《大数据求职》专题
-
 兴金数金,大数据实习面经
兴金数金,大数据实习面经一,上来就问了项目里日志的处理量,50w 100M左右 二,问项目里如何解决Hbase的热点问题,面试官没听明白,后面就直接问热点问题如何解决的 答的就举年份例子,加盐,预分区 三,Kafka里是如何leader和follow是如何实现同步的 具体怎么实现同步我确实不知道,我就答的是offset在follow和leader挂了后如何在实现同步的,面试官说我似乎说了又没说明白,后面查了一下,下
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
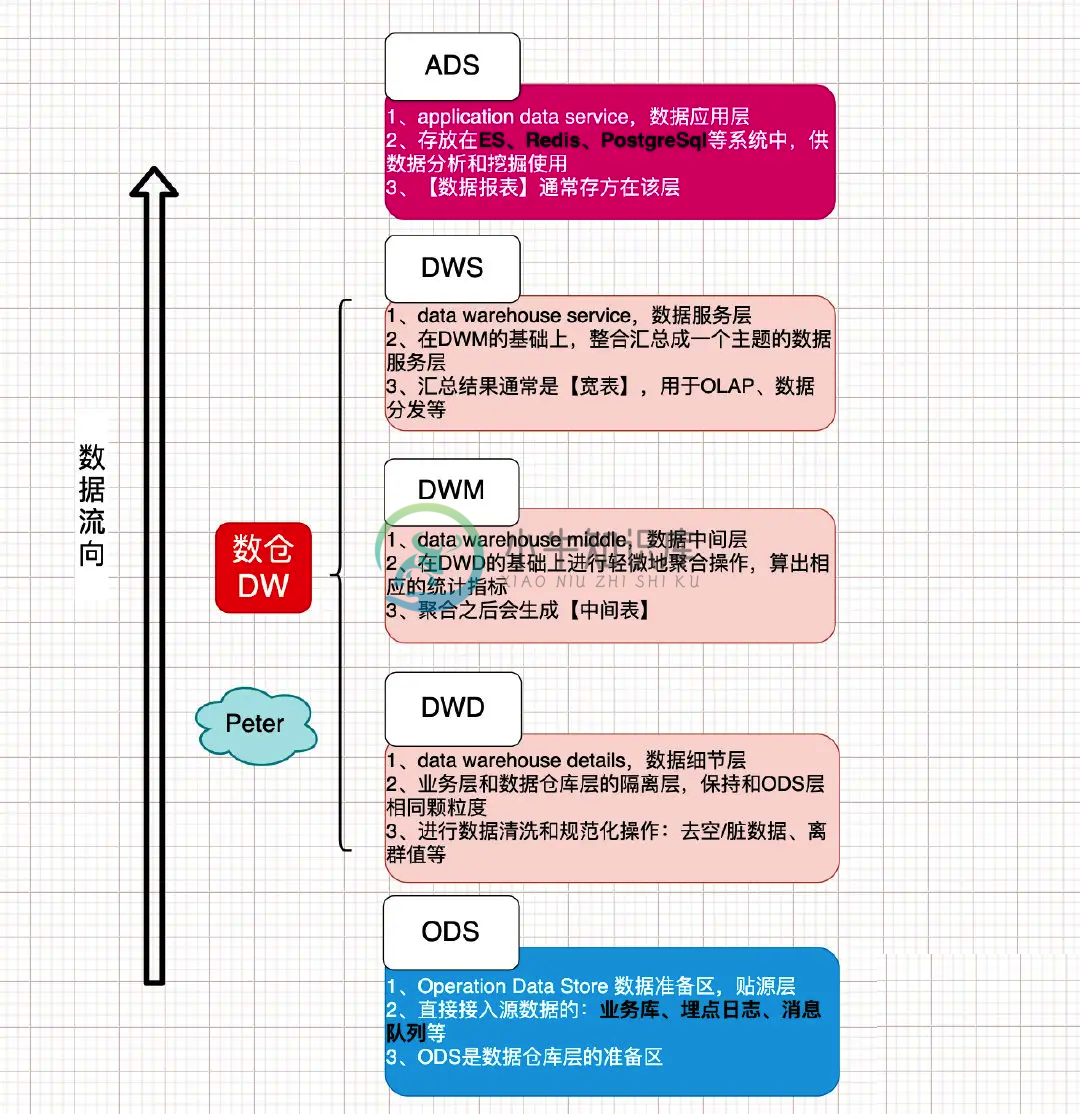 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
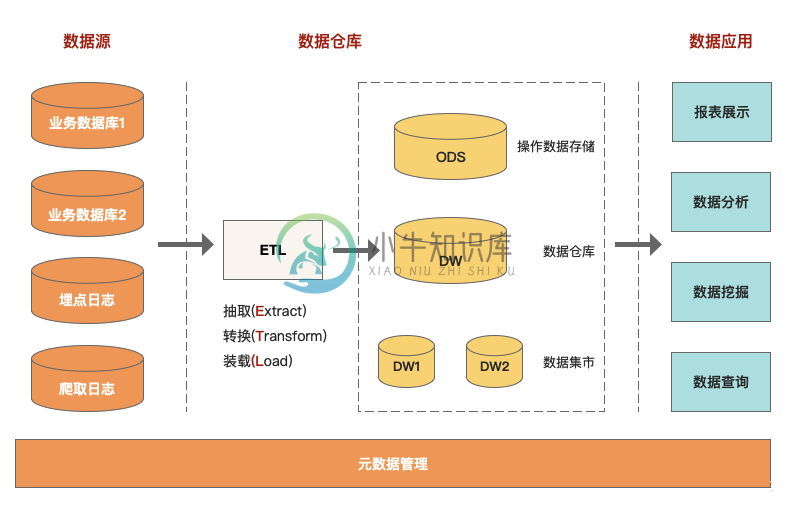 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
 滴滴-国际化数据部-大数据开发面经
滴滴-国际化数据部-大数据开发面经2023春招找实习的同学跟我分享了他的面试经历,在这里我进行了一些总结梳理,然后发出来供大家学习 注意这是日常实习!!! 1.自我介绍 2.刷题 冒泡排序 3.八股文 3.1 JVM JVM的内存结构 类的加载过程 静态代码块和代码块初始化的顺序,以及静态代码块在哪个阶段被加载【初始化】 垃圾回收器 一个方法报错了,怎么进行分析,比如A方法调用B方法,B方法调用C方法....【没太懂】 3.2 并
-
 博观大数据(数据分析岗位一面面经)
博观大数据(数据分析岗位一面面经)1.自我介绍; 2.有做过落地的实际项目没; 3.介绍一下xgboost与GBDT的关系; 4.介绍一下常用的聚类算法(K-means); 5.了解NLP吗,介绍一下BERT的结构(模型结构、任务); 6.如何缓解数据稀疏、冷启动等问题; 7.反问(主要做什么业务,具体需要使用哪些算法); 8.总结:面试过程简单,没有算法题,一面过了就说线下走流程,已拒绝;
-
从Redis检索大型数据集
问题内容: 一台服务器上的应用程序查询在另一台服务器上运行的redis。来自查询的结果数据集大约为25万,在应用服务器上似乎需要40秒。 在redis服务器或app服务器上使用命令执行命令时,在两种情况下,它们都需要大约40秒才能完成,如所述。 在查询期间,redis服务器使用大约15%的CPU。 问题: 花费40秒检索250k记录是否很慢?是否有可能将其加速到几秒钟? 问题答案: 首先,它取决于
-
使用JList显示大量数据?
