《拼多多校招》专题
-
用quarkus:dev构建多模块maven中的多个quarkus应用程序
我有一个包含多个应用程序(不同但密切相关的微服务)的解决方案,这些应用程序共享通用且相当复杂的代码。该项目使用Maven,当前设置为: 我的问题是我想使用开发模式来获取更改,但我无法使其工作。对于单个Quarkus应用程序,它受到支持,并且可以从根文件夹使用quarkus:dev进行构建。对于两个Quarkus应用程序,不清楚启动的是哪一个。 我可以使用Maven的选项来选择我想要启动的那个,但是
-
如何设计任务处理的多线程/多进程系统
我有以下的要求要设计。 有多个作业要完成。每个作业都有一个作业id和一个系统id。作业id是唯一的,但同一系统id可能有多个作业 应顺序处理给定系统id的作业 其中某些作业可能处于等待状态,如果处于等待状态,则在x秒/分钟之前不应重新尝试返回 系统约束 唯一系统ID的数目可以是lakhs 每个系统ID的作业数可以是lakh 我曾考虑过使用kafka,但如果一个系统被阻塞,那么该分区中不同系统的所有
-
春季启动时两个实体之间的多对多关系
问题内容: 我的Spring-Boot应用程序中有两个实体: User.java 和 角色.java 对于我的MySql数据库 我已经排除了此问题的getter和setter方法。 我想实现两个实体之间 的多对多关系 。每个用户都应该能够为其分配多个角色 我已经为数据库中的两个表创建了一个映射表。它有行 用户身份 role_id。 我还创建了一个新的Entity UserRole.java ,如下
-
请你说一下多进程和多线程的使用场景
本文向大家介绍请你说一下多进程和多线程的使用场景相关面试题,主要包含被问及请你说一下多进程和多线程的使用场景时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 多进程模型的优势是CPU 多线程模型主要优势为线程间切换代价较小,因此适用于I/O密集型的工作场景,因此I/O密集型的工作场景经常会由于I/O阻塞导致频繁的切换线程。同时,多线程模型也适用于单机多核分布式场景。 多进程模型,适用于C
-
SQL Server INNER JOIN具有多个关系的多个内部联接
问题内容: 我有以下查询。它工作正常,但我需要从另一个名为FB的表中提取BUserName,该表具有与FU表中的UserID相关的UserID字段。这可能吗? 只是为了澄清。我在FB表中没有UserName列。它确实有FB.UserID,它与FF.UserID有关系,这是我要从中提取第二个UserName的地方。因此,通过这种关系,我试图从与FB表中的userID相关的FF.UserID表中拉出用
-
Django ORM多对多查询方法(自定义第三张表&ManyToManyField)
本文向大家介绍Django ORM多对多查询方法(自定义第三张表&ManyToManyField),包括了Django ORM多对多查询方法(自定义第三张表&ManyToManyField)的使用技巧和注意事项,需要的朋友参考一下 对于多对多表 - 1.自定义第三张表,更加灵活 - 2.ManyToManyField 自动生成第3张表 只能 有3列数据 不能自己添加。 自定义第三张表 ManyTo
-
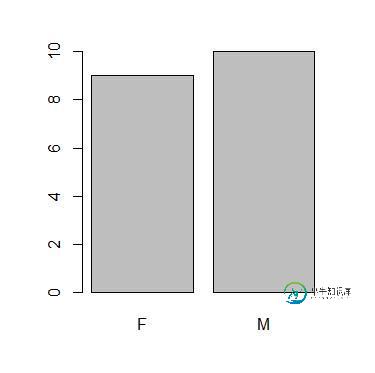 R语言基本画图函数与多图多线的用法
R语言基本画图函数与多图多线的用法本文向大家介绍R语言基本画图函数与多图多线的用法,包括了R语言基本画图函数与多图多线的用法的使用技巧和注意事项,需要的朋友参考一下 常用统计作图函数汇总 plot() hist() 直方图 stem() 茎叶图 boxplot() 箱线图(盒形图) coplot() 协同图 qqnorm() 正态qq图 qqplot() 两总体qq图 1. 高级低级图形函数的常用选项 高、低级图形函数概述 高级图
-
 Yii2中hasOne、hasMany及多对多关联查询的用法详解
Yii2中hasOne、hasMany及多对多关联查询的用法详解本文向大家介绍Yii2中hasOne、hasMany及多对多关联查询的用法详解,包括了Yii2中hasOne、hasMany及多对多关联查询的用法详解的使用技巧和注意事项,需要的朋友参考一下 前言 hasOne、hasMany是Yii2特有的用于多表关联查询的函数,平时在使用多表关联查询的时候建议使用它们。为什么?因为这种方式关联查询出来的结果会保留Yii2自有的表头排序功能,以及Checkbox
-
从PostgreSQL中的子查询更新或插入(多行和多列)
问题内容: 我正在尝试在postgres中执行以下操作: 但是,即使使用文档(http://www.postgresql.org/docs/9.0/static/sql- update.html )中提到的postgres 9.0,也无法实现第1点 同样,第二点似乎不起作用。我收到以下错误:子查询必须仅返回一列。 希望有人对我有解决方法。否则查询将花费大量时间:(。 仅供参考:我正在尝试从几张表中
-
禁止直接分配给多对多集的正面。改用emails_for_help.set()
问题内容: 我是Django的新手,但未找到有关此问题的任何参考。当我在Django模型()中使用多对多字段时,出现此错误。我猜问题是在form()的view()中分配m2m字段。 如何在视图中分配m2m字段?(,) models.py views.py 表格 问题答案: 你需要获取User对象,然后将其添加到字段中。创建实例时,不能向其添加对象。看一下doc。 编辑 这样做的另一种方法是使用。
-
使用python将多页pdf文件拆分为多个pdf文件?
