《中国联通》专题
-
在合并语句中使用联接
问题内容: 问题 表格1: 表2: 表3: 给定键(A1或A2),我需要使用表2中的相应值更新表1中的DataColumn1和DataColumn2列。 因此,table1可以更新x个行,如上面的数据所示。如果我要更新A1,则01和02行都应更新 (因此,表01中的值对于键01和键02的datacolumn1分别为0.15和1.2(对于datacolumn2)) 到目前为止我尝试过的是: 问题:
-
在Django管理员中嵌套内联?
问题内容: 好吧,我的设计很简单。 是否有一种简单的方法允许用户在一页上全部创建更新? 我想要的是用户能够转到管理界面,添加新的更新,然后在编辑更新时添加一个或多个帖子,每个帖子都有一个或多个Media项目。另外,我希望用户能够在更新内重新排列帖子。 我当前的尝试在admin.py中包含以下内容: 这使用户可以添加一个新的Post项,选择相关的Update,向其添加Media项,然后单击Save-
-
js中hash和ico的关联分析
本文向大家介绍js中hash和ico的关联分析,包括了js中hash和ico的关联分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了js中hash和ico的一些关联。分享给大家供大家参考。具体如下: 近期测试提出一个bug,说某几个页面中的ico不显示,于是针对此问题排查原因。 首先,确保页面中的link已引入favicon.ico。经查看,发现是js中的location.hash导致了
-
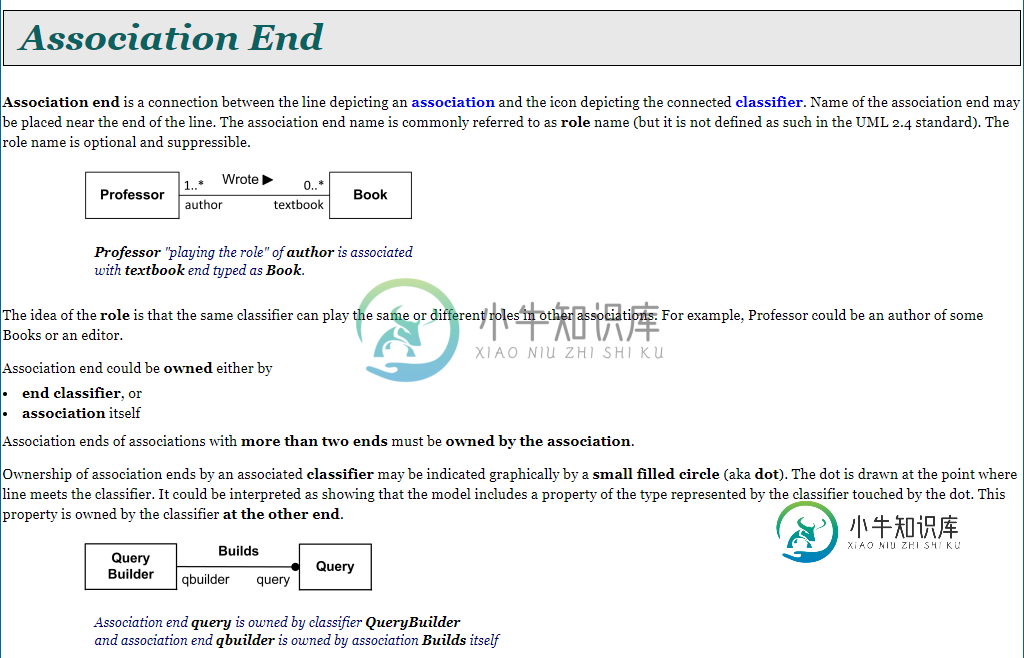 UML中的关联结束是什么?
