《数据产品》专题
-
使用数据库元数据
SQLAlchemy 1.4 / 2.0 Tutorial 此页是 SQLAlchemy 1.4/2.0教程 . 上一页: 处理事务和DBAPI |下一步: |next| 使用数据库元数据 随着引擎和SQL执行的停止,我们准备开始一些炼金术。SQLAlchemy Core和ORM的核心元素是SQL表达式语言,它允许流畅、可组合地构造SQL查询。这些查询的基础是表示数据库概念(如表和列)的Pytho
-
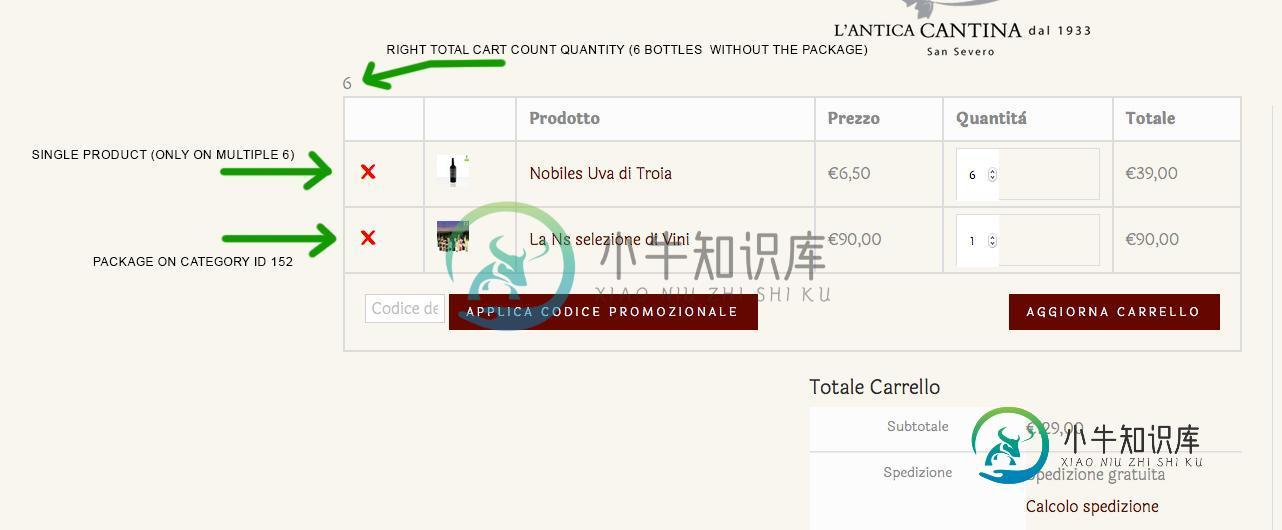 从总计数中删除类别的产品
从总计数中删除类别的产品我用wordpress 4.2.2和woocommerce 2.3.11建立了销售葡萄酒的电子商务。我创建了一个自定义函数,用于在6的倍数上仅使用瓶子结束订单。在此之前,我没有任何问题,但我有两个类别,包装为6瓶,所以我想避免这两个类别将计入数量合计项目购物车。我不是php专家,所以我尝试创建一个函数来检查每个项目是否在类别内,如果属于一个包类别,则减去一个项目。只有当这两个类别中有一个项目时,这
-
WooCommerce 可变产品变种的数量限制
WooCommerce可变产品的变种是什么?一件颜色是红色尺码为XL的衣服就是一个变种。可变产品最多能有多少变种?没有限制,但的确存在一个数量,会影响变种下拉列表的行为。这个数量是30个。 变种下拉列表的两种行为 行为1:动态展示商品属性。 这是我们平时看到的模式,从程序角度讲,就是把variations的所有可能直接以json格式放到add to cart表单上,用js读取并动态渲染。 用人话讲
-
 龙湖数科产品 一面+二面(已挂)
龙湖数科产品 一面+二面(已挂)(一面)15min 1.自我介绍 2. 介绍地产实习的主要内容,希望体现个人特质 3. 介绍第二段产品实习的内容 4. 对个人短期的职业规划,职业选择的意向 5. 对龙湖数科有什么理解 6. 各个产品线的理解 反问 1.目前落地的产品和商业化的模式(有部分产品成熟,预计独立面向市场推广) 2.培养方案(先去做产品运营维护,非强制轮岗,龙湖整体的管培生体系) 3. 我面试的岗位(非定向,各部门一起培
-
 如何检查Spark数据帧的分区数而不产生?放射性散布装置
如何检查Spark数据帧的分区数而不产生?放射性散布装置关于如何获得n<code>RDD</code>和/或<code>DataFrame</code>的分区数,有很多问题:答案总是: 或者 不幸的是,这在上是一项代价高昂的操作,因为 需要从转换为。这是运行所需时间的顺序 我正在编写逻辑,根据当前分区数是否在可接受值范围内,或者是否低于或高于可接受值,可以选择<code>重新分区</code>或<code>合并</code>为<code>DataFra
-
如何在Spring Applications中处理生产数据库上的架构升级
问题内容: 使用Spring框架和hibernate模式在生产数据库上进行升级过程的最佳实践是什么? 问题答案: 您也可以在Flyway上花很多时间:http://flywaydb.org 比Liquibase简单得多。
-
Mysql-从多个表中选择而不产生重复数据[已关闭]
我有三个表格,我想从表格中选择,而不产生重复。 表格如下: 客户 命令 userID列是引用John Doe的外键,因此John订购了3项。 客户校正 userID列是引用johndoe的外键,因此John留下了5条评论。 我将如何从3个表中进行选择,从中可以得到如下所示的返回结果? 我尝试过加入这些表,但是由于John留下了5个评论,并且只订购了3次,所以id、name、lastName和订单列
