《神策数据笔试》专题
-
Chapter 3.神经网络基础组件
本章通过介绍构建神经网络的基本思想,如激活函数、损失函数、优化器和监督训练设置,为后面的章节奠定了基础。我们从感知器开始,这是一个将不同概念联系在一起的一个单元的神经网络。感知器本身是更复杂的神经网络的组成部分。这是一种贯穿全书的常见模式,我们讨论的每个架构或网络都可以单独使用,也可以在其他复杂的网络中组合使用。当我们讨论计算图形和本书的其余部分时,这种组合性将变得清晰起来。 Perceptron
-
训练神经网络(Training a Neural Network)
我们现在将学习如何训练神经网络。 我们还将学习Python深度学习中的反向传播算法和反向传递。 我们必须找到神经网络权重的最佳值,以获得所需的输出。 为了训练神经网络,我们使用迭代梯度下降法。 我们最初从权重的随机初始化开始。 在随机初始化之后,我们使用前向传播过程对数据的某个子集进行预测,计算相应的成本函数C,并将每个权重w更新为与dC/dw成比例的量,即成本函数的导数。重量。 比例常数称为学习
-
2.13. 神经网络模型(无监督)
校验者: @不将就 翻译者: @夜神月 2.13.1. 限制波尔兹曼机 Restricted Boltzmann machines (RBM)(限制玻尔兹曼机)是基于概率模型的无监督非线性特征学习器。当用 RBM 或 RBMs 中的层次结构提取的特征在馈入线性分类器(如线性支持向量机或感知机)时通常会获得良好的结果。 该模型对输入的分布作出假设。目前,scikit-learn 只提供了 Berno
-
1.17. 神经网络模型(有监督)
校验者: @tiantian1412 @火星 翻译者: @A Warning 此实现不适用于大规模数据应用。 特别是 scikit-learn 不支持 GPU。如果想要提高运行速度并使用基于 GPU 的实现以及为构建深度学习架构提供更多灵活性的框架,请参阅 Related Projects 。 1.17.1. 多层感知器 多层感知器(MLP) 是一种监督学习算法,通过在数据集上训练来学习函数 ,其
-
4 神经网络和深度学习
深度神经网络的工作地点、原因和方式。从大脑中获取灵感。卷积神经网络(CNN)和循环神经网络(RNN)。真实世界中的应用。 使用深度学习,我们仍然是习得一个函数f,将输入X映射为输出Y,并使测试数据上的损失最小,就像我们之前那样。回忆一下,在 2.1 节监督学习中,我们的初始“问题陈述”: Y = f(X) + ϵ 训练:机器从带标签的训练数据习得f 测试:机器从不带标签的测试数据预测Y 真实世界很
-
神经元扩展模块Python接口
dc_motor_driver --- 双直流电机驱动模块 功能相关函数 dc_motor_driver.set_power(speed, ch = 0) 设置双路直流电机各路电机的动力,参数: speed 控制目标电机的动力值,参数范围是 -100 ~ 100。 ch 控制的电机通道,参数范围是 0 ~ 2,其中 0 表示两路电机通道,1 表示插槽1通道,2 表示插槽2通道。 程序示例 impo
-
后端 - 神奇的xhell,无法连接???
神奇的错误,远程ecs可以连接,本地centos7连接不上, 检查了ssh以及端口是否开放,ping和联网也正常,密码也重置了,就是连接不上,这xshell还能要吗? 发现是好像是防火墙问题?但我明明开放了端口,但主机就连接端口显示失败?
