《百词斩》专题
-
 2022.8.22 百度 java实习一面凉经
2022.8.22 百度 java实习一面凉经2022.8.22 百度-服务体验发展中心_Java工程师实习生 一面凉经 1. 自我介绍 2. 实习里面碰到的技术难点并且是怎么解决的? a. es b. 为什用es替代mysql,他俩有啥不一样? c. 如果你没有搜索的需求,一开始为什么要用数据库呢? d. 数据量不大的话也是要走全表扫描的,跟你数据量大不大有什么关系? e. mysql里面的模糊搜索跟es里面的模糊搜索有什么不一样的? f.
-
 百度Android一、二面面经(社招)
百度Android一、二面面经(社招)百度面试给我最大的一个感受就是首先抛出的问题比较基础,然后就刨根问底,问一些比较细的东西,问到你的知识极限为止,所以问到打不出来的话也不要太慌张,一面基础比较重要,二面对算法和设计模式的考察比较多。 记得有点乱,这里就不区分一、二面的具体内容了。 项目提问(在整个项目中你做了些什么,团队是如何分工合作的,有遇到什么问题,这个部分是怎么实现的,这里讲了自定义view的实现和布局优化的内容,估计讲了有
-
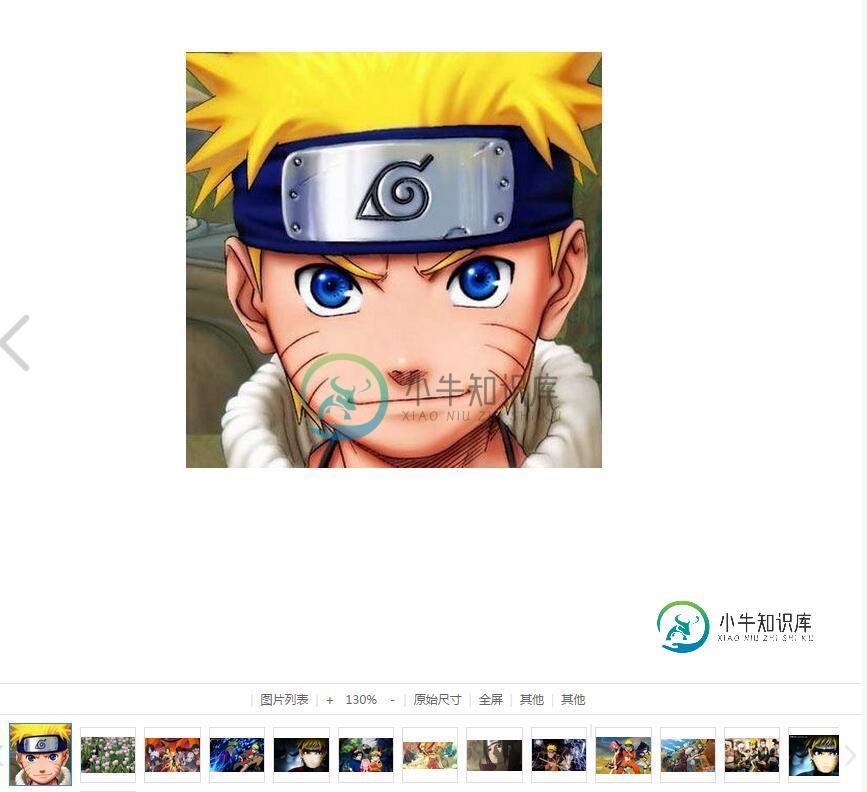 JavaScript仿百度图片浏览效果
JavaScript仿百度图片浏览效果本文向大家介绍JavaScript仿百度图片浏览效果,包括了JavaScript仿百度图片浏览效果的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了js图片浏览效果的具体代码,供大家参考,具体内容如下 在线地址:http://www.hui12.com/nbin/demo/imgskim/index.html https://nbin2008.github.io/demo/imgski
-
维基百科信息框的内容
问题内容: 我需要获取任何电影的信息框的内容。我知道电影的名字。一种方法是获取Wikipedia页面的完整内容,然后解析它,直到找到并获取信息框的内容。 使用某些API或解析器,是否还有其他方法可以实现? 我正在使用Python和pywikipediabot API。 我也熟悉wikitools API。因此,如果有人具有与wikitools API相关的解决方案,请不要使用pywikipedia
-
python抓取百度首页的方法
本文向大家介绍python抓取百度首页的方法,包括了python抓取百度首页的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python抓取百度首页的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的Python程序设计有所帮助。
-
使用numpy的加权百分位数
问题内容: 有没有办法使用numpy.percentile函数来计算加权百分位数?还是有人知道替代的python函数来计算加权百分位数? 谢谢! 问题答案: 不幸的是,numpy并没有为所有功能内置加权函数,但是,您始终可以将某些东西放在一起。
-
 Asp.NET调用百度翻译的方法
Asp.NET调用百度翻译的方法本文向大家介绍Asp.NET调用百度翻译的方法,包括了Asp.NET调用百度翻译的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Asp.NET调用百度翻译的方法。分享给大家供大家参考。具体分析如下: Asp.NET调用百度翻译,如下图所示: HTML代码如下: C#代码如下: 希望本文所述对大家的C#程序设计有所帮助。