UML中的关联结束是什么?我多次偶然发现这个词,但我不理解它的含义。当我读《结社终结》时,我倾向于思考结社的类别。每个联想都有两个联想终点,这是真的吗?还是我们说的“联想终点”是指类的角色?我已经搜索了这个术语的更详细的解释,但我找到的一切都在uml图上。组织: 你可以在我的截图底部看到,query和qbuilder,每个类的角色,都是“关联endpoint”。我的问题是,如果通过“关联端”,我们指向每个类的角色,还是指向
-
删除未在sqlalchemy中级联到表
问题内容: 我正在开发使用sqlalchemy 0.6的现有应用程序的扩展。 该应用程序具有以非声明方式创建的sqlalchemy表。我正在尝试在扩展程序中创建一个新表,该表的外键列指向应用程序数据库中主表的主键,并且以声明方式创建它。 这一切都很好,加载扩展程序后就创建了表,一点也没有抱怨。我的表将打印出来,并演示已经添加了新行。我想要并认为可能的(但不知道,因为我从未使用过sql或任何其他数据
-
在pyspark中按行串联字符串
问题内容: 我有一个pyspark数据框为 并且需要按行连接患者姓名,以便获得如下输出: 有人可以帮我有关在pyspark中创建此数据框吗? 提前致谢。 问题答案: 我能想到的最简单的方法是使用
-
在Python中联合多个嵌套JSON
我有多个json文件,其中包含需要合并的关系数据,每个文件都有一个带有commonkey的记录,这是所有文件中的公共键,在下面的示例中,a0,a1是公共键。值是多个键的嵌套字典,如Key1、key2等,如下所示,我需要合并多个json文件并获得如dboutput.json所示的输出,文件名在合并操作中充当索引。这样的问题是一个相关的问题,它合并了丢失的信息,但在我的情况下,我不希望任何更新替换现有
-
java中字符串常量的串联
问题内容: 在C ++中,创建多行字符串的最佳规范方法是创建相邻字符串,并让编译器在编译时将它们连接起来,如下所示: 在Java中,我唯一知道的方法是串联: 问题是,这是在运行时生成单个字符串,还是Java实际上也在编译时进行连接?出现此问题的原因是由于以下行为: 问题答案: String s3 = “a”; s3 += “bc”; 与: 因此,它创建了一个新实例。 您甚至可以尝试:
-
实体框架中的多重联接
问题内容: 我在TSQL中有以下查询 我在实体框架中有以下查询 当我尝试编译它时,我得到 错误3名称“ p”不在“等于”左侧的范围内。考虑在“等号”的任一侧交换表达式。 错误4名称“链接”不在“等于”右侧的范围内。考虑在“等号”的任一侧交换表达式。 问题答案: 错误究竟在说什么 应该 完整的代码
-
多个联接中的MySQL SUM函数
问题内容: 嗨,这是我的情况,我有那些桌子 所以我想总计费用和税款,然后按客户ID分组,这是我的查询 因此,如果我有1个客户费用,而我使用SUM函数时却有2个税额,那么它会计算两次费用,例如,如果要向我显示10 $,则向我显示20 $ 我知道如何通过子查询解决此问题,但是我想知道是否有任何选项可以获取没有子查询之类的正确值,例如我在上面可以使用的修改内容以解决该问题。 谢谢 ! 没有子查询的更新答
-
java中的关联和哈希映射
我有4节课。其中一个保存有关客户的信息。另一个是关于订单的。另外两个类扮演注册表角色,一个是客户注册表,另一个是订单注册表。 Orders registry有一个哈希映射,如下所示: 客户注册也是如此。 类orders具有int orderid。类客户具有int customerid。我通过两个注册中心添加了演示数据(假设一个客户的客户ID为100,一个订单的订单ID为500)。 我编写了一些简单
-
联接选择中的正确分页
我有SQL声明 关系为1-N:用户可能有许多文件。 这有效地选择了第二个10元素页面。 问题是这个查询限制/偏移了一个连接的表,但我想限制/偏移第一个(
-
如何在GORM中联接两个表
我有两张桌子, 我想为changelog实现一个搜索方法,该方法返回字段 如您所见,结果来自两个表的联接。 我发现https://gorm.io/docs/preload.html 但老实说,我不明白我该如何实现我所需要的。 我认为下面的内容可能会有所帮助 问题是,如何从GORM中提到的表格中获得我提到的内容?
-
 如何计算Tensorflow中的Spearman关联
如何计算Tensorflow中的Spearman关联我需要计算Pearson和Spearman的相关关系,并将其用作张量流的度量。 对于皮尔逊来说,这是微不足道的: 但对于斯皮尔曼,我是无知的! 从这个答案中: 但是这个返回。。。 我试过: 但运行此命令时,我出现以下错误: tensorflow.python.framework.errors_impl。InvalidArgumentError:输入必须至少有k列。有1个,需要32个 [{node
-
配置单元中的多表联接
我已经将Teradata表的数据迁移到配置单元中。 如果我使用joins,我需要连接五个表,在hive中可以吗?或者我应该将查询分成五个部分?对于这个问题应该采取什么明智的方法? 请建议