《大数据研发实习》专题
-
 科大讯飞java实习
科大讯飞java实习自我介绍 怎么学习的,我说博客和文档,让我详细说一下 Java 8 新特性,用stream做过滤和排序实现,底层原理是什么 线程池介绍,ForkJoinPool介绍,线程池状态,核心线程数,最大线程数 es(没学过) JVM(没学过。。。) nginx代理是计网五层模型中的那一层,防火墙知不知道 linux命令,怎么查找出当前运行的所有java进程 redis数据结构 搭建redis集群的几种方式
-
谷歌数据流和发布订阅 - 无法实现一次交付
我正在尝试使用Google Dataflow和Apache Beam SDK 2.6.0的PubSub实现一次性交付。 用例非常简单: 'Generator'数据流作业将1M消息发送到PubSub主题。 “存档”数据流作业从PubSub订阅中读取消息,并保存到Google云存储中。 我在 Pubsub.IO.Write(“生成器”作业)和 PubsubIO.Read(“存档”作业)中都添加了“带
-
如何使用Objective-C将JSON数据发布到PHP数据库?
问题内容: 我在将数据发送到在线数据库时遇到问题。当我检查数据库时,似乎什么都没有发布。我对收到的响应执行了NSLog,它为空。 这是.php: 但是,如果我将$ response硬编码为某个字符串值,而NSLog接收到的响应,它将接收适当的字符串值。 这是我的代码: 是不是无法插入IMEI(这就是为什么它不发布)或其他问题的事实? 谢谢你的协助。 问题答案: 一些观察: 您应该使用interfa
-
在React.js Web应用程序中将数据发送到数据库
问题内容: 我正在创建一个Web应用程序,并且很好奇如何在其中将数据发送到MySQL数据库。我有一个在用户按下按钮时调用的函数,我希望该函数以某种方式将数据发送到MySQL服务器。有谁知道如何解决这个问题?我尝试了npm MySQL模块,但似乎连接不正确,因为它是客户端。还有其他方法吗?我需要一个主意才能开始。 问候 问题答案: 您将需要一个服务器来处理来自React应用程序的请求并相应地更新数据
-
如何在php中用POST发送数据,用json接收数据
我想连接到API,但我需要用post发送数据,但用JSON接收。 file_get_contents(url_here):打开流失败
-
如何使用Objective-C将JSON数据发送到PHP数据库?
下面是我的代码: 是不可能插入IMEI的事实,这就是为什么它不张贴,还是其他一些问题? 谢谢你的协助。
-
为什么traceroute发送UDP数据包而不是ICMP数据包?
根据Stevens(图示为TCP/IP),traceroute程序用增量TTL(1、2、3等)向目的主机发送UDP数据包,以从ICMP TTL过期消息中获取中间跳信息。 “到达目的地”条件是ICMP端口无法到达的消息,因为traceroute寻址的随机端口数量很高(也就是说,不太可能有人在那里监听) 所以我的问题是:是否有技术原因(缺点、RFCs等)使用UDP数据包而不使用例如ICMP回送请求消息
-
Firebase实时数据库验证数增量
我使用Firebase实时数据库作为后端。我希望每个请求最多增加1个。例如: 这不管用。 在前端,我发送“数据1”。我应该如何创建“.validate”规则?
-
计算表中BLOB列的总数据大小