-
 Android仿百度福袋红包界面
Android仿百度福袋红包界面本文向大家介绍Android仿百度福袋红包界面,包括了Android仿百度福袋红包界面的使用技巧和注意事项,需要的朋友参考一下 首先来看一下效果图: 1.编程思路 看看界面,不难发现,其就是一个放入九张图片的容器,绘制其实可以在其上面另创建一个透明View负责绘制线与圆圈。下面我们将介绍一下实现过程。 ㈠自定义ViewGroup 我们知道,自定义ViewGroup一定需要实现其onLayout()
-
Python将整数舍入到下一百
问题内容: 似乎应该已经被问过数百次了(双关很有趣=),但是我只能找到舍入浮点数的函数。如何围捕一个整数,例如:? 问题答案: 四舍五入通常是对浮点数进行的,这里您应该知道三个基本函数:(四舍五入到最接近的整数),(总是四舍五入)和(总是四舍五入)。 您询问整数并舍入到数百,但是只要您的数字小于2 53,我们仍然可以使用。要使用,我们只需先除以100,向上舍入,然后再乘以100: 先除以100,然
-
使用python从维基百科刮表?
我正在尝试从这个维基百科页面中获取表数据:https://en.wikipedia.org/wiki/2020_coronavirus_pandemic_in_Nepal我试过用熊猫警犬。Read Office HTML语法,但它对我试图擦除的表无效(证实了CavID-19在尼泊尔地区的病例)。 我试着用Beautifulsoup和pandas来搜集数据,但没有用
-
百里香中的标题和头衔
我是百里香的初学者。我从一个常见的布局页面开始: 碎片/布局。html 和一个内容页面: 页html 当我渲染页面时,标题总是来自模板,而不是页面。在Thymeleaf中,是否有可能具有共同的元、脚本和样式(在HEAD标签中),但具有每页标题?
-
SQL Server 2008 R2的百分比汇总
问题内容: 我正在使用SQL Server 2008 R2。我需要计算每个组的百分位数值,例如: 例如,给定此DDL(fiddle)- -–我大致希望(在普通百分位数方法的变化范围内)以下内容: 实际的输入集大约有200万行,每个实际的组都有几十到几百(甚至更多)行。 我已经在SO和其他站点上探索了解决方案,但似乎我检查的十几个页面中的解决方案仅适用于计算整个行集而不是行集的每个组/分区的百分位。
-
 js仿百度音乐全选操作
js仿百度音乐全选操作本文向大家介绍js仿百度音乐全选操作,包括了js仿百度音乐全选操作的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了js全选操作的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
熊猫占groupby总数的百分比
这显然很简单,但作为一个新手,我被卡住了。 我有一个CSV文件,其中包含3列:州、办公室ID和该办公室的销售额。 我想计算给定州每个办公室的销售额百分比(每个州所有百分比的总和为100%)。 这返回: 我似乎不知道如何“达到”级别,以总计整个的来计算分数。
-
大量获取维基百科摘录
有办法从维基百科获得所有标题/摘录对吗?到那一刻,我发现了两种方法: 下载摘录转储,但它包含不完整/无效的摘录,我想是作为文章的第一行。 使用MediaWiki API请求摘录,但它非常慢,因为每个请求只能获得单个摘录(批量查询不适用于摘录): /w/api.php?action=query 我想获得摘录,因为它们是由MediaWiki API生成的,而不需要负担维基百科服务器。可能吗? 顺便说一