《米哈游笔试有多难》专题
-
具有多个字段的类的字段的测试状态
我只看到两种方法: 将所有字段设置为受保护(或包可见性) 为所有字段生成50个getter 创建50个委托方法来获取这些字段的状态,而不是整个对象的状态 在正常情况下,我会选择最后一个(尽管我真的不想仅仅出于测试的原因而改变界面)。但是在我的类中编写50个新方法只是为了测试真的有意义吗?在这种情况下,将字段设置为受保护的不是更好吗,因为有这么多方法,类会变得不清楚? 注意。反射是我想使用的最后一个
-
尝试将LabelEncoder和OneHotEncoder用于具有多列的数据集
我试图转换多个列,其中有一组分类值中的数据;但我在使用OneHotEncoder时遇到了一个错误 我的数据框 1) 分离X_普查和Y_普查中的列(X_普查包含分类值): 2)使用LabelEncoder处理X_census的分类值: 从sklearn。导入标签编码器的预处理 3)现在使用OneHotEncoder到我的X_2转换分类到数值: 错误
-
在Arquillian中集成测试具有许多依赖项的EJB
我经常使用依赖于几个(比如5-10个)其他EJB/CDI bean的EJB,并且许多方法只使用它们的一个子集。集成测试(我们将Arquillian与嵌入式GlassFish4.0容器一起使用)它们是痛苦的,因为我仍然必须为整个类图提供依赖关系。我一个接一个地将类添加到ShrinkWrap归档中,因为添加整个包会创建更多的依赖关系,我不想添加所有类,因为这会显著增加完成一个测试所需的时间。我也不希望
-
pythonselenium多个测试用例
问题内容: 我在python中有以下代码 我的问题是在test_home_page函数之后,firefox实例关闭并为下一个test_whatever函数再次打开。我该怎么做,以便所有测试用例都从同一firefox实例执行。 问题答案: 在以下位置初始化firefox驱动程序:
-
尝试/多发vs单发
问题内容: 在Eclipse中添加try / catch块时,它为我提供了“使用try / catch进行环绕”或“使用try / catch进行环绕”的选项。 这是try / multi-catch: 这是单个try / catch: 使用一种或另一种有什么好处/影响?如果我是正确的话,第一个示例将在抛出异常时执行catch块并产生SAME CATCH,而第二个示例将在启用单独的catch块的同
-
Spock测试:调用太多
编辑: 链接到repo示例:https://gitlab.com/bartekwichowski/spock-too-many
-
Flink-多源集成测试
我有一个Flink作业,我正在使用这里描述的方法进行集成测试:https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/testing.html#integration-testing 作业从两个源获取输入,这两个源组合在一个中。在测试环境中,我目前使用两个简单的SourceFunction来发出值,但是这不提供对事件发出顺
-
多部分MockMvcSpring测试后
我正在尝试测试我的上传我是usig Junit,Mockmvc和Spring 你能帮帮我吗? 错误堆栈跟踪: [org.springframework.test.context.support.dependencyinjectiontestexecutionlistener@361cb7a1]准备测试实例[endpoint.security.tests.uploadtest@6F7918F0]or
-
测试 - 多工程报告
