《百词斩》专题
-
盘古分词
盘古分词是一个基于 .net framework 的中英文分词组件。主要功能 中文未登录词识别 盘古分词可以对一些不在字典中的未登录词自动识别 词频优先 盘古分词可以根据词频来解决分词的歧义问题 多元分词 盘古分词提供多重输出解决分词粒度和分词精度权衡的问题 中文人名识别 输入: “张三说的确实在理” 分词结果:张三/说/的/确实/在理/ 输入 “李三买了一张三角桌子” 分词结果:李三/买/了/一
-
划词翻译
划词翻译是一款安装在桌面端浏览器的划词翻译扩展程序,可在 Chrome、Firefox 和 Microsoft Egde 中使用,支持谷歌、DeepL、百度、搜狗等 9 个国内外主流翻译源。 当用户在网页中划选一段文本之后,划词翻译会显示这段文本在多个翻译服务中的翻译结果,用户可以很轻松地对比、复制翻译结果。 划词翻译支持 9 个国内外热门的翻译服务,包括但不限于谷歌、DeepL、百度、有道等,且
-
词形化与词干的区别是什么?
问题内容: 什么时候使用每个? 另外… NLTK词素化是否取决于词性?如果不是,它会更准确吗? 问题答案: 简短而密集:http : //nlp.stanford.edu/IR-book/html/htmledition/stemming- and-lemmatization-1.html 词干和词根化的目的都是将单词的屈折形式和有时与派生相关的形式减少为通用的基本形式。 但是,这两个词的风格不同
-
将一个大词标记为词的组合
假设我有超级碗是弹性搜索中文档属性的值。术语查询超级碗如何与超级碗匹配? 我读过字母标记器和单词定界符,但它们似乎都不能解决我的问题。基本上,我希望能够将一个大词的组合转换为有意义的词的组合。 https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-word-delimiter-tokenfilter.htm
-
具有非单词字符的单词边界
使用正则表达式匹配表达式 为什么这两个示例匹配如下(突出显示): c# < code>a #b #c #d 具体来说,为什么第一个字符串不匹配包含最后一个#之前的所有内容? 由于单词边界(\b)是零宽度匹配,可以在单词字符(\w)和非单词字符(\ w)之间匹配,或者在单词字符和字符串的开始或结束之间匹配,我不确定以非单词字符结束表达式会如何影响匹配。
-
词嵌入:编码形式的词汇语义
译者:巩子惠 词嵌入是一种由真实数字组成的稠密向量,每个向量都代表了单词表里的一个单词。 在自然语言处理中,总会遇到这样的情况:特征全是单词!但是,如何在电脑上表述一个单词呢?你在电脑上存储的单词的ascii码,但是它仅仅代表单词怎么拼写,没有说明单词的内在含义(你也许能够从词缀中了解它的词性,或者从大小写中得到一些属性,但仅此而已)。 更重要的是,你能把这些ascii码字符组合成什么含义?当代表
-
Python、Take dictionary和生成列表(单词>1、最常用单词、最长单词)
所以我做了一个函数 因此,它所做的是获取一个字符串,将其拆分,并生成一个字典,其中键是单词,值是它出现的次数。 好的,我现在要做的是,做一个函数,它接受这个函数的输出,并产生一个如下格式的列表- ((超过1个字母的单词列表),(最常用单词列表),(最长单词列表)) 另外,例如,假设两个单词出现了3次,并且两个单词都有6个字母长,那么这两个单词都应该包含在(最频繁的)和(最长的)列表中。 因此,到目
-
如何使用分类词词典从文本片段中提取特定词?
