《产品经理必备工作技能》专题
-
 产品经理面试题,你做的最满意的一个项目是什么?
产品经理面试题,你做的最满意的一个项目是什么?产品经理面试的时候常问的题目:“你最满意(或者最有成就感)的一个项目是什么,或者请介绍下你最满意的一个项目。” 一般最有成就感的项目,面试者都会提前准备过,所以对于详细准备了面试腹稿的同学,这道题其实是一份送分题。 但是对于一些完全没有准备的面试者,如果这个问题都回答不好,可能就直接就被pass了。 那么这道题主要考察求职者哪些能力和技能呢? 其实面试官想通过这道题考查候选人的问题分析、思考深度、
-
 校招提前批·广联达产品经理offer|23届,千字求职复盘!
校招提前批·广联达产品经理offer|23届,千字求职复盘!1、一些面经 4月24日,27分钟,问的比较全面,学习经历和专业选择(1-4)、项目经历和实习经历都问到了。 在前面专业选择部分偏向聊天,面试官想了解这个专业的发展和未来就业方向。 整体面试不难,都是准备过的问题。面试官说这轮是产品能力面试,后面专业面试可能会涉及到一些建筑行业的知识。 你学XX专业为什么想做产品? 专业就业方向,研究生做的方向。 面试官聊了聊她学XX的同学的出路好多也都转行了。
-
 微众银行产品经理暑期offer+2|1W+薪酬,4轮面试分享
微众银行产品经理暑期offer+2|1W+薪酬,4轮面试分享具体面经 一面(12min) 自我介绍 介绍专业 为什么不做本行业 你对产品经理的理解 通过什么渠道知道微众银行? 讲一下你最近的实习工作中的一些亮点 为什么没有打算在之前的公司考虑转正? 你在北京吗?想来深圳?哪里人?哪一年的? 你在工作中认为自己是一个主动的人吗? 未来3年职业规划? 未来工作中遇到不喜欢的人,你需要和他一起公事你如何应对? 你有没有收到其他大公司的offer?收到几家? 二面
-
 广联达产品经理offer+5|0实习拿到23届校招提前批!
广联达产品经理offer+5|0实习拿到23届校招提前批!一、具体面经 一面 (37min) 自我介绍 是怎么了解到广联达这个公司的? 为什么想做产品经理? 产品经理在工作中会接触到很多的人,你是怎么理解这个角色? 会接触到哪些人呢? 怎么去和不同的人沟通呢?有什么样的沟通方式和策略吗? 对编程技术了解吗? 谈谈你对广联达的了解 有什么常用的产品吗? 看你的简历发现你的项目经历还是很丰富,包括你也提到平时会做一些输入输出,那你是怎么了解和学习其他领域的知
-
 【AI求职系列】2道AI产品经理面试高频问题及答案
【AI求职系列】2道AI产品经理面试高频问题及答案之前的系统整理过AI产品面试的高频30个问题,如果大家最近打算找这方面的工作,可以对照着脑图准备起来啦。 具体答案参考下面的文章: 这篇文章给大家讲解两道高频问题: 1)AI产品经理和传统产品经理有什么区别 2)AI 产品经理的工作职责和能力要求是什么? 这两个问题看似简单,实际上是面试官在考察面试者对 AI 产品经理这个岗位的理解程度,以及你到底有没有相关的实战经验,以及在工作中有没有独立的思考
-
产品经理 - PC端的表单在移动端的展示该怎么设计?
