《久邦数码》专题
-
Apache Kafka持久化所有数据
我见过(旧?),我一直在考虑使用压缩键,但是对于kafka来说,是否有一个简单的选项可以永远删除消息? 或者最好的选择是给保留期一个可笑的高值?
-
@JmsListener和持久化到数据库
我正在开发一个服务,在该服务中,我侦听队列,反序列化接收到的消息,并将它们持久化到数据库(Oracle)。大致情况: 在缺省消息侦听器bean中,我设置并发性和setSessionTransactived(true)。这足以使整个onMessage具有事务性吗?因此,在一个事务中接收并保存一条消息,并在其中任何一点出现故障时回滚?当试图保存特定消息时,我尝试对其抛出异常,消息确实被回滚到队列,侦听
-
2.5 数据共享与持久化
这一节介绍如何在 Docker 内部以及容器之间管理数据,在容器中管理数据主要有两种方式: 数据卷(Data Volumes) 挂载主机目录 (Bind mounts) 数据卷 数据卷是一个可供一个或多个容器使用的特殊目录,它绕过UFS,可以提供很多有用的特性: 数据卷 可以在容器之间共享和重用 对 数据卷 的修改会立马生效 对 数据卷 的更新,不会影响镜像 数据卷 默认会一直存在,即使容器被删除
-
持久化
Akka持久化使有状态的actor能留存其内部状态,以便在因JVM崩溃、监管者引起,或在集群中迁移导致的actor启动、重启时恢复它。Akka持久化背后的关键概念是持久化的只是一个actor的内部状态的的变化,而不是直接持久化其当前状态 (除了可选的快照)。这些更改永远只能被附加到存储,没什么是可变的,这使得高事务处理率和高效复制成为可能。有状态actor通过重放保存的变化来恢复,从而使它们可以重
-
WSO2在尝试联邦登录时引发EmptyStackException
详细日志:
-
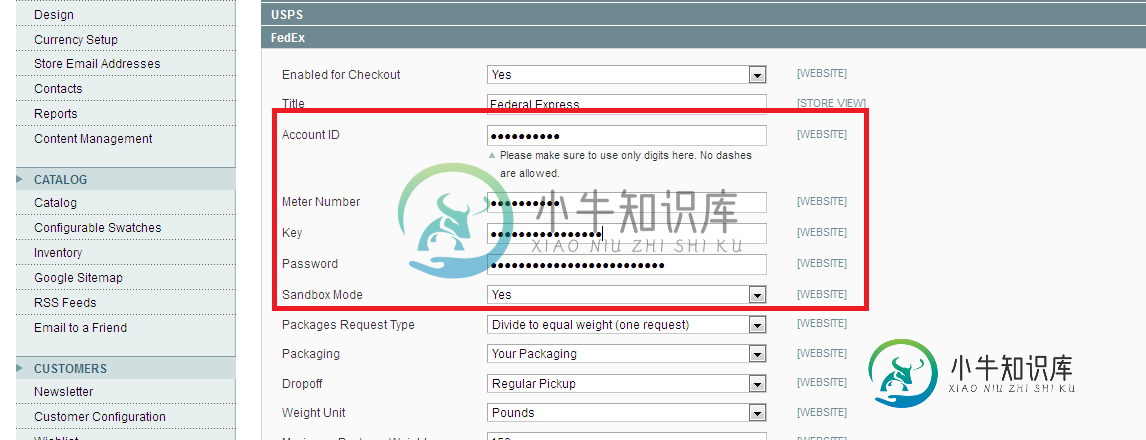 magento中联邦快递配送方法错误
magento中联邦快递配送方法错误 -
使用联邦快递api(php)创建发货
我需要创建使用联邦快递api到我的网站发货。 首先,我通过多速率服务API检查可用的服务,它给我的结果如下: 已返回以下服务类型的费率。 这很简单,但是当我想为上述服务创建出货时,我不确定使用哪一个,因为应用编程接口被进一步分为 快递*(国内/国内MPS/国际) 现在,如何知道哪个服务属于哪个部分来发送一个有效的添加发货请求。 这几天我一直在努力寻找解决方案,所以如果有人实施了它,请告诉我正确的方
-
Redis是持久数据存储区吗?