我想从数据帧中的文本中提取特定的单词。这些单词我已经输入到字典的列表中,它们属于某些类别(键)。由此,我想创建与存储单词的类别相对应的列。和往常一样,最好用例子来说明: 我有一个数据框: 它创建表: 还有一本我想从中提取的分类词词典。这些单词都是没有符号的自然语言单词,可以包括短语,例如本例中的“alloy wheels”(这不一定是字典,我只是觉得这是最好的方法): 根据这个,我想创建一个如下所
-
php获取从百度、谷歌等搜索引擎进入网站关键词的方法
本文向大家介绍php获取从百度、谷歌等搜索引擎进入网站关键词的方法,包括了php获取从百度、谷歌等搜索引擎进入网站关键词的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php获取从百度、谷歌等搜索引擎进入网站关键词的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的php程序设计有所帮助。
-
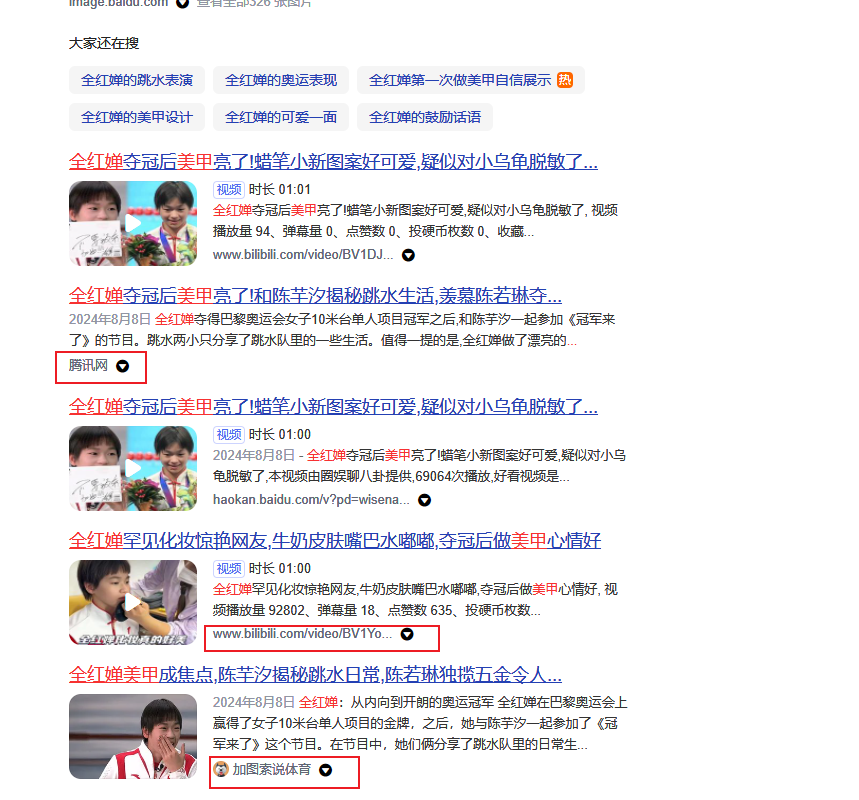 javascript - 百度搜索,关键词是提取页面的哪个位置的数据来的?
javascript - 百度搜索,关键词是提取页面的哪个位置的数据来的?百度搜索,关键词是提取页面的哪个位置的数据来的?我现在需要修改红色方框显示的内容,需要修改网页哪里的数据?
-
Lucene搜索匹配词组中的任何单词
问题内容: 我想搜索包含许多单词的字符串,并检索与其中任何一个匹配的文档。我的索引方法如下: 这是我的搜索方法。我不想寻找特定的词组,但是其中的任何单词。用于搜索的分析器与用于索引的分析器相同。 我是Lucene的新手。有人可以帮我吗? 问题答案: 使用会精确地尝试将短语“单词列表”与短语坡度0匹配。 如果要匹配单词列表中的 任何 术语,可以使用: 或者,您也可以使用,以便您可以要求查询词的数量的
-
令牌生成器,停止词删除,Java词干
问题内容: 我正在寻找一个类或方法,该类或方法需要一个长字符串(包含数百个单词),并进行标记化,删除停用词和词干,以用于IR系统。 例如: “大肥猫,对袋鼠说’我认识的最有趣的家伙’。” 分词器将删除标点符号并返回一个单词 停用词删除器会删除“ the”,“ to”等词 词干会减少每个单词的“词根”,例如“最有趣”会变得很有趣 提前谢谢了。 问题答案: AFAIK Lucene可以做您想要的。用和
-
使用Lucene 4.0为单词添加词干并创建不带停止词的索引
我有以下问题:有几个文本文档需要解析和创建索引,但没有停止词和词干。我可以手动操作,但我从一位同事那里听说Lucene可以自动操作。我在网上搜索了很多我尝试过的例子,但是每个例子都使用了不同版本的lucene和不同的方法,没有一个例子是完整的。在这个过程结束时,我需要计算集合中每个术语的tf/idf。 更新:我现在已经用一个文档创建了一个索引。doc没有停止词,并且有词干。如何使用lucenc计算
-
如何在python nltk和wordnet中获取单词/同义词集的所有下位词?
问题内容: 我现在有一个wordnet中所有名词的列表,我只想保留车辆中的单词,其余的删除。我该怎么做?下面是我要制作的伪代码,但我不知道如何使它工作 问题答案: 这会给你从每一个同义词集这是一个所有独特的词下义词的名词“车辆”(第一感觉)的。
-
C#到Java-词典?
问题内容: 用Java在字典中可以声明已经声明的项目吗?就像下面的C#代码一样: 我该怎么办?我要使用哪种类型?我读过字典已过时。 问题答案: 这将做您想要的: 该语句创建HashMap的匿名子类,与父类的唯一区别是在实例创建过程中添加了4个条目。在Java世界中,这是一个相当普遍的习惯用法(尽管有些人有争议,因为它创建了一个新的类定义)。 由于这一争议,从Java 9开始,有一个新的惯用法来方便