问题内容: 我想要一个多页的pdf文件,并每页创建单独的pdf文件。 我已经下载了reportlab并浏览了文档,但它似乎是针对pdf生成的。我还没有看到有关处理PDF文件本身的任何信息。 有没有一种简单的方法可以在python中做到这一点? 问题答案: 等等
-
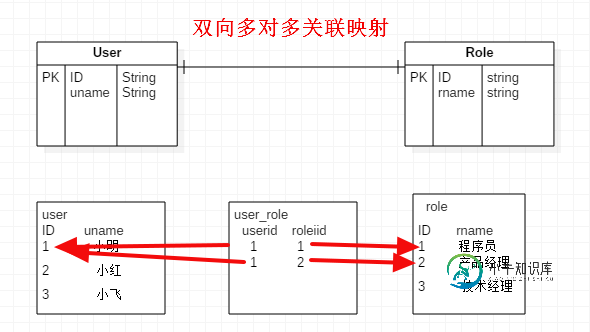 详解hibernate双向多对多关联映射XML与注解版
详解hibernate双向多对多关联映射XML与注解版本文向大家介绍详解hibernate双向多对多关联映射XML与注解版,包括了详解hibernate双向多对多关联映射XML与注解版的使用技巧和注意事项,需要的朋友参考一下 双向多对多关联映射原理: 假设,一个员工可能有多个角色,一个角色可能有多个员工,从员工或角色的角度看,这就是多对多的关系,不管从哪一个角度看,都是多对多的联系。多对多关联映射关系一般采用中间表的形式来实现,即新增一种包含关联双方
-
如何枢纽?如何将多行转换为多列的一行?
问题内容: 我有两个表要合并。第一个表与客户一起使用,另一个表与产品一起使用。目前,我有22种产品,但我希望有一个灵活的数据库设计,因此与其在产品数据库中没有22列,我为每个客户为每个产品提供1行,所以如果我总体上添加或删除1种产品,我不会必须更改数据库结构。 我想有一条select语句,在这里我为每个客户端选择所有产品,并且输出应该在一行中,每个产品都有一列。 我看到了其他一些类似的问题,但这样
-
NodeJS批处理多处理池(或多线程)中的子进程
我知道子进程是进程,而不是线程。我使用了错误的语义,因为大多数人在谈到“多线程”时都知道您的意图。所以我会把它保留在标题中。 想象一下这样一个场景:使用一个自定义函数或模块,您连续有多个类似和复杂的事情要做。使用所有可用的核心/线程(例如8/16)非常有意义,这就是的目的。 理想情况下,您需要多个同时工作的人员,并向一个控制器发送/从一个控制器发送/回调消息。 node cpool、fork po
-
一次将多个值分配给numpy数组的多个切片
我有一个numpy数组,一个定义数组中范围的开始/结束索引列表,以及一个值列表,其中值的数量与范围的数量相同。在循环中执行此赋值当前非常慢,因此我想以矢量化的方式将值赋给数组中的相应范围。这可能吗? 这是一个具体的简化示例: <代码>a=np。零([10]) 下面是定义a中范围的开始索引和结束索引列表,如下所示: 这是我想分配给每个范围的值列表: <代码>值=[1、2、3、4] 我有两个问题。首先