PC布局横向的,放的字段很多。手机是竖向的,展示不了几个字段。如果竖向展示数据,类似卡片式那样,展示的字段多了 一页下来也看不了几条。
-
 字节-产品运营实习生-作者增长
字节-产品运营实习生-作者增长1.自我介绍 2.问了我简历上mysql项目 3.问了网易实习经历 4.问了对岗位的理解 总共30分钟 面试官人很善良,给了很多的鼓励,但是是抖音板块的产品运营,我指定是陪跑了 #面经# #字节# #产品# #实习,投递多份简历没人回复怎么办# #找实习多的是你不知道的事#
-
 字节-产品运营实习生-作者增长
字节-产品运营实习生-作者增长面的有点快昨天一面今天二面 1.自我介绍 2.网易的工作内容经历 3.工作中的协同沟通问题的解决 4.如何理解产品运营 5.岗位的理解 6.问了问我字节校园大使(有点懵) 7.有没有想做其他方向 8.到岗时间和base上海能不能接受 反问 岗位的核心能力怎么提高 总体来说,面试官跟一轮面试官一样人非常善良,一直鼓励我说,也提出了我的未来发展建议。 我觉得面试可能到这就终止了,但是确实很好的经历 #
-
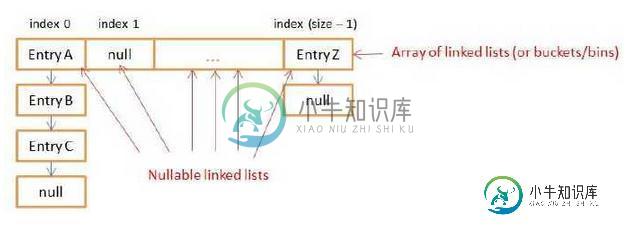 Java HashMap的工作原理
Java HashMap的工作原理本文向大家介绍Java HashMap的工作原理,包括了Java HashMap的工作原理的使用技巧和注意事项,需要的朋友参考一下 大部分Java开发者都在使用Map,特别是HashMap。HashMap是一种简单但强大的方式去存储和获取数据。但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.HashMap的大量源代码(包括Java 7 和Java 8),来深入理
-
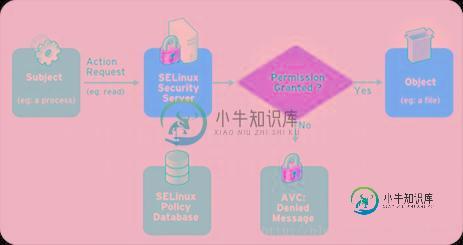 SELINUX工作原理详解
SELINUX工作原理详解本文向大家介绍SELINUX工作原理详解,包括了SELINUX工作原理详解的使用技巧和注意事项,需要的朋友参考一下 1. 简介 SELinux带给Linux的主要价值是:提供了一个灵活的,可配置的MAC机制。 Security-Enhanced Linux (SELinux)由以下两部分组成: 1) Kernel SELinux模块(/kernel/security/selinux
-
Swarm模式工作原理
本章节将从一下几个方面介绍Docker Engine Swarm模式下的工作原理: 节点工作原理 Service工作原理 安全(PKI) Task的状体啊
-
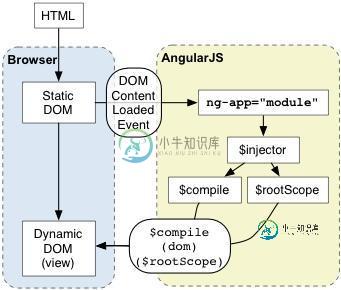 AngularJS 工作原理详解
AngularJS 工作原理详解本文向大家介绍AngularJS 工作原理详解,包括了AngularJS 工作原理详解的使用技巧和注意事项,需要的朋友参考一下 个人觉得,要很好的理解AngularJS的运行机制,才能尽可能避免掉到坑里面去。在这篇文章中,我将根据网上的资料和自己的理解对AngularJS的在启动后,每一步都做了些什么,做一个比较清楚详细的解析。 首先上一小段代码(index.html),结合代码我们来
-
MaxTenuringThreshold-工作原理如何?
问题内容: 我们知道,主要的内存域很少:Young,Tenured(Old gen)和PermGen。 年轻领域分为伊甸园和幸存者(两个)。 OldGen用于保留对象。 MaxTenuringThreshold可以防止将对象最终过早地复制到OldGen空间。这很清楚而且可以理解。 但是它如何工作?垃圾收集器如何处理这些仍存活到MaxTenuringThreshold的对象,并且以什么方式处理?他们
-
Geoserver工作区和代理
以下URL请求在浏览器上工作: http://localhost:12018/geoser/geonode/ows?service=wfs&version=1.0.0&request=getfeature&typename=my_data_name35&maxfeatures=50&outputformat=application%2fjson 使用typeName作为geonode:my_dat
-
Vertx JDBC的工作原理
Vertx使用一个辅助线程来执行select语句,以避免阻塞事件循环线程,但是在这种情况下,每个sql查询都需要一个单独的线程来执行。但是如果Vertx不使用任何单独线程来执行查询呢?在这种情况下,事件循环如何知道结果何时来自DB呢?使用线程就很简单了,事件循环可以检查jdbc查询使用的线程的当前状态,如果状态准备就绪,就意味着事件循环应该执行回调 我说得对吗?