5.4.2 多工程报告 在一个既有应用工程又有库工程的多工程里,当在同时运行所有测试的时候,生成一个包含所有测试结果的报告是非常有用的。 为了达到这一目的,需要同一构件中的另外一个插件,可以通过如下方式应用: buildscript { repositories { mavenCentral() } dependencies { classp
-
如何设置(覆盖)哈希中的所有项目
问题内容: 我想在哈希中设置所有条目。(SetAllEntriesToHash) 它必须在运行之前清除哈希中的所有项目。 它与GetAllEntriesFromHash相反。 问题答案: 您在这里有几个选择。 1) 您可以通过使用高级Redis API让ServiceStack为您解决此问题。 这种方法将使您不必直接处理散列细节。ServiceStack会为您解决所有问题,并将您发送的对象自动填充
-
使用乘法的哈希函数有什么缺点
问题内容: 几乎每本教科书和CS课程都引用了两种实现哈希函数的基本方法: 除法 ,我们只需要简单地选择m作为素数就不太接近2的幂。 乘法方法 是将k与0到1之间的某些非理性选择数(Knuth建议使用基于黄金比率的数)相乘,取乘积的小数部分,并从中使用所需数目的最高有效位。 大多数教科书和课程都列举了方法1的几个缺点,包括方法昂贵且取决于m的事实。但是,我从未见过任何教科书或课程提到方法2的单一缺点
-
Java:有效地计算大文件的SHA-256哈希
问题内容: 我需要计算大文件(或其一部分)的SHA-256哈希。我的实现工作正常,但比C 的CryptoPP计算要慢得多(25分钟vs. 30 GB文件的10分钟)。我需要的是在C 和Java中执行时间相似,因此散列几乎可以同时准备好。我也尝试了Bouncy Castle的实现,但是它给了我相同的结果。这是我如何计算哈希值: 问题答案: 我的解释可能无法解决您的问题,因为它很大程度上取决于您的实际
-
相同的键 - 具有哈希映射的不同值
我会从我想达到的目标开始 意图 该软件在for循环中解析XML数据。处理数据的 for 循环将持续到 50(因为我得到了 50 个不同的结果)。我最初所做的是,-方法解析整个XML数据并将其保存到TextViews中并显示它。但现在我想添加一个启动画面,只要数据加载就会显示。 XML文件像任何其他普通XML文件一样构建,因此当我通过for循环时,键总是相同的,但值不同。 方法 我已经做的是创建一个
-
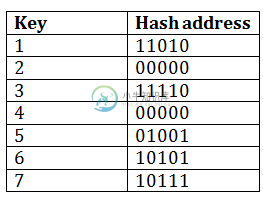 DBMS动态哈希
DBMS动态哈希主要内容:如何搜索一个键,如何插入新记录动态哈希方法用于克服桶溢出等静态哈希问题。 在此方法中,随着记录的增加或减少,数据桶会增大或减小。 此方法也称为可扩展哈希方法。 该方法使哈希动态化,即,它允许插入或删除而不会导致性能不佳。 如何搜索一个键 首先,计算键的哈希地址。 检查目录中使用了多少位,这些位称为。 取哈希地址的最不重要的位。 这给出了目录的索引。 现在使用索引,转到目录并查找记录可能位于的存储区地址。 如何插入新记录 首先,
-
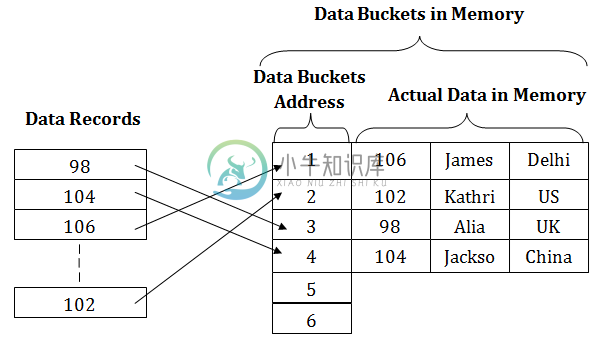 DBMS静态哈希
DBMS静态哈希主要内容:静态哈希的操作,1.打开散列,2.关闭哈希在静态哈希中,结果数据桶地址将始终相同。 这意味着如果使用散列函数生成地址,那么它将始终产生相同的桶地址。这里,桶地址不会有任何变化。 因此,在这种静态散列中,内存中数据桶的数量始终保持不变。 在这个例子中,在内存中有五个数据桶用于存储数据。 静态哈希的操作 搜索记录 - 当需要搜索记录时,相同的哈希函数检索存储数据桶的地址。 插入记录 - 当一个新记录插入表中时,将根据哈希键为新记录生成一个地址