《酷狗音乐》专题
-
 字节抖音一面
字节抖音一面分不清是实习还是提前批,还是秋招,问了面试官也分不清,就当秋招来吧。 自我介绍聊项目,问消息通道如何处理高并发,为什么要分不同地域部署集群,把所有的集群部署在一个地方不好吗? 你们部门的系统设计瓶颈在哪里?你提到你们目前支持百万p cu在线,那如果说我现在要支持千万pcu,你该怎么做?(ps,这真的是我这个实习生该考虑的事情嘛😃😃) 单例模式,讲各种单例模式的写法,为什么要双重加锁(这个打的不
-
 抖音电商——前端
抖音电商——前端2024-5-17 一面(已过) - 自我介绍 - 项目问 - 进程/线程✔ - 跨域✔ - vue,react打包之后的html,有哪些东西✔ - js加载阻塞浏览器渲染,怎么优化defer/async✔ - 白屏问题,没仔细想过,也没有处理过这里没有答好 题目: - 盒子模型,标准盒子模型和怪异盒子模型✔ - 箭头函数的输出✔ - 判断传入的参数是否为一个空对象✔ - 不借助第三变量swap✔
-
 抖音电商二面
抖音电商二面全程拷打实习和项目,问的很细,刚实习做的项目一些细节都被问到了,但我已经忘了,问了项目的各个点的技术方案对比,然后结合项目问了一些高可用方面的问题和设计,压力很大,手撕是最长回文子串。反问环节问面试在哪个组,他说他是架构师,负责给各个组指导架构设计,头一次听说还有这种人,怪不得一直拷打设计
-
 韶音产品经理
韶音产品经理一面(HR面) 查户口为主,问了家庭情况,高考分数,工作意向城市,意向岗位等 结合简历上的几个项目问了一下哪一段对自己最有帮助 还有一些综合性的问题 后续:据说还要等反馈,周期挺长,如果能通过还有专业面,主管面,ceo评估,得到八月底 感觉已寄 #产品经理#
-
在MIDI音序器中控制音量的方法是什么?
问题内容: 有人可以告诉我如何在 不 使用声音库或合成器的 情况下 控制MIDI音序器的音量吗? 我想先使MIDI淡出,然后依次继续下一个MIDI 问题答案: 调用getSequence获得Sequence ; 调用getTracks获取曲目列表; 在每个轨道中,对于轨道中使用的每个频道,调用add在适当的时间位置添加多个事件: 也许从音轨中删除其他音量变化事件(这会干扰您的淡出效果); 等待一点
-
 iOS多媒体音频(下)-录音及其播放的实例
iOS多媒体音频(下)-录音及其播放的实例本文向大家介绍iOS多媒体音频(下)-录音及其播放的实例,包括了iOS多媒体音频(下)-录音及其播放的实例的使用技巧和注意事项,需要的朋友参考一下 上一篇中总结了iOS中音效和音频播放的最基本使用方法,其中音频的播放控制是使用AVFoundation.framework框架中的AVAudioPlayer播放器对象来实现的,而这里音频的录制则是使用了同样框架下的一个叫AVAudioRecorder的
-
如何使用selenium使Chrome WebDriver中的所有声音静音
问题内容: 我想编写一个脚本,在其中使用如下的selenium包: 现在,在获得所需的URL之后,我想使镶边声音静音。我该怎么办?像这样的东西: 其他任何Webdriver都有可能吗?像Firefox或…? 问题答案: 不确定是否可以在打开页面后(通常在任何页面上都可以这样做),但是可以通过设置切换器来在浏览器会话的整个过程中将所有声音静音: 或者,您可以直接将HTML5视频播放器静音: 您可能需
-
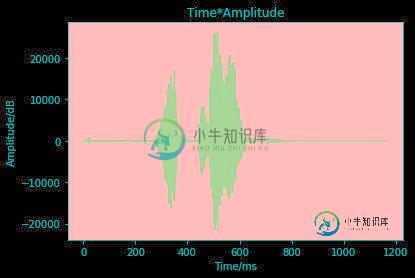 python实现播放音频和录音功能示例代码