-
将数据帧保存到本地文件系统会产生空结果
我们正在上运行spark 2.3.0。以下“”不是空的,大小适中: 以下代码可以很好地将写入: 然而,使用相同的代码写入本地< code>parquet或< code>csv文件最终会得到空结果: 我们可以看到它失败的原因: 因此,没有正在写入镶木地板文件。 我已经对< code>csv和< code>parquet以及两个不同的< code>EMR服务器尝试了大约二十次:在所有情况下都表现出相同
-
打印类型数据的ArrayList内容会产生错误的输出{Java}
我有一个数据类型的ArrayList(它存储一个名为name的字符串和一个名为age的整数)。打印Arraylist的内容时,它会打印正确的年龄,但与我上次添加的元素的名称相同。下面是PrintCollection方法 } 这是数据类
-
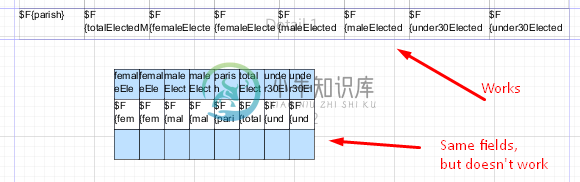 将数据从主数据集传递到表数据集
将数据从主数据集传递到表数据集我正在使用一个表在Jaspersoft Studio 5.6.1中创建简单的报告。 通过 JRBeanCollectionDataSource 从 Java 向此报告发送数据。 在报告中,我已经可以获取此数据 vie 字段:报告- 现在我可以显示输入的数据了。 但如果我想在表中执行,我需要创建数据集(为什么?)并选择“使用用于填充主报告的相同连接”。将相同的字段添加到新数据集没有帮助,也没有为数据
-
1000 * 60 * 60 * 24 * 30产生负数
问题内容: 我试图通过乘以毫秒来计算30天,但是结果持续出现,结果是days_30的值是负数,我不确定为什么。 任何建议,不胜感激! 代码片段: days_30值导致:-1702967296 聚苯乙烯 结果较小(但仍为负数)。-1.702967296E9 问题答案: 您正在相乘,并且发生溢出,因为最大整数为。只有在乘法之后,它才会转换为。将第一个数字转换为。 或使用文字: 从一开始,这将迫使数学运
-
C#产生一个随机整数
本文向大家介绍C#产生一个随机整数,包括了C#产生一个随机整数的使用技巧和注意事项,需要的朋友参考一下 示例 本示例生成0到2147483647之间的随机值。
-
 杭州产链数字-Java面经
杭州产链数字-Java面经boss上投的,三天后约面 1.自我结束 2.结合项目深挖 3.jwt的各部分的作用 4.redis怎么确认缓存的是热点数据 5.介绍redis的Redission及项目中如何使用的 5.问了下redis其他的锁 6.redis过期策略、淘汰策略 7.redis持久化 项目问完就开始问了java八股了 jvm组成 双亲委派机制,为什么要有双亲委派机制(后者没答出来,面试官很耐心解释了) 介绍下GC
-
Android 将数据插入数据库
本文向大家介绍Android 将数据插入数据库,包括了Android 将数据插入数据库的使用技巧和注意事项,需要的朋友参考一下 示例
-
 从Firebase数据库读取数据
从Firebase数据库读取数据我试图从Firebase数据库中读取数据,我已经到处阅读和查找,但我已经走到了死胡同。 这就是我所做的一切。 依赖项: 实现'com.google.firebase: Firebase存储: 9.2.1' 实现'com。谷歌。firebase:firebase数据库:9.2。1' 实现'com。谷歌。firebase:firebase授权:9.2。1' 实现'com。谷歌。火基:火基核心:9.2。