问题内容: 我所说的“耐用”是指服务器可以随时崩溃,只要磁盘保持完好无损,就不会丢失任何数据(请参阅ACID)。好像这就是日记模式的用途,但是如果启用日记功能,这是否会破坏对内存数据进行操作的目的?读操作可能不受日记影响,但是日记似乎会破坏您的写入性能。 问题答案: 即使使用日志记录,Redis 通常 也不会部署为“耐用”数据存储(在ACID中为“ D”的含义)。大多数用例有意牺牲一些耐用性以换取
-
Python-保存对象(数据持久性)
问题内容: 我创建了一个这样的对象: 我想保存该对象。我怎样才能做到这一点? 问题答案: 你可以使用标准库中的模块。这是你的示例的基本应用: 你还可以定义自己的简单实用程序,如下所示,该实用程序打开文件并向其中写入单个对象: 更新资料 由于这是一个非常受欢迎的答案,因此,我想谈谈一些高级用法主题。 实际使用该cPickle模块几乎总是可取的,而不是因为该模块是用C编写的并且速度更快。它们之间有一些
-
vuex实现数据状态持久化
本文向大家介绍vuex实现数据状态持久化,包括了vuex实现数据状态持久化的使用技巧和注意事项,需要的朋友参考一下 用过vuex的肯定会有这样一个痛点,就是刷新以后vuex里面存储的state就会被浏览器释放掉,因为我们的state都是存储在内存中的。 所以我们通过 vuex-persistedstate这个插件,来实现将数据存储到本地 用法很简单 1、 2、 以上这篇vuex实现数据状态持久化就
-
Python Sqlite3-数据不会永久保存
问题内容: 我对 SQLite3 和 Python 3 做错了。也许我误解了SQLite数据库的概念,但是我希望即使关闭应用程序后,数据仍存储在数据库中?当我插入数据并重新打开应用程序时,插入物消失了,数据库为空。 这是我的小数据库: 我在哪里做错了? 问题答案: 调用以将事务刷新到磁盘。 程序退出时,最后一个未完成的事务将回滚到最后一个提交。(或更准确地说,回滚是由下一个打开数据库的程序完成的。
-
数据库的Redux状态持久性
问题内容: 从这里的讨论看来,Redux reducer的状态应该保留在数据库中。 用户身份验证在这种情况下如何工作? 是否不会创建新的状态对象来替换数据库中先前创建和编辑的每个用户(及其应用程序状态)的先前状态? 在前端使用所有这些数据并不断更新数据库中的状态是否会表现出色? 编辑: 我创建了一个示例Redux auth项目,该项目也恰好示例了通用Redux,并使用Redux,Socket.io
-
pandas中的大型持久数据帧
作为一个长期的SAS用户,我正在探索切换到python和pandas。 然而,在今天运行一些测试时,我很惊讶python在尝试一个128MB的csv文件时内存耗尽。它大约有200,000行和200列,大部分是数字数据。 使用SAS,我可以将csv文件导入SAS数据集,并且它可以和我的硬盘一样大。 中有类似的内容吗? 我经常处理大文件,没有访问分布式计算网络的权限。
-
docker容器的持久化数据库
我在我的项目中使用postgres docker映像。对于初始化,我使用以下命令来创建和初始化我的数据库(表、视图、数据…) 复制sql_dump.sql /docker-entrypoint-initdb.d 容器停止和删除后是否可以保留这些数据?例如,当我运行postgres的图像时,它将使用这些数据创建数据库,而每次容器启动时都没有加载脚本。只需加载第一次运行创建的数据。 我做了一些研究,发
-
使用docker卷持久化数据库