python实现播放音频和录音功能示例代码本文向大家介绍python实现播放音频和录音功能示例代码,包括了python实现播放音频和录音功能示例代码的使用技巧和注意事项,需要的朋友参考一下 音频预处理 这一讲主要介绍些音频基本处理方式,为接下来的语音识别打基础。 三种播放音频的方式 使用 python 播放音频有以下几种方式: os.system() os.system(file) 调用系统应用来打开文件,file 可为图片或者音频文件。
-
输入另一个字符串后计算元音和辅音
JAVA: 编写一个类,其中构造函数接受一个String对象作为其参数。该类应该有一个方法返回字符串中元音的数量,另一个方法返回字符串中辅音的数量。(空格既不计元音也不计辅音,应该忽略。) 在执行以下步骤的程序中演示该类: 要求用户输入字符串 程序显示以下菜单: a、 计算字符串中元音的数量。 b、 数一数字符串中的辅音数 c、 数一数字符串中的元音和辅音 d、 输入另一个字符串 e、 退出程序
-
android实现汉字转拼音功能 带多音字识别
本文向大家介绍android实现汉字转拼音功能 带多音字识别,包括了android实现汉字转拼音功能 带多音字识别的使用技巧和注意事项,需要的朋友参考一下 android 汉字转拼音带多音字识别功能,供大家参考,具体内容如下 问题来源 在做地名按首字母排序的时候出现了这样一个bug。长沙会被翻译拼音成zhangsha,重庆会被翻译拼音成zhong qing。于是排序出了问题。 汉字转拼音库和多音字
-
如何在语音频道播放特定的音频文件?
我对javascript和discord.js很陌生,有人知道如何让机器人加入一个频道,播放一个文件然后离开吗? 以下是我尝试过的: 现在,它将发送消息加入语音通道,而不管我是否在其中,如果我在其中,它就不会加入语音通道并播放文件。任何帮助都很感激。
-
pygame混音器在窗口未激活时不播放声音
Pygame混音器在Pygame窗口未激活时不播放音频。是否有可能在这样的环境下编程,即使在后台也可以加载和播放新的声音文件?下面是我的pygame代码。
-
在c中使用alsa的dMix插件进行音频混音
我试图使用alsa同时播放两个wav文件。请注意,wav文件具有不同的采样率。这是可能的,音频流被混合并发送到音频芯片。(我正在嵌入式linux设备上开发。)但有一个流的播放速度比正常快几倍。所以我猜重新采样有问题。 我有一个默认设备,在 /etc/asound.conf中启用了dMix插件,并将采样率设置为44100Hz。但据我所知,ALSA在内部将所有流重新采样为48khz并混合它们,然后再次
-
重音字符(变音符)的具体Javascript正则表达式
我已经研究了堆栈溢出(替换字符...呃,JavaScript如何不遵循有关RegExp的Unicode标准等等),但还没有找到这个问题的具体答案: 目前,我正在讨论三种添加支持的方法中的一种,所有这些方法我都进行了测试和工作(至少在某种程度上,我不知道第二种方法的“范围”是什么)。它们在这里: 这将使姓/名与中支持的任何重音字符正确匹配。 这与任何东西都是匹配的,至少以的形式是这样的。好吧,我想.
-
PCM Web音频Api Javascript-我正在得到失真的声音
我正在通过电线接收一个交错的16位PCM样本。每个样本都有签名 我把它读作Int16bit数组,让我们调用这个all_data。因此每个数组条目都是一个16位的样本。 因为它是交错的,所以我将它提取成2个通道,R-L-R-L,最后得到2个(16位)数组,大小是ALL_DATA数组的一半。 之后,我查看每个示例,并将其规范化为Float32Array,因为这是web audio API所使用的。 v