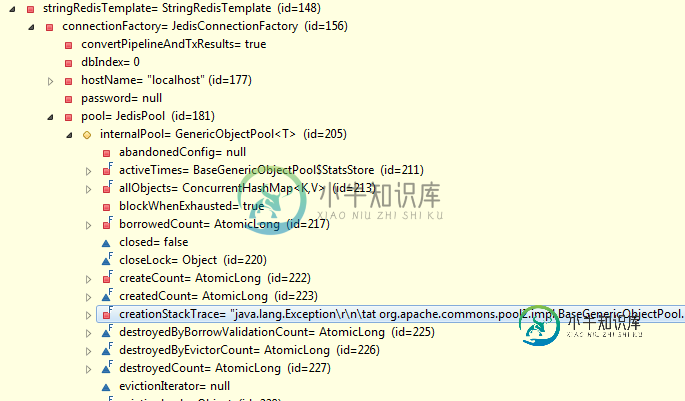 Redis集群与Spring boot的集成
Redis集群与Spring boot的集成我有一个redis集群,有主服务器、从服务器和3个哨兵服务器。主从映射到dns名称node1-redis-dev.com、node2-redis-dev.com。redis服务器版本为2.8 我在application.properties文件中包含以下内容。 但是,当我检查StringRedisTemplate时,在JedisConnectionFactory的hostName属性下,我看到的是
-
获取Kafka connect集群的信息
我目前使用的是Kafka connect集群,它有两个节点,使用的是同一个 当使用curl/connectors时,我可以获得创建的连接器列表,但我看不到有关活动节点的信息,健康检查。。。
-
发生错误时释放羊群?
问题内容: 想象以下Perl代码(此处为伪代码): 在这种情况下,由于Perl脚本在第2行结束,因此我不会释放该锁。在这种情况下,操作系统是否曾经释放过该锁?它是否看到“嘿,获取锁的脚本崩溃了”并释放了锁?它会立即释放锁吗?另外,是否为每个脚本运行一个Perl实例,以便清楚地知道哪个脚本崩溃/停止而不释放锁? 问题答案: 在那种情况下,操作系统是否释放过该锁? 它是否看到“嘿,获取锁的脚本崩溃了”
-
Linux群,如何“仅”锁定文件?
问题内容: 在Bash中,我试图使函数getLock与不同的锁名一起使用。 但是羊群说 如何仅锁定文件并在需要时释放它,而不必在集群中执行命令? 它的用法如下: 问题答案: 锁定文件: 释放锁: 您也可以按照羊群手册页中的描述进行操作: …在这种情况下,文件退出时文件会自动关闭。(在这里也可以通过使用而不是来使用子外壳,但这应该是一个有意的决定- 因为子外壳会降低性能,并且会影响范围变量的修改和其