-
 原神梦碎了一地😭😭😭
原神梦碎了一地😭😭😭我的米啊! #米哈游# #实习,投递多份简历没人回复怎么办# #正在实习的碎碎念# #简历被挂麻了,求建议#
-
 淘天八股文,求大神指点
淘天八股文,求大神指点这次面试也并非完全没有收获,除去开头的自我吹嘘和末尾的无效笔试,中间的八股文还是结结实实的硬知识,反问环节也确实了解了目前前端的情况。 八股文过程中,涉及到了计算机网络(各代 HTTP 的区别、常见状态码、输入 URL 访问网站过程)、计算机组成原理、JS 语法(如何判断 NaN、各种空的比较、var 和 let 的区别)、requestAnimationFrame 的用处、new 的过程、cal
-
单元测试反向传播神经网络代码
我正在从头开始编写一个backprop神经网络迷你库,我需要一些帮助来编写有意义的自动测试。到目前为止,我已经进行了自动化测试,以验证backprop算法是否正确计算了权重和偏差梯度,但没有测试训练本身是否有效。 到目前为止,我使用的代码可以执行以下操作: 定义一个具有任意层数和每层神经元数的神经网络 鉴于所有这些,我可以编写什么样的自动化测试来确保训练算法被正确实施。我应该尝试近似什么函数(si
-
 神州信息实习面试?我要校招面试
神州信息实习面试?我要校招面试昨天突然收到了神州信息的面试通知,我都快忘了神州信息,好像是之前投的,记得做笔试。一直以为是秋招,我**一看邮件通知是:2024届实习-Java开发工程师面试,我**我一直以为是校招,因为目前我也有在实习的,目标是找个好一点的公司校招上岸,想着积累下面试经验也行,就请假参加了线上面试。就刚刚面试完,也没问啥,面试了15minutes,后面问了下,就一面,一周内出结果,到时候会有个测评。下面就总结下
-
休眠缓存策略
问题内容: 我该如何决定使用哪个? , , , 。 我阅读了https://www.hibernate.org/hib_docs/v3/api/org/hibernate/cache/CacheConcurrencyStrategy.html,但没有足够详细地解释。 问题答案: 在Hibernate文档确实在他们定义了很好的工作: 19.2.2。策略:只读 如果您的应用程序需要读取而不是修改持久类
-
了解缓冲策略
问题内容: 我是Java的新手。我想做一个游戏。经过大量研究,我不了解缓冲策略的工作原理。.我了解基础知识..它创建了一个屏幕外图像,您以后可以将其放入Windows对象中。 我不知道..我已经研究了很长时间了..根本没有运气..我不知道..也许所有的东西都在里面,而且它很清楚很简单,我我太愚蠢而看不见.. 感谢所有的帮助.. :) 问题答案: 运作方式如下: 该构造了一个当你调用。该知道它属于那
-
 Selenium WebDriver-定位策略
Selenium WebDriver-定位策略与Selenium IDE一样,WebDriver使用相同的定位策略集来指定特定Web元素的位置。 因为,正在使用带有Java的WebDriver; 每个定位策略在Java中都有自己的命令来定位Web元素。 注意 :在和方法的帮助下,在Webdriver中定位Web元素。 WebDriver中使用的定位策略列表: 按ID定位策略 按名称查找策略 按类名定位策略 按标签名称定位策略 通过链接文本定位
-
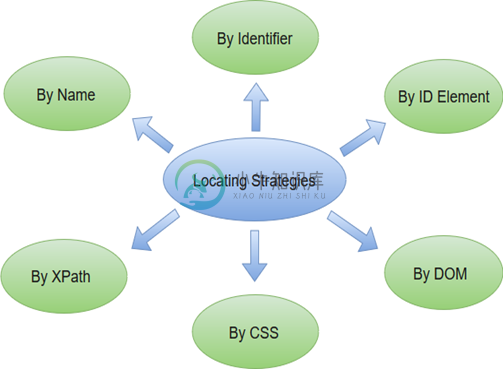 Selenium IDE定位策略
Selenium IDE定位策略对于大多数Selenium命令,都需要一个目标位置,该位置在Web应用程序的上下文中唯一地定义Web元素。 目标由定位策略组成,其格式如下: 在Selenium IDE中,目标使用六种指定特定Web元素位置的模式: 按标识符定位 按ID元素定位 按名称查找 通过XPath定位 通过CSS定位 按DOM定位 在详细介绍每种模式之前,读者应该精通HTML和CSS。