问题内容: 我有一个JList,必须显示3000多个项目。我希望列表中有100个左右的“可见”项,并且当您滚动并接近“可见”项的末尾(或开头)时,必须在列表中加载下一部分(约50个)。有没有简单的方法可以做到这一点? 问题答案: 不,没有简单的方法,您必须实现分页 由数据库引擎管理时最简单的工作,然后大多数直接支持分页 在模型中,但是我从未见过XxxListModel的解决方法,而是将JTable
-
数据协议URL大小限制
问题内容: “数据:” URL方案值是否有大小限制?我对流行的Web浏览器中的限制感兴趣。换句话说,多久可以成为或? 问题答案: 简短答案:数据URI限制有所不同。 有很多答案。正如5年前提出的问题一样,大多数问题由于过时而现在不正确,但是这个问题排在Google结果“数据URI限制”的顶部。数据URI现在得到广泛支持,并且IE 7/8不再是相关的浏览器。下面有许多参考文献,因为今天的答案是微妙的
-
mysql批量删除大量数据
本文向大家介绍mysql批量删除大量数据,包括了mysql批量删除大量数据的使用技巧和注意事项,需要的朋友参考一下 mysql批量删除大量数据 假设有一个表(syslogs)有1000万条记录,需要在业务不停止的情况下删除其中statusid=1的所有记录,差不多有600万条, 直接执行 DELETE FROM syslogs WHERE statusid=1 会发现删除失败,因为lock wai
-
使用OpenNLP训练大数据集
我有文件及其非常大的文件说100MB文件。我想执行NER以提取组织名称。我使用OpenNLP进行了培训。 示例代码: 但是我得到了一个错误:。 有没有办法使用openNLP for NER来训练大型数据集?你能发布示例代码吗? 当我谷歌时,我发现Class GIS和DataIndexer界面可用于训练大型数据集,但我知道如何训练?你能发布示例代码吗?
-
选择SQL Server数据库大小
如何查询我的sql server以仅获取数据库的大小? 我用了这个: 我得到了这个: 它返回我几个列,我不需要,也许有一个技巧,从这个存储过程中选择database_size列? 我还尝试了这段代码: 它给了我这个结果: 所以我写了这个: 我得到:1183 所以它是有效的,但也许有一个合适的方法来得到这个?
-
Android.os.TransactionToolargeException:数据包大小565156字节
我有fragmens的viewpager,在这么多卷轴应用程序崩溃后,说翻边,甚至他们是没有捆绑交换 在监视的时候,我发现下面的钥匙造成了碰撞 这些都是有缺陷的,我没有分配任何捆绑我如何可以解决这个问题。
-
为大数据生成最佳UUID
“...如果这不可行,RFC4122建议使用命名空间变体,如类型5 UUID。” 我计划使用Java生成UUID,并引用了API https://docs.oracle.com/javase/8/docs/API/Java/util/UUID.html 通过维基百科: