《大数据求职》专题
-
 美团大数据开发一面
美团大数据开发一面场景题: 1、有一个sql突然执行很慢有什么原因 2、从一个很大的日志表中10T,随机取出一些数据 3、有两个大表join,我说了分桶排序,他说那大key不还是分到一个桶里面,没解决问题,我说讲大key使用mapjoin或加随机数,那key如果未知怎么办 4、mysql中MyIsam相对于innodb更适合那些场景 5、hashmap为什么不直接用红黑树 问一个问题,回答完就会深挖,给我问麻了 #
-
 顺丰 大数据开发 一面
顺丰 大数据开发 一面9.11 一面(30min) 纯八股: 介绍下hadoop(hdfs、mapreduce、yarn) 介绍下hbase 介绍下flink flink checkpoint、connect和union的区别、flink如何处理数据倾斜 介绍下kafka kafka如果有台机器挂掉会发生什么 链表反转 面试官全程表情和语气冷淡,体验不是很好..当然答得感觉也很一般
-
 美团大数据开发面经
美团大数据开发面经个人情况:本双一流硕211非科班,一段搞深度学习的实习。项目自己做的。全程面试被追问麻了面试官有问题必追问 自我介绍 项目深挖(20min) 实习工作介绍(5min) 数据倾斜有哪几种解决方法 Group by 倾斜,join倾斜,null值倾斜 分别说说这些倾斜怎么解决:全说上来了,面试官问:还有呢?。。。开启负载均衡,对小文件进行合并,对数据类型进行检查,还有呢?我就记得这些了 Hdfs小文件
-
 美团大数据开发面经
美团大数据开发面经部门:优选事业部-美团买菜 timeline: 8.24 一面 8.28二面 8.31 hr面 9.7 oc 一面: 项目介绍 什么是指标体系 指标体系包含元素 指标分类 数仓分层、分层好处 数仓分层和指标分类之间有什么关系 什么是总线矩阵 什么样的数仓是一个比较好的数仓 什么方法可以落实上面说的数仓 缓慢变化维;除了拉链表还有哪些方式 什么情况下可以使用map join 怎么解决数据倾斜问题 J
-
 百度 大数据研发实习
百度 大数据研发实习一面 实习深挖 对于高耗时任务的代码优化思路 如何发现不必要的扫表 sparksql和hivesql有什么区别 sparksql和hive on spark性能有差异吗,差异在哪 hdfs架构 datanode心跳机制 datanode挂了之后会怎么样,容错机制是怎么样 机架感知 有限内存下的一亿数据怎么排序 了解哪些shell命令 有a,b两个文件,存的都是id,写shell找出a中有但b中没有
-
 开放传神大数据开发
开放传神大数据开发1.自我介绍 2.rdd变dataframe,再变dataset中间发生的过程 3.项目拷打 4.说说文本处理方法 5.说说数据采集经历 6.颜色分类,操这题还没写对,麻了
-
 金风科技大数据一面
金风科技大数据一面自我介绍 数据倾斜问题 spark的shuffle相对于mr的shuffle有什么区别 spark的stage怎么划分的 yarn中都有什么,作用是什么 hdfs读写流程 rpc和http分别是什么,有什么区别 项目中都有什么数据 数仓的分层,每层都做了什么事 反问 金风科技二面总经理面 自我介绍 总经理问题: 1.本科和研究生都是通信,为什么选择大数据 2.怎么在完成学业同时学习大数据的 2.对
-
 平安科技 大数据开发
平安科技 大数据开发2023/10/10 平安科技 大数据开发(37min) (1)自我介绍 (2)对于平安科技的数据开发岗的理解和认为它是做什么的?和自己的契合度是怎么样的? (3)数据库学习到哪些东西,学了多久,什么时候学的,有实践过吗? (4)sql分哪几类,违反主键约束会出现什么问题,索引什么情况下回失效,有自己去安装过吗?(之前没准备数据库的内容,答得很差,后边的面试才好好看了数据库的东西) (5)使用sq
-
 某厂外包-大数据开发
某厂外包-大数据开发1.自我介绍 2.描述一张表的设计流程 3.针对简历提问,问的不算难 4.kafka的用法及途径 5.redis的几种类型(我有写,但是忘了), 6.有没有bi可视化经验。 ----------------- 是的,没有看错,简历上写的就会可能提问,并不会针对你。
-
 海康 大数据算法 二面
海康 大数据算法 二面【30min】自己提到推荐领域和数据挖掘领域,直接就问了两个领域比较熟悉的算法有什么,大概介绍一些 不会的: 1. XGB shrinkage 2. FM 算法为什么时间不高 3. 如何将用户之间和物品之间的特征加入协同过滤中(随便说了,特征拼接) 比较明确的问题: 1. 随机森林,提升树的区别 2. 随机森林如何构建?特征采样的好处 场景题 1. 给出手机的BOM结构图,对于预测手机销量和原材料
-
 字节大数据开发一面
字节大数据开发一面1.自我介绍 2.实习介绍 3.实习工作内容下游使用方主要有那些? 4.AI团队数据支持 他们使用这个数据做的什么 5.除了对表的支持之外,是否在计算层面做过一些优化 6.boradcast join和sortmergeJoin的区别和 使用场景的不同 然后面试官开始说,我觉得概念你应该都会,我就不问你了,所以我后面会从场景的角度去考验你的技术理解,本人听到这里心凉了半截,因为两段实习全是离线,这
-
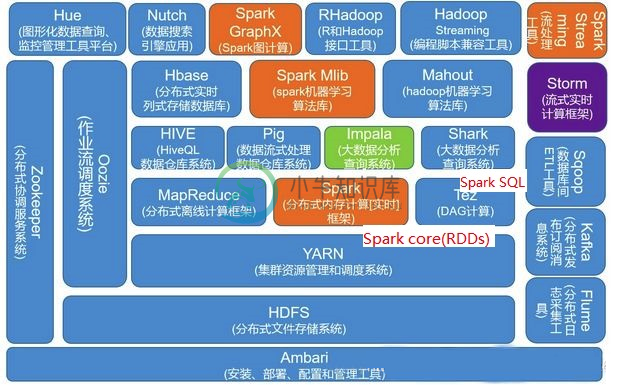 大数据生态圈的理解
大数据生态圈的理解HDFS是整个大数据架构的底层,它提供了一个文件系统 Spark(Spark core(RDD)) 和 MapReduce 是一个层级,是一种操作计算框架,MapReduce相当于一个别人写好的 java程序,它并不需要在服务器上启动相应的服务,甚至可以在本地run Hive => MapReduce Hive 操作MapReduce(底层是 MapReduce) Spark SQL=> Spar
-
 京东健康大数据算法
京东健康大数据算法已挂 一面 没有自我介绍,直接开问; 八股考的比较多,论文和实习经历都没怎么问 lgbm和xgboost的区别 RNN, GRU, LSTM之间的差别 为什么RNN容易梯度爆炸? 进程的通信方式 介绍下进程和线程 进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位 死锁的四个必要条件 互斥条件:一个资源每次只能被一个进程使用; 请求与保持条件: 一个进程因请求资源而阻塞时,对
-
 京东-大数据开发凉经
京东-大数据开发凉经110分钟,全程无项目和算法,全是八股深挖,被拷打惨了 1、谈一谈你对java面向对象的理解,什么时候用接口,什么时候用抽象类,从本质上讲一下区别? 2、都有了解过哪些设计模式?创建对象的设计模式有哪些?工厂模式和建造者模式分别在什么场景下使用,举一个具体的例子 3、java的hashmap在1.8之前链表中采用的头插法的方式,为什么1.8之后改成尾插法?头插法的方式可能会极限情况连成一个环,举一
-
 中新赛克-大数据-复试
中新赛克-大数据-复试2024/9/18 30min - 自我介绍 - 开源项目介绍 - SSO原理 - 这个SSO系统存了什么表?根据RBAC说 - 介绍下其他几个项目 - 这些项目是根据一些开源项目改的吧? - Bitmap如何用的? - 用数据库可以存签到数据吗? - 为什么Bitmap节约空间 - 外卖项目是有手机端吗? - 你是保研的吗?可以从一个专业保到另一个专业? - 研究生论文写的是什么? - 未来职业