问题内容: 我的表中的一列中包含大量BLOB数据。我正在编写一个实用程序以将数据转储到文件系统。但是在转储之前,我需要检查磁盘上是否有必要的空间来导出整个表中的所有Blob字段。 请提出一种有效的方法来获取表中所有Blob字段的大小。 问题答案: 您可以使用MySQL函数。有关更多详细信息,请参见此处。
-
Python=-使用pandas的“大数据”工作流程
问题内容: 在学习pandas的过程中,我试图迷惑了这个问题很多月。我在日常工作中使用SAS,这非常有用,因为它提供了核心支持。但是,由于许多其他原因,SAS作为一个软件还是很糟糕的。 有一天,我希望用python和pandas取代我对SAS的使用,但是我目前缺少大型数据集的核心工作流程。我并不是说需要分布式网络的“大数据”,而是文件太大而无法容纳在内存中,但文件又足够小而无法容纳在硬盘上。 我的
-
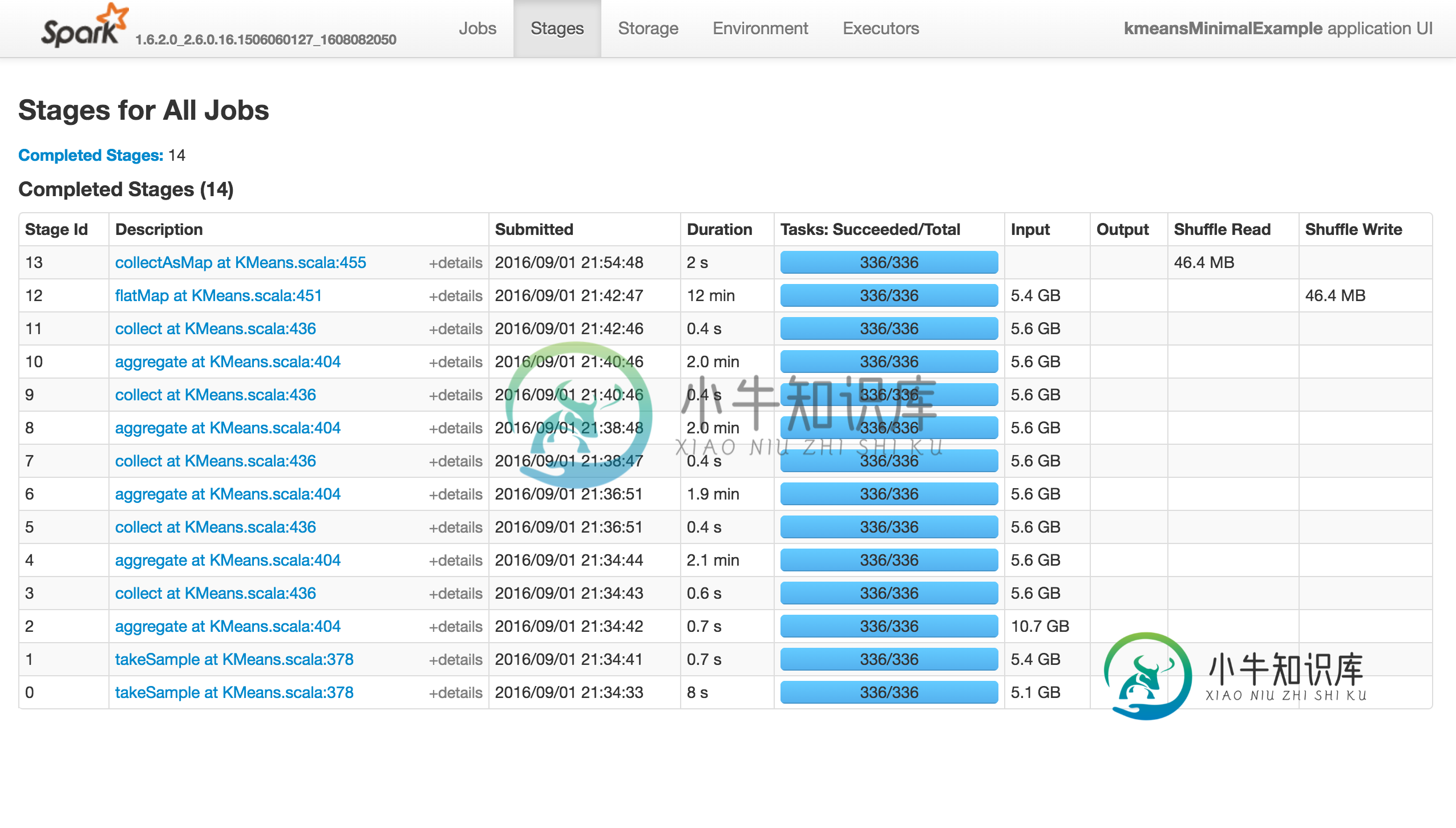 Spark的KMeans是否无法处理大数据?
Spark的KMeans是否无法处理大数据?问题内容: KMeans有几个用于训练的参数,初始化模式默认为kmeans ||。问题在于它快速前进(不到10分钟)到前13个阶段,但随后 完全挂起 ,而不会产生错误! *重现问题的 *最小示例 (如果我使用1000点或随机初始化,它将成功): 如下所示,该作业不执行任何操作(该操作不会成功,失败或没有进展。)。“执行器”选项卡中没有活动/失败的任务。Stdout和Stderr Logs没有特别有
-
如何获取MySQL数据库表的大小?
问题内容: 我可以运行此查询来获取MySQL数据库中所有表的大小: 我希望对了解结果有所帮助。我正在寻找尺寸最大的桌子。 我应该看哪一列? 问题答案: 您可以使用此查询显示表的大小(尽管您需要先替换变量): 或此查询以列出每个数据库中每个表的大小,从大到大:
-
如何在大型数据库中使用typeahead.js
问题内容: 我有10,000个地址和5,000人的大型数据库。 我想让用户在数据库中搜索地址或用户。在输入文本时,我想使用Twitter的提前提示功能来建议结果。 在此处查看NBA示例:http : //twitter.github.io/typeahead.js/examples。 我了解从速度和负载的角度来看,预取15,000个项目并不是最佳选择。尝试实现此目标的更好方法是什么? 问题答案:
-
大话C语言变量和数据类型
主要内容:变量(Variable),数据类型(Data Type),连续定义多个变量,数据的长度(Length),最后的总结在《 数据在内存中的存储》一节中讲到: 计算机要处理的数据(诸如数字、文字、符号、图形、音频、视频等)是以二进制的形式存放在内存中的; 我们将8个比特(Bit)称为一个字节(Byte),并将字节作为最小的可操作单元。 我们不妨先从最简单的整数说起,看看它是如何放到内存中去的。 变量(Variable) 现实生活中我们会找一个小箱子来存放物品,一来显得不那么凌乱,二来方便以后
-
数据流大侧输入中的Apache波束
这与这个问题最为相似。 我正在Dataflow 2.x中创建一个管道,它从Pubsub队列获取流式输入。进入的每一条消息都需要通过来自Google BigQuery的一个非常大的数据集进行流式传输,并且在写入数据库之前附加了所有相关的值(基于一个键)。 问题是来自BigQuery的映射数据集非常大--任何将其用作侧输入的尝试都失败了,数据流运行程序会抛出错误“java.lang.IllegalAr